 NEWSLETTER
NEWSLETTER
Las incorporaciones desempeñan un papel clave en el procesamiento del lenguaje natural (NLP) y el aprendizaje automático (ML). Incrustación de texto se refiere al proceso de transformar texto en representaciones numéricas que residen en un espacio vectorial de alta dimensión. Esta técnica se logra mediante el uso de algoritmos de ML que permiten la comprensión del significado y el contexto de los datos (relaciones semánticas) y el aprendizaje de relaciones y patrones complejos dentro de los datos (relaciones sintácticas). Puede utilizar las representaciones vectoriales resultantes para una amplia gama de aplicaciones, como recuperación de información, clasificación de texto, procesamiento de lenguaje natural y muchas otras.
Amazon Titan Text Embeddings es un modelo de incrustación de texto que convierte texto en lenguaje natural (que consta de palabras individuales, frases o incluso documentos grandes) en representaciones numéricas que se pueden utilizar para potenciar casos de uso como la búsqueda, la personalización y la agrupación en función de la similitud semántica. .
En esta publicación, analizamos el modelo de Amazon Titan Text Embeddings, sus características y casos de uso de ejemplo.
Algunos conceptos clave incluyen:
- La representación numérica de texto (vectores) captura la semántica y las relaciones entre palabras.
- Se pueden utilizar incrustaciones enriquecidas para comparar la similitud del texto.
- Las incrustaciones de texto multilingüe pueden identificar el significado en diferentes idiomas
¿Cómo se convierte un fragmento de texto en un vector?
Existen múltiples técnicas para convertir una oración en un vector. Un método popular es utilizar algoritmos de incrustación de palabras, como Word2Vec, GloVe o FastText, y luego agregar las incrustaciones de palabras para formar una representación vectorial a nivel de oración.
Otro enfoque común es utilizar modelos de lenguaje grandes (LLM), como BERT o GPT, que pueden proporcionar incrustaciones contextualizadas para oraciones completas. Estos modelos se basan en arquitecturas de aprendizaje profundo como Transformers, que pueden capturar la información contextual y las relaciones entre las palabras de una oración de manera más efectiva.
¿Por qué necesitamos un modelo de incrustaciones?
Las incrustaciones de vectores son fundamentales para que los LLM comprendan los grados semánticos del lenguaje y también les permiten desempeñarse bien en tareas posteriores de PNL, como el análisis de sentimientos, el reconocimiento de entidades nombradas y la clasificación de texto.
Además de la búsqueda semántica, puede utilizar incrustaciones para aumentar sus indicaciones y obtener resultados más precisos a través de la generación aumentada de recuperación (RAG), pero para utilizarlas, deberá almacenarlas en una base de datos con capacidades vectoriales.
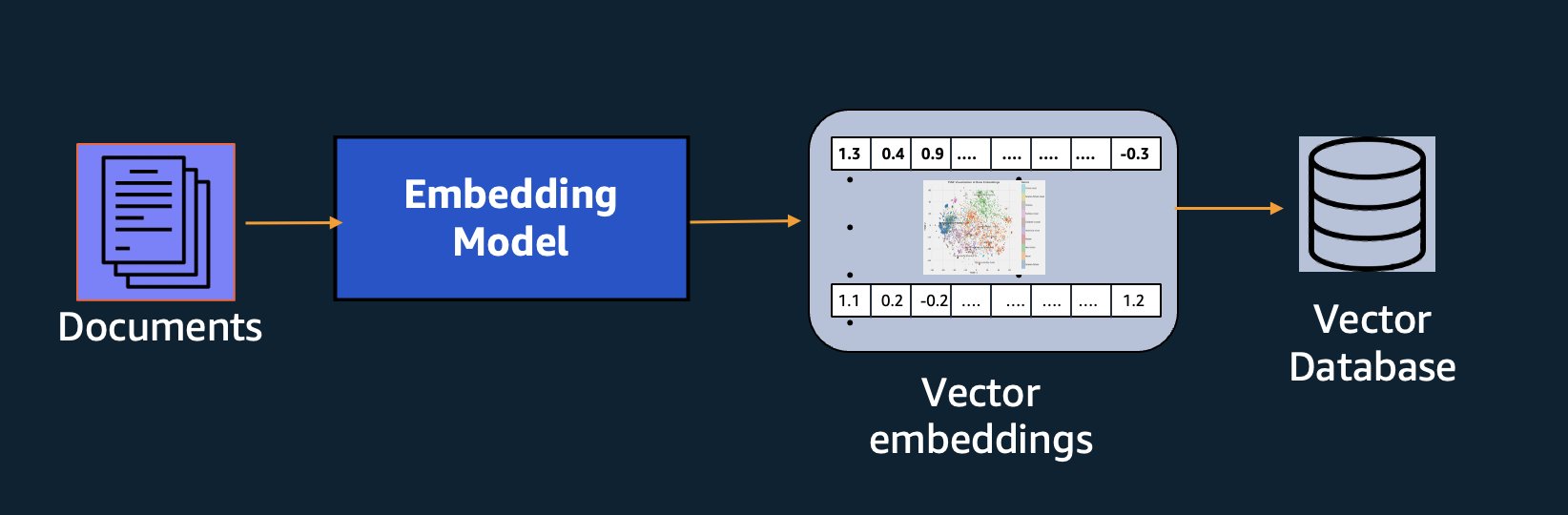
El modelo de Amazon Titan Text Embeddings está optimizado para la recuperación de texto a fin de habilitar casos de uso de RAG. Le permite convertir primero sus datos de texto en representaciones numéricas o vectores, y luego usar esos vectores para buscar con precisión pasajes relevantes de una base de datos vectorial, lo que le permite aprovechar al máximo sus datos patentados en combinación con otros modelos básicos.
Dado que Amazon Titan Text Embeddings es un modelo administrado en Amazon Bedrock, se ofrece como una experiencia completamente sin servidor. Puede usarlo a través de la API REST de Amazon Bedrock o del SDK de AWS. Los parámetros requeridos son el texto cuyas incrustaciones desea generar y el modelID parámetro, que representa el nombre del modelo de Amazon Titan Text Embeddings. El siguiente código es un ejemplo que utiliza AWS SDK para Python (Boto3):
El resultado será similar al siguiente:
Referirse a Configuración de Amazon Bedrock boto3 para obtener más detalles sobre cómo instalar los paquetes necesarios, conectarse a Amazon Bedrock e invocar modelos.
Características de las incrustaciones de texto de Amazon Titan
Con Amazon Titan Text Embeddings, puede ingresar hasta 8000 tokens, lo que lo hace ideal para trabajar con palabras individuales, frases o documentos completos según su caso de uso. Amazon Titan devuelve vectores de salida de dimensión 1536, lo que le otorga un alto grado de precisión y, al mismo tiempo, lo optimiza para obtener resultados rentables y de baja latencia.
Amazon Titan Text Embeddings admite la creación y consulta de incrustaciones de texto en más de 25 idiomas diferentes. Esto significa que puede aplicar el modelo a sus casos de uso sin necesidad de crear y mantener modelos separados para cada idioma que desee admitir.
Tener un único modelo de incorporación entrenado en muchos idiomas proporciona los siguientes beneficios clave:
- Alcance más amplio – Al admitir más de 25 idiomas desde el primer momento, puede ampliar el alcance de sus aplicaciones a usuarios y contenidos en muchos mercados internacionales.
- Rendimiento consistente – Con un modelo unificado que cubre varios idiomas, obtiene resultados consistentes en todos los idiomas en lugar de optimizar por separado por idioma. El modelo se entrena de manera integral para que usted obtenga la ventaja en todos los idiomas.
- Soporte de consultas multilingüe – Amazon Titan Text Embeddings permite consultar incrustaciones de texto en cualquiera de los idiomas admitidos. Esto proporciona flexibilidad para recuperar contenido semánticamente similar en todos los idiomas sin estar restringido a un solo idioma. Puede crear aplicaciones que consulten y analicen datos multilingües utilizando el mismo espacio de incorporación unificado.
Al momento de escribir este artículo, se admiten los siguientes idiomas:
- Arábica
- Chino simplificado)
- Chino tradicional)
- checo
- Holandés
- Inglés
- Francés
- Alemán
- hebreo
- hindi
- italiano
- japonés
- canarés
- coreano
- malayalam
- marathi
- Polaco
- portugués
- ruso
- Español
- sueco
- tagalo filipino
- Tamil
- telugu
- turco
Uso de incrustaciones de texto de Amazon Titan con LangChain
LangChain es un marco popular de código abierto para trabajar con modelos de IA generativa y tecnologías de soporte. Incluye un Cliente BedrockEmbeddings que envuelve convenientemente el SDK de Boto3 con una capa de abstracción. El BedrockEmbeddings El cliente le permite trabajar con texto e incrustaciones directamente, sin conocer los detalles de la solicitud JSON o las estructuras de respuesta. El siguiente es un ejemplo sencillo:
También puedes usar LangChain BedrockEmbeddings junto con el cliente Amazon Bedrock LLM para simplificar la implementación de RAG, búsqueda semántica y otros patrones relacionados con incorporaciones.
Casos de uso para incrustaciones
Aunque RAG es actualmente el caso de uso más popular para trabajar con incrustaciones, existen muchos otros casos de uso en los que se pueden aplicar incrustaciones. Los siguientes son algunos escenarios adicionales en los que puede utilizar incorporaciones para resolver problemas específicos, ya sea por su cuenta o en cooperación con un LLM:
- Pregunta y respuesta – Las incrustaciones pueden ayudar a admitir interfaces de preguntas y respuestas a través del patrón RAG. La generación de incrustaciones junto con una base de datos vectorial le permite encontrar coincidencias cercanas entre preguntas y contenido en un repositorio de conocimientos.
- Recomendaciones personalizadas – De manera similar a las preguntas y respuestas, puede utilizar incrustaciones para buscar destinos de vacaciones, universidades, vehículos u otros productos según los criterios proporcionados por el usuario. Esto podría tomar la forma de una lista simple de coincidencias, o luego podría usar un LLM para procesar cada recomendación y explicar cómo satisface los criterios del usuario. También puede utilizar este enfoque para generar los “10 mejores” artículos personalizados para un usuario en función de sus necesidades específicas.
- Gestión de datos – Cuando tiene fuentes de datos que no se asignan claramente entre sí, pero tiene contenido de texto que describe el registro de datos, puede utilizar incrustaciones para identificar posibles registros duplicados. Por ejemplo, podría utilizar incrustaciones para identificar candidatos duplicados que podrían usar formatos y abreviaturas diferentes o incluso tener nombres traducidos.
- Racionalización de la cartera de aplicaciones – Cuando se busca alinear los portafolios de aplicaciones entre una empresa matriz y una adquisición, no siempre es obvio por dónde empezar a encontrar posibles superposiciones. La calidad de los datos de gestión de la configuración puede ser un factor limitante y puede resultar difícil coordinar entre equipos para comprender el panorama de las aplicaciones. Al utilizar la coincidencia semántica con incrustaciones, podemos realizar un análisis rápido de las carteras de aplicaciones para identificar aplicaciones candidatas de alto potencial para su racionalización.
- Agrupación de contenidos – Puede utilizar incrustaciones para ayudar a facilitar la agrupación de contenido similar en categorías que quizás no conozca de antemano. Por ejemplo, digamos que tiene una colección de correos electrónicos de clientes o reseñas de productos en línea. Puede crear incrustaciones para cada elemento y luego ejecutar esas incrustaciones a través de agrupaciones de k-means para identificar agrupaciones lógicas de inquietudes de los clientes, elogios o quejas de productos u otros temas. Luego, puede generar resúmenes enfocados a partir del contenido de esas agrupaciones utilizando un LLM.
Ejemplo de búsqueda semántica
En nuestro ejemplo en GitHubdemostramos una aplicación de búsqueda de incrustaciones simple con Amazon Titan Text Embeddings, LangChain y Streamlit.
El ejemplo relaciona la consulta de un usuario con las entradas más cercanas en una base de datos vectorial en memoria. Luego mostramos esas coincidencias directamente en la interfaz de usuario. Esto puede resultar útil si desea solucionar problemas de una aplicación RAG o evaluar directamente un modelo de incrustación.
Para simplificar, utilizamos el método en memoria. FAISS Base de datos para almacenar y buscar vectores de incrustaciones. En un escenario del mundo real a escala, probablemente querrá utilizar un almacén de datos persistente como el motor vectorial de Amazon OpenSearch Serverless o el pgvector extensión para PostgreSQL.
Pruebe algunas indicaciones de la aplicación web en diferentes idiomas, como las siguientes:
- ¿Cómo puedo monitorear mi uso?
- ¿Cómo puedo personalizar los modelos?
- ¿Qué lenguajes de programación puedo utilizar?
- ¿Cómo están seguros mis datos?
- ¿Cómo se protegen mis datos?
- ¿Qué proveedores de plantillas están disponibles a través de Bedrock?
- ¿En qué regiones está disponible Amazon Bedrock?
- ¿Qué niveles de soporte están disponibles?
Tenga en cuenta que, aunque el material fuente estaba en inglés, las consultas en otros idiomas se relacionaron con entradas relevantes.
Conclusión
Las capacidades de generación de texto de los modelos básicos son muy interesantes, pero es importante recordar que comprender el texto, encontrar contenido relevante de un conjunto de conocimientos y establecer conexiones entre pasajes son cruciales para lograr el valor total de la IA generativa. Seguiremos viendo surgir nuevos e interesantes casos de uso para incrustaciones en los próximos años a medida que estos modelos sigan mejorando.
Próximos pasos
Puede encontrar ejemplos adicionales de incrustaciones como cuadernos o aplicaciones de demostración en los siguientes talleres:
Sobre los autores
 Jason Stehle es arquitecto de soluciones senior en AWS, con sede en el área de Nueva Inglaterra. Trabaja con los clientes para alinear las capacidades de AWS con sus mayores desafíos comerciales. Fuera del trabajo, pasa su tiempo construyendo cosas y viendo películas de cómics con su familia.
Jason Stehle es arquitecto de soluciones senior en AWS, con sede en el área de Nueva Inglaterra. Trabaja con los clientes para alinear las capacidades de AWS con sus mayores desafíos comerciales. Fuera del trabajo, pasa su tiempo construyendo cosas y viendo películas de cómics con su familia.
 Nitin Eusebio es un arquitecto sénior de soluciones empresariales en AWS, con experiencia en ingeniería de software, arquitectura empresarial e IA/ML. Le apasiona profundamente explorar las posibilidades de la IA generativa. Colabora con los clientes para ayudarlos a crear aplicaciones bien diseñadas en la plataforma AWS y se dedica a resolver desafíos tecnológicos y ayudarlos en su viaje a la nube.
Nitin Eusebio es un arquitecto sénior de soluciones empresariales en AWS, con experiencia en ingeniería de software, arquitectura empresarial e IA/ML. Le apasiona profundamente explorar las posibilidades de la IA generativa. Colabora con los clientes para ayudarlos a crear aplicaciones bien diseñadas en la plataforma AWS y se dedica a resolver desafíos tecnológicos y ayudarlos en su viaje a la nube.
 Raj Pathak es arquitecto principal de soluciones y asesor técnico de grandes empresas Fortune 50 e instituciones de servicios financieros (FSI) medianas en Canadá y Estados Unidos. Se especializa en aplicaciones de aprendizaje automático como IA generativa, procesamiento de lenguaje natural, procesamiento inteligente de documentos y MLOps.
Raj Pathak es arquitecto principal de soluciones y asesor técnico de grandes empresas Fortune 50 e instituciones de servicios financieros (FSI) medianas en Canadá y Estados Unidos. Se especializa en aplicaciones de aprendizaje automático como IA generativa, procesamiento de lenguaje natural, procesamiento inteligente de documentos y MLOps.
 Mani Khanuja es líder tecnológica – Especialistas en IA generativa, autora del libro – Aprendizaje automático aplicado y computación de alto rendimiento en AWS y miembro de la junta directiva de la Junta Directiva de la Fundación de Educación para Mujeres en la Manufactura. Lidera proyectos de aprendizaje automático (ML) en diversos ámbitos, como la visión por computadora, el procesamiento del lenguaje natural y la IA generativa. Ayuda a los clientes a crear, entrenar e implementar grandes modelos de aprendizaje automático a escala. Habla en conferencias internas y externas como re:Invent, Women in Manufacturing West, seminarios web de YouTube y GHC 23. En su tiempo libre, le gusta salir a correr largas distancias por la playa.
Mani Khanuja es líder tecnológica – Especialistas en IA generativa, autora del libro – Aprendizaje automático aplicado y computación de alto rendimiento en AWS y miembro de la junta directiva de la Junta Directiva de la Fundación de Educación para Mujeres en la Manufactura. Lidera proyectos de aprendizaje automático (ML) en diversos ámbitos, como la visión por computadora, el procesamiento del lenguaje natural y la IA generativa. Ayuda a los clientes a crear, entrenar e implementar grandes modelos de aprendizaje automático a escala. Habla en conferencias internas y externas como re:Invent, Women in Manufacturing West, seminarios web de YouTube y GHC 23. En su tiempo libre, le gusta salir a correr largas distancias por la playa.
 Marcos Roy es un arquitecto principal de aprendizaje automático para AWS y ayuda a los clientes a diseñar y crear soluciones de IA/ML. El trabajo de Mark cubre una amplia gama de casos de uso de ML, con un interés principal en la visión por computadora, el aprendizaje profundo y la ampliación del ML en toda la empresa. Ha ayudado a empresas de muchas industrias, incluidas las de seguros, servicios financieros, medios y entretenimiento, atención médica, servicios públicos y manufactura. Mark posee seis certificaciones de AWS, incluida la certificación de especialidad de aprendizaje automático. Antes de unirse a AWS, Mark fue arquitecto, desarrollador y líder tecnológico durante más de 25 años, incluidos 19 años en servicios financieros.
Marcos Roy es un arquitecto principal de aprendizaje automático para AWS y ayuda a los clientes a diseñar y crear soluciones de IA/ML. El trabajo de Mark cubre una amplia gama de casos de uso de ML, con un interés principal en la visión por computadora, el aprendizaje profundo y la ampliación del ML en toda la empresa. Ha ayudado a empresas de muchas industrias, incluidas las de seguros, servicios financieros, medios y entretenimiento, atención médica, servicios públicos y manufactura. Mark posee seis certificaciones de AWS, incluida la certificación de especialidad de aprendizaje automático. Antes de unirse a AWS, Mark fue arquitecto, desarrollador y líder tecnológico durante más de 25 años, incluidos 19 años en servicios financieros.





{kind=link}