 NEWSLETTER
NEWSLETTER
In today’s information age, the vast volumes of data housed in countless documents present both a challenge and an opportunity for businesses. Traditional document processing methods often fall short in efficiency and accuracy, leaving room for innovation, cost-efficiency, and optimizations. Document processing has witnessed significant advancements with the advent of Intelligent Document Processing (IDP). With IDP, businesses can transform unstructured data from various document types into structured, actionable insights, dramatically enhancing efficiency and reducing manual efforts. However, the potential doesn’t end there. By integrating generative artificial intelligence (ai) into the process, we can further enhance IDP capabilities. Generative ai not only introduces enhanced capabilities in document processing, it also introduces a dynamic adaptability to changing data patterns. This post takes you through the synergy of IDP and generative ai, unveiling how they represent the next frontier in document processing.
We discuss IDP in detail in our series Intelligent document processing with AWS ai services (Part 1 and Part 2). In this post, we discuss how to extend a new or existing IDP architecture with large language models (LLMs). More specifically, we discuss how we can integrate Amazon Textract with LangChain as a document loader and Amazon Bedrock to extract data from documents and use generative ai capabilities within the various IDP phases.
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from scanned documents. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) through easy-to-use APIs.
The following diagram is a high-level reference architecture that explains how you can further enhance an IDP workflow with foundation models. You can use LLMs in one or all phases of IDP depending on the use case and desired outcome.
In the following sections, we dive deep into how Amazon Textract is integrated into generative ai workflows using LangChain to process documents for each of these specific tasks. The code blocks provided here have been trimmed down for brevity. Refer to our ai-intelligent-document-processing/tree/main/gen-ai” target=”_blank” rel=”noopener”>GitHub repository for detailed Python notebooks and a step-by-step walkthrough.
Text extraction from documents is a crucial aspect when it comes to processing documents with LLMs. You can use Amazon Textract to extract unstructured raw text from documents and preserve the original semi-structured or structured objects like key-value pairs and tables present in the document. Document packages like healthcare and insurance claims or mortgages consist of complex forms that contain a lot of information across structured, semi-structured, and unstructured formats. Document extraction is an important step here because LLMs benefit from the rich content to generate more accurate and relevant responses, which otherwise could impact the quality of the LLMs’ output.
LangChain is a powerful open-source framework for integrating with LLMs. LLMs in general are versatile but may struggle with domain-specific tasks where deeper context and nuanced responses are needed. LangChain empowers developers in such scenarios to build agents that can break down complex tasks into smaller sub-tasks. The sub-tasks can then introduce context and memory into LLMs by connecting and chaining LLM prompts.
LangChain offers document loaders that can load and transform data from documents. You can use them to structure documents into preferred formats that can be processed by LLMs. The AmazonTextractPDFLoader is a service loader type of document loader that provides quick way to automate document processing by using Amazon Textract in combination with LangChain. For more details on AmazonTextractPDFLoader, refer to the LangChain documentation. To use the Amazon Textract document loader, you start by importing it from the LangChain library:
from langchain.document_loaders import AmazonTextractPDFLoaderhttps_loader = AmazonTextractPDFLoader("https://sample-website.com/sample-doc.pdf")
https_document = https_loader.load()
s3_loader = AmazonTextractPDFLoader("s3://sample-bucket/sample-doc.pdf")
s3_document = s3_loader.load()You can also store documents in Amazon S3 and refer to them using the s3:// URL pattern, as explained in Accessing a bucket using S3://, and pass this S3 path to the Amazon Textract PDF loader:
import boto3
textract_client = boto3.client('textract', region_name="us-east-2")
file_path = "s3://amazon-textract-public-content/langchain/layout-parser-paper.pdf"
loader = AmazonTextractPDFLoader(file_path, client=textract_client)
documents = loader.load()A multi-page document will contain multiple pages of text, which can then be accessed via the documents object, which is a list of pages. The following code loops through the pages in the documents object and prints the document text, which is available via the page_content attribute:
print(len(documents))
for document in documents:
print(document.page_content)Amazon Comprehend and LLMs can be effectively utilized for document classification. Amazon Comprehend is a natural language processing (NLP) service that uses ML to extract insights from text. Amazon Comprehend also supports custom classification model training with layout awareness on documents like PDFs, Word, and image formats. For more information about using the Amazon Comprehend document classifier, refer to Amazon Comprehend document classifier adds layout support for higher accuracy.
When paired with LLMs, document classification becomes a powerful approach for managing large volumes of documents. LLMs are helpful in document classification because they can analyze the text, patterns, and contextual elements in the document using natural language understanding. You can also fine-tune them for specific document classes. When a new document type introduced in the IDP pipeline needs classification, the LLM can process text and categorize the document given a set of classes. The following is a sample code that uses the LangChain document loader powered by Amazon Textract to extract the text from the document and use it for classifying the document. We use the Anthropic Claude v2 model via Amazon Bedrock to perform the classification.
In the following example, we first extract text from a patient discharge report and use an LLM to classify it given a list of three different document types—DISCHARGE_SUMMARY, RECEIPT, and PRESCRIPTION. The following screenshot shows our report.
from langchain.document_loaders import AmazonTextractPDFLoader
from langchain.llms import Bedrock
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
loader = AmazonTextractPDFLoader("./samples/document.png")
document = loader.load()
template = """
Given a list of classes, classify the document into one of these classes. Skip any preamble text and just give the class name.
<classes>DISCHARGE_SUMMARY, RECEIPT, PRESCRIPTION</classes>
<document>{doc_text}<document>
<classification>"""
prompt = PromptTemplate(template=template, input_variables=("doc_text"))
bedrock_llm = Bedrock(client=bedrock, model_id="anthropic.claude-v2")
llm_chain = LLMChain(prompt=prompt, llm=bedrock_llm)
class_name = llm_chain.run(document(0).page_content)
print(f"The provided document is = {class_name}")
Summarization involves condensing a given text or document into a shorter version while retaining its key information. This technique is beneficial for efficient information retrieval, which enables users to quickly grasp the key points of a document without reading the entire content. Although Amazon Textract doesn’t directly perform text summarization, it provides the foundational capabilities of extracting the entire text from documents. This extracted text serves as an input to our LLM model for performing text summarization tasks.
Using the same sample discharge report, we use AmazonTextractPDFLoader to extract text from this document. As before, we use the Claude v2 model via Amazon Bedrock and initialize it with a prompt that contains the instructions on what to do with the text (in this case, summarization). Finally, we run the LLM chain by passing in the extracted text from the document loader. This runs an inference action on the LLM with the prompt that consists of the instructions to summarize, and the document’s text marked by Document. See the following code:
The code generates the summary of a patient discharge summary report:
The preceding example used a single-page document to perform summarization. However, you will likely deal with documents containing multiple pages that need summarization. A common way to perform summarization on multiple pages is to first generate summaries on smaller chunks of text and then combine the smaller summaries to get a final summary of the document. Note that this method requires multiple calls to the LLM. The logic for this can be crafted easily; however, LangChain provides a built-in summarize chain that can summarize large texts (from multi-page documents). The summarization can happen either via map_reduce or with stuff options, which are available as options to manage the multiple calls to the LLM. In the following example, we use map_reduce to summarize a multi-page document. The following figure illustrates our workflow.
Let’s first start by extracting the document and see the total token count per page and the total number of pages:
Next, we use LangChain’s built-in load_summarize_chain to summarize the entire document:
from langchain.chains.summarize import load_summarize_chain
summary_chain = load_summarize_chain(llm=bedrock_llm,
chain_type="map_reduce")
output = summary_chain.run(document)
print(output.strip())Standardization and Q&A
In this section, we discuss standardization and Q&A tasks.
Standardization
Output standardization is a text generation task where LLMs are used to provide a consistent formatting of the output text. This task is particularly useful for automation of key entity extraction that requires the output to be aligned with desired formats. For example, we can follow prompt engineering best practices to fine-tune an LLM to format dates into MM/DD/YYYY format, which may be compatible with a database DATE column. The following code block shows an example of how this is done using an LLM and prompt engineering. Not only do we standardize the output format for the date values, we also prompt the model to generate the final output in a JSON format so that it is easily consumable in our downstream applications. We use LangChain Expression Language (LCEL) to chain together two actions. The first action prompts the LLM to generate a JSON format output of just the dates from the document. The second action takes the JSON output and standardizes the date format. Note that this two-step action may also be performed in a single step with proper prompt engineering, as we’ll see in normalization and templating.
The output of the preceding code sample is a JSON structure with dates 07/09/2020 and 08/09/2020, which are in the format DD/MM/YYYY and are the patient’s admit and discharge date from the hospital, respectively, according to the discharge summary report.
Q&A with Retrieval Augmented Generation
LLMs are known to retain factual information, often referred to as their world knowledge or world view. When fine-tuned, they can produce state-of-the-art results. However, there are constraints to how effectively an LLM can access and manipulate this knowledge. As a result, in tasks that heavily rely on specific knowledge, their performance might not be optimal for certain use cases. For instance, in Q&A scenarios, it’s essential for the model to adhere strictly to the context provided in the document without relying solely on its world knowledge. Deviating from this can lead to misrepresentations, inaccuracies, or even incorrect responses. The most commonly used method to address this problem is known as Retrieval Augmented Generation (RAG). This approach synergizes the strengths of both retrieval models and language models, enhancing the precision and quality of the responses generated.
LLMs can also impose token limitations due to their memory constraints and the limitations of the hardware they run on. To handle this problem, techniques like chunking are used to divide large documents into smaller portions that fit within the token limits of LLMs. On the other hand, embeddings are employed in NLP primarily to capture the semantic meaning of words and their relationships with other words in a high-dimensional space. These embeddings transform words into vectors, allowing models to efficiently process and understand textual data. By understanding the semantic nuances between words and phrases, embeddings enable LLMs to generate coherent and contextually relevant outputs. Note the following key terms:
- Chunking – This process breaks down large amounts of text from documents into smaller, meaningful chunks of text.
- Embeddings – These are fixed-dimensional vector transformations of each chunk that retain the semantic information from the chunks. These embeddings are subsequently loaded into a vector database.
- Vector database – This is a database of word embeddings or vectors that represent the context of words. It acts as a knowledge source that aides NLP tasks in document processing pipelines. The benefit of the vector database here is that is allows only the necessary context to be provided to the LLMs during text generation, as we explain in the following section.
RAG uses the power of embeddings to understand and fetch relevant document segments during the retrieval phase. By doing so, RAG can work within the token limitations of LLMs, ensuring the most pertinent information is selected for generation, resulting in more accurate and contextually relevant outputs.
The following diagram illustrates the integration of these techniques to craft the input to LLMs, enhancing their contextual understanding and enabling more relevant in-context responses. One approach involves similarity search, utilizing both a vector database and chunking. The vector database stores embeddings representing semantic information, and chunking divides text into manageable sections. Using this context from similarity search, LLMs can run tasks such as question answering and domain-specific operations like classification and enrichment.
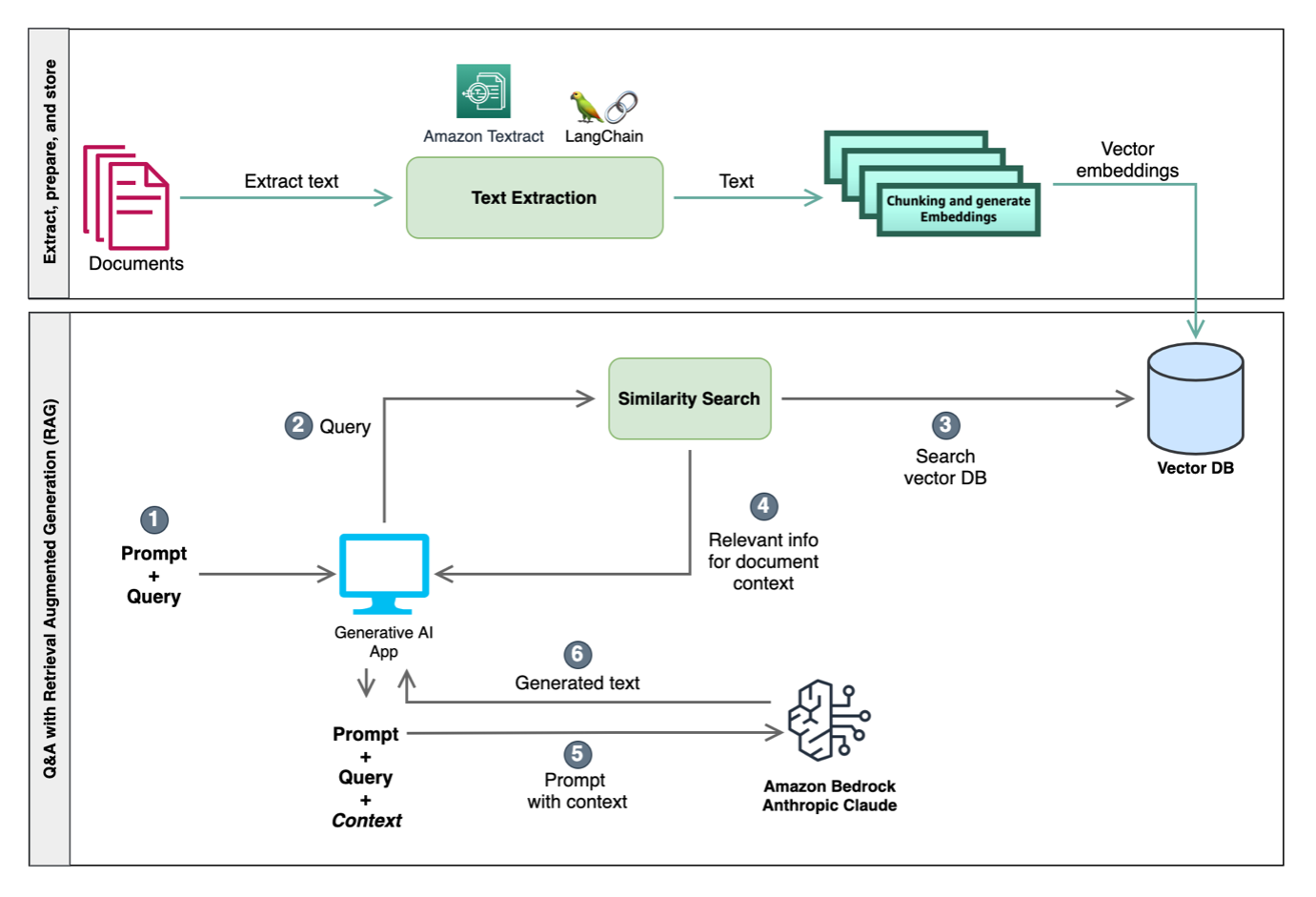
For this post, we use a RAG-based approach to perform in-context Q&A with documents. In the following code sample, we extract text from a document and then split the document into smaller chunks of text. Chunking is required because we may have large multi-page documents and our LLMs may have token limits. These chunks are then loaded into the vector database for performing similarity search in the subsequent steps. In the following example, we use the Amazon Titan Embed Text v1 model, which performs the vector embeddings of the document chunks:
The code creates a relevant context for the LLM using the chunks of text that are returned by the similarity search action from the vector database. For this example, we use an open-source ai.meta.com/tools/faiss/#:~:text=FAISS%20(Facebook%20AI%20Similarity%20Search,more%20scalable%20similarity%20search%20functions.” target=”_blank” rel=”noopener”>FAISS vector store as a sample vector database to store vector embeddings of each chunk of text. We then define the vector database as a LangChain retriever, which is passed into the RetrievalQA chain. This internally runs a similarity search query on the vector database that returns the top n (where n=3 in our example) chunks of text that are relevant to the question. Finally, the LLM chain is run with the relevant context (a group of relevant chunks of text) and the question for the LLM to answer. For a step-by-step code walkthrough of Q&A with RAG, refer to the Python notebook on ai-intelligent-document-processing/blob/main/gen-ai/02-idp-genai-bedrock-qna.ipynb” target=”_blank” rel=”noopener”>GitHub.
As an alternative to FAISS, you can also use Amazon OpenSearch Service vector database capabilities, Amazon Relational Database Service (Amazon RDS) for PostgreSQL with the pgvector extension as vector databases, or open-source Chroma Database.
Q&A with tabular data
Tabular data within documents can be challenging for LLMs to process because of its structural complexity. Amazon Textract can be augmented with LLMs because it enables extracting tables from documents in a nested format of elements such as page, table, and cells. Performing Q&A with tabular data is a multi-step process, and can be achieved via self-querying. The following is an overview of the steps:
- Extract tables from documents using Amazon Textract. With Amazon Textract, the tabular structure (rows, columns, headers) can be extracted from a document.
- Store the tabular data into a vector database along with metadata information, such as the header names and the description of each header.
- Use the prompt to construct a structured query, using an LLM, to derive the data from the table.
- Use the query to extract the relevant table data from the vector database.
For example, in a bank statement, given the prompt “What are the transactions with more than $1000 in deposits,” the LLM would complete the following steps:
- Craft a query, such as
“Query: transactions” , “filter: greater than (Deposit$)”. - Convert the query into a structured query.
- Apply the structured query to the vector database where our table data is stored.
For a step-by-step sample code walkthrough of Q&A with tabular, refer to the Python notebook in ai-intelligent-document-processing/blob/main/gen-ai/03-idp-genai-bedrock-table-qna.ipynb” target=”_blank” rel=”noopener”>GitHub.
Templating and normalizations
In this section, we look at how to use prompt engineering techniques and LangChain’s built-in mechanism to generate an output with extractions from a document in a specified schema. We also perform some standardization on the extracted data, using the techniques discussed previously. We start by defining a template for our desired output. This will serve as a schema and encapsulate the details about each entity we want to extract from the document’s text.
Note that for each of the entities, we use the description to explain what that entity is to help assist the LLM in extracting the value from the document’s text. In the following sample code, we use this template to craft our prompt for the LLM along with the text extracted from the document using AmazonTextractPDFLoader and subsequently perform inference with the model:
As you can see, the {keys} part of the prompt is the keys from our template, and the {details} are the keys along with their description. In this case, we don’t prompt the model explicitly with the format of the output other than specifying in the instruction to generate the output in JSON format. This works for the most part; however, because the output from LLMs is non-deterministic text generation, we want to specify the format explicitly as part of the instruction in the prompt. To solve this, we can use LangChain’s structured output parser module to take advantage of the automated prompt engineering that helps convert our template to a format instruction prompt. We use the template defined earlier to generate the format instruction prompt as follows:
We then use this variable within our original prompt as an instruction to the LLM so that it extracts and formats the output in the desired schema by making a small modification to our prompt:
So far, we have only extracted the data out of the document in a desired schema. However, we still need to perform some standardization. For example, we want the patient’s admitted date and discharge date to be extracted in DD/MM/YYYY format. In this case, we augment the description of the key with the formatting instruction:
Refer to the Python notebook in ai-intelligent-document-processing/blob/main/gen-ai/04-idp-genai-bedrock-template-er.ipynb” target=”_blank” rel=”noopener”>GitHub for a full step-by-step walkthrough and explanation.
Spellchecks and corrections
LLMs have demonstrated remarkable abilities in understanding and generating human-like text. One of the lesser-discussed but immensely useful applications of LLMs is their potential in grammatical checks and sentence correction in documents. Unlike traditional grammar checkers that rely on a set of predefined rules, LLMs use patterns that they have identified from vast amounts of text data to determine what constitutes as correct or fluent language. This means they can detect nuances, context, and subtleties that rule-based systems might miss.
Imagine the text extracted from a patient discharge summary that reads “Patient Jon Doe, who was admittd with sever pnemonia, has shown significant improvemnt and can be safely discharged. Followups are scheduled for nex week.” A traditional spellchecker might recognize “admittd,” “pneumonia,” “improvement,” and “nex” as errors. However, the context of these errors could lead to further mistakes or generic suggestions. An LLM, equipped with its extensive training, might suggest: “Patient John Doe, who was admitted with severe pneumonia, has shown significant improvement and can be safely discharged. Follow-ups are scheduled for next week.”
The following is a poorly handwritten sample document with the same text as explained previously.

We extract the document with an Amazon Textract document loader and then instruct the LLM, via prompt engineering, to rectify the extracted text to correct any spelling and or grammatical mistakes:
The output of the preceding code shows the original text extracted by the document loader followed by the corrected text generated by the LLM:
Keep in mind that as powerful as LLMs are, it’s essential to view their suggestions as just that—suggestions. Although they capture the intricacies of language impressively well, they aren’t infallible. Some suggestions might change the intended meaning or tone of the original text. Therefore, it’s crucial for human reviewers to use LLM-generated corrections as a guide, not an absolute. The collaboration of human intuition with LLM capabilities promises a future where our written communication is not just error-free, but also richer and more nuanced.
Conclusion
Generative ai is changing how you can process documents with IDP to derive insights. In the post Enhancing AWS intelligent document processing with generative ai, we discussed the various stages of the pipeline and how AWS customer Ricoh is enhancing their IDP pipeline with LLMs. In this post, we discussed various mechanisms of augmenting the IDP workflow with LLMs via Amazon Bedrock, Amazon Textract, and the popular LangChain framework. You can get started with the new Amazon Textract document loader with LangChain today using the sample notebooks available in our ai-intelligent-document-processing/tree/main/gen-ai” target=”_blank” rel=”noopener”>GitHub repository. For more information on working with generative ai on AWS, refer to Announcing New Tools for Building with Generative ai on AWS.
About the Authors
 Sonali Sahu is leading intelligent document processing with the ai/ML services team in AWS. She is an author, thought leader, and passionate technologist. Her core area of focus is ai and ML, and she frequently speaks at ai and ML conferences and meetups around the world. She has both breadth and depth of experience in technology and the technology industry, with industry expertise in healthcare, the financial sector, and insurance.
Sonali Sahu is leading intelligent document processing with the ai/ML services team in AWS. She is an author, thought leader, and passionate technologist. Her core area of focus is ai and ML, and she frequently speaks at ai and ML conferences and meetups around the world. She has both breadth and depth of experience in technology and the technology industry, with industry expertise in healthcare, the financial sector, and insurance.
 Anjan Biswas is a Senior ai Services Solutions Architect with a focus on ai/ML and Data Analytics. Anjan is part of the world-wide ai services team and works with customers to help them understand and develop solutions to business problems with ai and ML. Anjan has over 14 years of experience working with global supply chain, manufacturing, and retail organizations, and is actively helping customers get started and scale on AWS ai services.
Anjan Biswas is a Senior ai Services Solutions Architect with a focus on ai/ML and Data Analytics. Anjan is part of the world-wide ai services team and works with customers to help them understand and develop solutions to business problems with ai and ML. Anjan has over 14 years of experience working with global supply chain, manufacturing, and retail organizations, and is actively helping customers get started and scale on AWS ai services.
 Chinmayee Rane is an ai/ML Specialist Solutions Architect at Amazon Web Services. She is passionate about applied mathematics and machine learning. She focuses on designing intelligent document processing and generative ai solutions for AWS customers. Outside of work, she enjoys salsa and bachata dancing.
Chinmayee Rane is an ai/ML Specialist Solutions Architect at Amazon Web Services. She is passionate about applied mathematics and machine learning. She focuses on designing intelligent document processing and generative ai solutions for AWS customers. Outside of work, she enjoys salsa and bachata dancing.





{kind=link}