 NEWSLETTER
NEWSLETTER

Image by author
Abu Dhabi's technology Innovation Institute (TII) launched its next series of Falcon language models on May 14. The new models align with TII's mission as technology enablers and are available as open source models on HuggingFace. They launched two variants of the Falcon 2 models: Falcon-2-11B and Falcon-2-11B-VLM. The new VLM model promises exceptional multi-model supports that work on par with other open and closed source models.
Model features and performance
The recent Falcon-2 language model has 11 billion parameters and is trained on 5.5 trillion tokens from the falcon-refinedweb data set. The newer, more efficient models compete well with Meta's recent Llama3 model with 8 billion parameters. The results are summarized in the following table shared by TII:
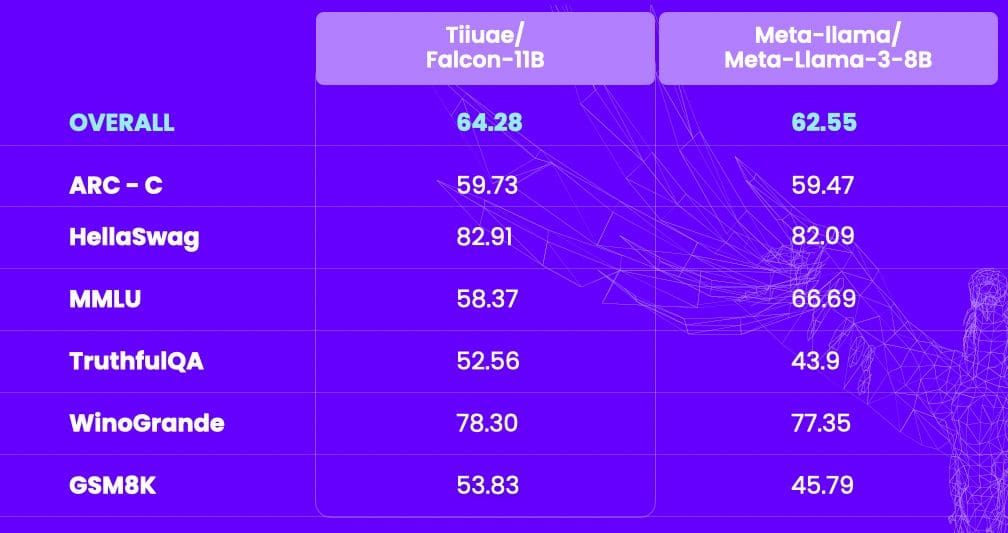
Image by TII
Furthermore, the Falcon-2 model obtains good results against Google's Gemma with 7 billion parameters. Gemma-7B exceeds the average performance of the Falcon-2 by only 0.01. Additionally, the model is multilingual and trained in commonly used languages, including English, French, Spanish, and German, among others.
However, the groundbreaking achievement is the launch of the Falcon-2-11B vision language model that adds image understanding and multimodularity to the same language model. Image-to-text conversation capability with capabilities comparable to recent models like the Llama3 and Gemma is a significant advancement.
How to use models for inference
Let's move on to the coding part so we can run the model on our local system and generate responses. First, like any other project, let's set up a new environment to avoid dependency conflicts. Since the model was recently released, we will need the latest versions of all libraries to avoid losing support and pipelines.
Create a new Python virtual environment and activate it using the following commands:
python -m venv venv
source venv/bin/activateNow that we have a clean environment, we can install our necessary libraries and dependencies using the Python package manager. For this project, we will use images available on the internet and load them into Python. Requests and the Pillow library are suitable for this purpose. Additionally, to load the model, we will use the transformer library which has internal support for HuggingFace model loading and inference. We will use bitsandbytes, PyTorch, and speedup as a model loading and quantization utility.
To make the configuration process easier, we can create a simple requirements text file as follows:
# requirements.txt
accelerate # For distributed loading
bitsandbytes # For Quantization
torch # Used by HuggingFace
transformers # To load pipelines and models
Pillow # Basic Loading and Image Processing
requests # Downloading image from URL
Now we can install all the dependencies in a single line using:
pip install -r requirements.txtNow we can start working on our code to use the model for inference. Let's start by loading the model on our local system. The model is available in HugsFace and the total size exceeds 20 GB of memory. We cannot load the model on consumer GPUs which typically have between 8 and 16 GB of RAM. Therefore, we will need to quantize the model, that is, we will load the model in 4-bit floating point numbers instead of the usual 32-bit precision to decrease memory requirements.
The bitsandbytes library provides a simple interface for quantizing large language models in HuggingFace. We can initialize a quantization configuration that can be passed to the model. HuggingFace handles all required operations internally and sets the correct accuracy and settings for us. The configuration can be set as follows:
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
# Original model support BFloat16
bnb_4bit_compute_dtype=torch.bfloat16,
)
This allows the model to fit under 16 GB of GPU RAM, making it easy to load the model without downloading or distributing it. Now we can load the Falcon-2B-VLM. Being a multimodal model, we will handle images along with textual indications. The LLava model and pipelines are designed for this purpose, as they allow CLIP-based image embeddings to be projected onto language model inputs. The transformer library has integrated Llava model processors and pipelines. Then we can load the model as follows:
from transformers import LlavaNextForConditionalGeneration, LlavaNextProcessor
processor = LlavaNextProcessor.from_pretrained(
"tiiuae/falcon-11B-vlm",
tokenizer_class="PreTrainedTokenizerFast"
)
model = LlavaNextForConditionalGeneration.from_pretrained(
"tiiuae/falcon-11B-vlm",
quantization_config=quantization_config,
device_map="auto"
)
We pass the model URL of the HuggingFace model card to the processor and generator. We also pass the bitsandbytes quantization settings to the generative model, so it will be automatically loaded with 4-bit precision.
Now we can start using the model to generate answers! To explore the multimodal nature of Falcon-11B, we will need to upload an image in Python. For a test sample, let's upload this available standard image here. To load an image from a web URL, we can use the Pillow library and requests as shown below:
from Pillow import Image
import requests
url = "https://static.theprint.in/wp-content/uploads/2020/07/football.jpg"
img = Image.open(requests.get(url, stream=True).raw)The request library downloads the image from the URL and the Pillow library can read the image from bytes to a standard image format. Now that we can have our test image, we can now generate a sample response from our model.
Let's set up a sample message template that the model is sensitive to.
instruction = "Write a long paragraph about this picture."
prompt = f"""User:\n{instruction} Falcon:"""The notice template itself is self-explanatory and we need to follow it to get the best responses from the VLM. We pass the notice and the image to the Llamava image processor. It uses CLIP internally to create a combined embed of the image and message.
inputs = processor(
prompt,
images=img,
return_tensors="pt",
padding=True
).to('cuda:0')
The returned tensor embedding acts as input to the generative model. We pass the embeddings and the transformer-based Falcon-11B model generates a textual response based on the image and instructions originally provided.
We can generate the response using the following code:
output = model.generate(**inputs, max_new_tokens=256)
generated_captions = processor.decode(output(0), skip_special_tokens=True).strip()There we have it! The generate_captions variable is a string containing the response generated by the model.
Results
We tested several images using the code above and the responses for some of them are summarized in this image below. We see that the Falcon-2 model has great image understanding and generates readable responses to show its understanding of the scenarios in the images. It can read text and also highlights global information as a whole. In summary, the model has excellent capabilities for visual tasks and can be used for image-based conversations.

Author's image | Internet inference images. Sources: Cats image, card image, football image
License and Compliance
In addition to being open source, the models are released under the Apache2.0 license, making them available for open access. This allows modification and distribution of the model for personal and commercial uses. This means you can now use Falcon-2 models to power your LLM-based applications and open source models to provide multimodal capabilities to your users.
Ending
In general, the new Falcon-2 models show promising results. But that is not all! TII is already working on the next version to boost performance even further. They are looking to integrate Mixture of Experts (MoE) and other machine learning capabilities into their models to improve accuracy and intelligence. If Falcon-2 seems like an improvement, get ready for its next announcement.
Kanwal Mehreen Kanwal is a machine learning engineer and technical writer with a deep passion for data science and the intersection of ai with medicine. She is the co-author of the eBook “Maximize Productivity with ChatGPT.” As a Google Generation Scholar 2022 for APAC, she champions diversity and academic excellence. She is also recognized as a Teradata Diversity in tech Scholar, Mitacs Globalink Research Scholar, and Harvard WeCode Scholar. Kanwal is a passionate advocate for change and founded FEMCodes to empower women in STEM fields.






{kind=link}