 NEWSLETTER
NEWSLETTER
Esta es una publicación invitada de José Benítez, fundador y director de ai y Mattias Ponchon, jefe de infraestructura de Intuitivo.
Intuitivo, pionero en innovación minorista, está revolucionando las compras con su sistema de procesamiento transaccional de inteligencia artificial y aprendizaje automático (ai/ML) basado en la nube. Esta tecnología innovadora nos permite operar millones de puntos de compra autónomos (A-POP) simultáneamente, transformando la forma en que los clientes compran. Nuestra solución supera a las máquinas expendedoras tradicionales y a sus alternativas, ofreciendo una ventaja económica con un costo diez veces más económico, una configuración sencilla y un funcionamiento sin mantenimiento. Nuestros nuevos e innovadores A-POP (o máquinas expendedoras) ofrecen experiencias de cliente mejoradas a un costo diez veces menor debido a las ventajas de rendimiento y costos que ofrece AWS Inferentia. Inferentia nos ha permitido ejecutar nuestros modelos de visión por computadora You Only Look Once (YOLO) cinco veces más rápido que nuestra solución anterior y respalda experiencias de compra fluidas y en tiempo real para nuestros clientes. Además, Inferentia también nos ha ayudado a reducir los costos en un 95 por ciento en comparación con nuestra solución anterior. En esta publicación, cubrimos nuestro caso de uso, desafíos y una breve descripción general de nuestra solución usando Inferentia.
El cambiante panorama minorista y la necesidad de A-POP
El panorama minorista está evolucionando rápidamente y los consumidores esperan las mismas experiencias fáciles de usar y sin fricciones a las que están acostumbrados cuando compran digitalmente. Para cerrar eficazmente la brecha entre el mundo digital y físico y satisfacer las necesidades y expectativas cambiantes de los clientes, se requiere un enfoque transformador. En Intuitivo, creemos que el futuro del comercio minorista radica en la creación de puntos de compra autónomos (A-POP) altamente personalizados, impulsados por inteligencia artificial y visión por computadora. Esta innovación tecnológica pone los productos al alcance de los clientes. No sólo pone a su alcance los artículos favoritos de los clientes, sino que también les ofrece una experiencia de compra fluida, sin largas colas ni complejos sistemas de procesamiento de transacciones. Estamos entusiasmados de liderar esta nueva y emocionante era en el comercio minorista.
Con nuestra tecnología de vanguardia, los minoristas pueden implementar de manera rápida y eficiente miles de A-POP. El escalamiento siempre ha sido un desafío abrumador para los minoristas, principalmente debido a las complejidades logísticas y de mantenimiento asociadas con la expansión de las máquinas expendedoras tradicionales u otras soluciones. Sin embargo, nuestra solución basada en cámaras, que elimina la necesidad de sensores de peso, RFID u otros sensores de alto costo, no requiere mantenimiento y es significativamente más económica. Esto permite a los minoristas establecer de manera eficiente miles de A-POP, brindando a los clientes una experiencia de compra inigualable y al mismo tiempo ofrecer a los minoristas una solución rentable y escalable.
Uso de la inferencia en la nube para la identificación de productos en tiempo real
Al diseñar un sistema de pago y reconocimiento de productos basado en una cámara, nos topamos con la decisión de si esto debería hacerse en el borde o en la nube. Después de considerar varias arquitecturas, diseñamos un sistema que sube videos de las transacciones a la nube para su procesamiento.
Nuestros usuarios finales inician una transacción escaneando el código QR del A-POP, lo que activa el desbloqueo del A-POP y luego los clientes toman lo que quieren y se van. Los videos preprocesados de estas transacciones se cargan en la nube. Nuestro canal de transacciones impulsado por IA procesa automáticamente estos videos y carga la cuenta del cliente en consecuencia.
El siguiente diagrama muestra la arquitectura de nuestra solución.
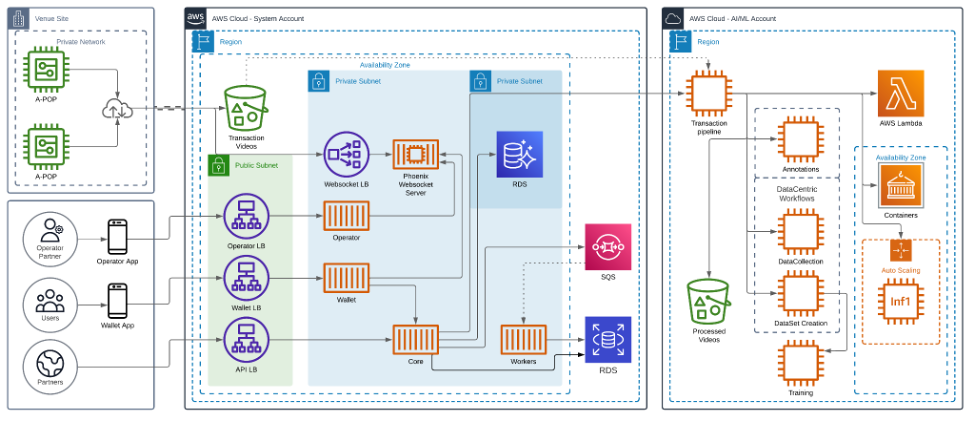
Cómo desbloquear inferencias rentables y de alto rendimiento mediante AWS Inferentia
A medida que los minoristas buscan ampliar sus operaciones, el costo de los A-POP se convierte en una consideración. Al mismo tiempo, es primordial brindar una experiencia de compra fluida en tiempo real a los usuarios finales. Nuestro equipo de investigación de ai/ML se centra en identificar los mejores modelos de visión por computadora (CV) para nuestro sistema. Ahora se nos presentó el desafío de cómo optimizar simultáneamente las operaciones de IA/ML en términos de rendimiento y costo.
Implementamos nuestros modelos en instancias Amazon EC2 Inf1 impulsadas por Inferentia, el primer silicio de aprendizaje automático de Amazon diseñado para acelerar las cargas de trabajo de inferencia de aprendizaje profundo. Se ha demostrado que Inferentia reduce significativamente los costos de inferencia. Utilizamos AWS Neuron SDK, un conjunto de herramientas de software utilizadas con Inferentia, para compilar y optimizar nuestros modelos para su implementación en instancias EC2 Inf1.
El fragmento de código que sigue muestra cómo compilar un modelo YOLO con Neuron. El código funciona perfectamente con PyTorch y funciones como torch.jit.trace() y neuron.trace() registran las operaciones del modelo en una entrada de ejemplo durante el paso hacia adelante para construir un gráfico IR estático.
Migramos nuestros modelos con gran capacidad informática a Inf1. Al utilizar AWS Inferentia, logramos el rendimiento y el rendimiento necesarios para satisfacer nuestras necesidades comerciales. La adopción de instancias Inf1 basadas en Inferentia en el ciclo de vida de MLOps fue clave para lograr resultados notables:
- Mejora del rendimiento: Nuestros grandes modelos de visión por computadora ahora funcionan cinco veces más rápido y alcanzan más de 120 fotogramas por segundo (FPS), lo que permite a nuestros clientes experiencias de compra fluidas y en tiempo real. Además, la capacidad de procesar a esta velocidad de fotogramas no solo mejora la velocidad de las transacciones, sino que también nos permite introducir más información en nuestros modelos. Este aumento en la entrada de datos mejora significativamente la precisión de la detección de productos dentro de nuestros modelos, lo que aumenta aún más la eficacia general de nuestros sistemas de compras.
- Ahorro de costes: Recortamos los costos de inferencia. Esto mejoró significativamente el diseño de la arquitectura que respalda nuestros A-POP.
La inferencia paralela de datos fue fácil con AWS Neuron SDK
Para mejorar el rendimiento de nuestras cargas de trabajo de inferencia y extraer el máximo rendimiento de Inferentia, queríamos utilizar todos los NeuronCores disponibles en el acelerador de Inferentia. Lograr este rendimiento fue fácil con las herramientas y API integradas del SDK de Neuron. Usamos el torch.neuron.DataParallel() API. Actualmente estamos usando inf1.2xlarge que tiene un acelerador Inferentia con cuatro aceleradores Neuron. Entonces estamos usando torch.neuron.DataParallel() utilizar completamente el hardware de Inferentia y utilizar todos los NeuronCores disponibles. Esta función de Python implementa el paralelismo de datos a nivel de módulo en modelos creados por la API PyTorch Neuron. El paralelismo de datos es una forma de paralelización entre múltiples dispositivos o núcleos (NeuronCores para Inferentia), denominados nodos. Cada nodo contiene el mismo modelo y parámetros, pero los datos se distribuyen entre los diferentes nodos. Al distribuir los datos entre múltiples nodos, el paralelismo de datos reduce el tiempo total de procesamiento de entradas de lotes grandes en comparación con el procesamiento secuencial. El paralelismo de datos funciona mejor para modelos en aplicaciones sensibles a la latencia que tienen requisitos de lotes grandes.
De cara al futuro: acelerar la transformación del comercio minorista con modelos básicos e implementación escalable
A medida que nos aventuramos hacia el futuro, no se puede subestimar el impacto de los modelos básicos en la industria minorista. Los modelos de base pueden marcar una diferencia significativa en el etiquetado de productos. La capacidad de identificar y categorizar diferentes productos de forma rápida y precisa es crucial en un entorno minorista acelerado. Con los modelos modernos basados en transformadores, podemos implementar una mayor diversidad de modelos para satisfacer más necesidades de IA/ML con mayor precisión, mejorando la experiencia de los usuarios y sin tener que perder tiempo y dinero entrenando modelos desde cero. Aprovechando el poder de los modelos básicos, podemos acelerar el proceso de etiquetado, permitiendo a los minoristas escalar sus soluciones A-POP de manera más rápida y eficiente.
Hemos comenzado a implementar Segmentar cualquier modelo (SAM), un modelo básico de transformador de visión que puede segmentar cualquier objeto en cualquier imagen (analizaremos esto más a fondo en otra publicación de blog). SAM nos permite acelerar nuestro proceso de etiquetado con una velocidad incomparable. SAM es muy eficiente y puede procesar aproximadamente 62 veces más imágenes de las que un humano puede crear manualmente cuadros delimitadores en el mismo período de tiempo. El resultado de SAM se utiliza para entrenar un modelo que detecta máscaras de segmentación en transacciones, lo que abre una ventana de oportunidad para procesar millones de imágenes exponencialmente más rápido. Esto reduce significativamente el tiempo y el costo de capacitación para los modelos de planograma de productos.

Nuestros equipos de investigación de productos y ai/ML están entusiasmados de estar a la vanguardia de esta transformación. La asociación actual con AWS y nuestro uso de Inferentia en nuestra infraestructura garantizarán que podamos implementar estos modelos básicos de manera rentable. Como primeros usuarios, estamos trabajando con las nuevas instancias basadas en AWS Inferentia 2. Las instancias Inf2 están diseñadas para la IA generativa actual y la aceleración de inferencia de modelos de lenguaje grande (LLM), lo que ofrece mayor rendimiento y menores costos. Inf2 nos permitirá capacitar a los minoristas para que aprovechen los beneficios de las tecnologías impulsadas por la IA sin tener que gastar mucho dinero, lo que en última instancia hará que el panorama minorista sea más innovador, eficiente y centrado en el cliente.
A medida que continuamos migrando más modelos a Inferentia e Inferentia2, incluidos los modelos fundamentales basados en transformadores, confiamos en que nuestra alianza con AWS nos permitirá crecer e innovar junto con nuestro proveedor de nube de confianza. Juntos, remodelaremos el futuro del comercio minorista, haciéndolo más inteligente, más rápido y más acorde con las necesidades en constante evolución de los consumidores.
Conclusión
En este recorrido técnico, hemos destacado nuestro viaje transformacional utilizando AWS Inferentia para su innovador sistema de procesamiento transaccional ai/ML. Esta asociación ha dado lugar a un aumento cinco veces mayor en la velocidad de procesamiento y una impresionante reducción del 95 por ciento en los costos de inferencia en comparación con nuestra solución anterior. Ha cambiado el enfoque actual de la industria minorista al facilitar una experiencia de compra fluida y en tiempo real.
Si está interesado en obtener más información sobre cómo Inferentia puede ayudarle a ahorrar costos mientras optimiza el rendimiento de sus aplicaciones de inferencia, visite las páginas de productos de instancias Amazon EC2 Inf1 e instancias Amazon EC2 Inf2. AWS proporciona varios códigos de muestra y recursos de introducción para Neuron SDK que puede encontrar en Repositorio de muestras de neuronas.
Sobre los autores
Matías Ponchón es el Jefe de Infraestructura de Intuitivo. Se especializa en diseñar aplicaciones seguras y robustas. Su amplia experiencia en empresas FinTech y Blockchain, sumado a su mentalidad estratégica, le ayuda a diseñar soluciones innovadoras. Tiene un profundo compromiso con la excelencia, por eso ofrece constantemente soluciones resilientes que traspasan los límites de lo posible.
Jose Benitez es el fundador y director de IA en Intuitivo, especializado en el desarrollo e implementación de aplicaciones de visión por computadora. Dirige un talentoso equipo de aprendizaje automático, que fomenta un entorno de innovación, creatividad y tecnología de vanguardia. En 2022, José fue reconocido como “Innovador menor de 35 años” por MIT technology Review, un testimonio de sus innovadoras contribuciones en este campo. Esta dedicación se extiende más allá de los elogios y se extiende a cada proyecto que emprende, mostrando un compromiso incesante con la excelencia y la innovación.
Bansal Diwakar es un especialista sénior de AWS centrado en el desarrollo empresarial y la comercialización de servicios informáticos acelerados de Gen ai y Machine Learning. Anteriormente, Diwakar dirigió la definición de productos, el desarrollo comercial global y la comercialización de productos tecnológicos para IoT, Edge Computing y conducción autónoma, centrándose en llevar la IA y el aprendizaje automático a estos dominios.





{kind=link}