
The rise of large language models (LLM) and core models (FM) has revolutionized the field of natural language processing (NLP) and artificial intelligence (ai). These powerful models, trained with large amounts of data, can generate human-like text, answer questions, and even perform creative writing tasks. However, training and deploying such models from scratch is a complex and resource-intensive process, often requiring specialized expertise and significant computational resources.
Enter amazon Bedrock, a fully managed service that gives developers seamless access to cutting-edge FM through simple APIs. amazon Bedrock streamlines the integration of next-generation generative ai capabilities for developers, offering pre-trained models that can be customized and deployed without the need for extensive model training from scratch. amazon maintains flexibility for model customization while simplifying the process, making it easier for developers to use cutting-edge generative ai technologies in their applications. With amazon Bedrock, you can integrate advanced NLP features, such as language understanding, text generation, and question answering, into your applications.
In this post, we explore how to integrate amazon Bedrock FM into your codebase, allowing you to build powerful ai-powered applications with ease. We guide you through the process of setting up the environment, creating the amazon Bedrock client, requesting and packaging the code, invoking the models, and using various models and streaming invocations. By the end of this post, you'll have the knowledge and tools to harness the power of amazon Bedrock FM, accelerate your product development timelines, and supercharge your applications with advanced ai capabilities.
Solution Overview
amazon Bedrock provides a simple and efficient way to use powerful FMs through APIs, without the need to train custom models. For this post, we ran the code in a Jupyter notebook within VS Code and used Python. The process of integrating amazon Bedrock into your codebase involves the following steps:
- Set up your development environment by importing the necessary dependencies and creating an amazon Bedrock client. This client will serve as the entry point to interact with amazon Bedrock FM.
- After you configure the amazon Bedrock client, you can define prompts or code snippets to use to interact with FMs. These prompts may include natural language instructions or code snippets that the model will process and generate results based on.
- With the prompts defined, you can invoke amazon Bedrock FM by passing the prompts to the client. amazon Bedrock supports several models, each with their own strengths and capabilities, allowing you to choose the model best suited for your use case.
- Based on the model and prompts provided, amazon Bedrock will generate results, which may include natural language text, code snippets, or a combination of both. You can then process and integrate this result into your application as needed.
- For certain models and use cases, amazon Bedrock supports streaming invocations, which allow you to interact with the model in real time. This can be especially useful for conversational ai or interactive applications where multiple prompts and responses need to be exchanged with the model.
Throughout this post, we provide detailed code examples and explanations for each step, helping you seamlessly integrate amazon Bedrock FM into your codebase. By using these powerful models, you can enhance your applications with advanced NLP capabilities, accelerate your development process, and deliver innovative solutions to your users.
Prerequisites
Before you dive into the integration process, make sure you meet the following prerequisites:
- AWS account – You will need an AWS account to access and use amazon Bedrock. If you don't have one, you can ai=DChcSEwjK16_r7vmHAxW3Fq0GHWT0B-MYABAAGgJwdg&co=1&ase=2&gclid=CjwKCAjw8fu1BhBsEiwAwDrsjEacl3E8JCMeG0QMHM3MaFgHXyQHKq0YEw1K8jEbBmW-7mcprmgcJBoCjnYQAvD_BwE&ei=a3W_ZpSYBunakPIPsLun-A8&ohost=www.google.com&cid=CAESV-D2XkLrC13UrfHfbeCQ5XgQXRdCFWAXy_ENoGsQRqqI-hVP7MIccZ7JLgJIlN_SWZIJ8QIguZ_oMI_7i6AJW7GmjTwXZ0UiYb13eC02tQo3ph1he_QfSg&sig=AOD64_2XaK-oOl7Yl7IynDi8CeYQQ3L9mg&q&sqi=2&nis=4&adurl&ved=2ahUKEwjU-aXr7vmHAxVpLUQIHbDdCf8Q0Qx6BAgIEAE” target=”_blank” rel=”noopener”>create a new account.
- Development environment – Set up an integrated development environment (IDE) with your preferred coding language and tools. You can interact with amazon Bedrock using the AWS SDKs available in Python, Java, Node.js, and more.
- AWS credentials – Configure your AWS credentials in your development environment to authenticate with AWS services. You can find instructions on how to do this in the AWS documentation for your chosen SDK. In this post we look at a Python example.
With these prerequisites in place, you are ready to start integrating amazon Bedrock FM into your code.
In your IDE, create a new file. For this example, we use a Jupyter notebook (Kernel: Python 3.12.0).
In the following sections, we demonstrate how to implement the solution in a Jupyter notebook.
Set up the environment
To get started, import the dependencies necessary to interact with amazon Bedrock. The following is an example of how you can do this in Python.
The first step is to import. boto3 and json:
Next, create an instance of the amazon Bedrock client. This client will serve as the entry point to interact with the FMs. The following is a code example of how to create the client:
Define prompts and code snippets
With the amazon Bedrock client configured, define prompts and code snippets to use to interact with FMs. These prompts may include natural language instructions or code snippets that the model will process and generate results based on.
In this example, we ask the model, “Hello, who are you?”.
To send the message to the API endpoint, you need to pass some keyword arguments. You can get these arguments from the amazon Bedrock console.
- In the amazon Bedrock console, choose Basic models in the navigation panel.
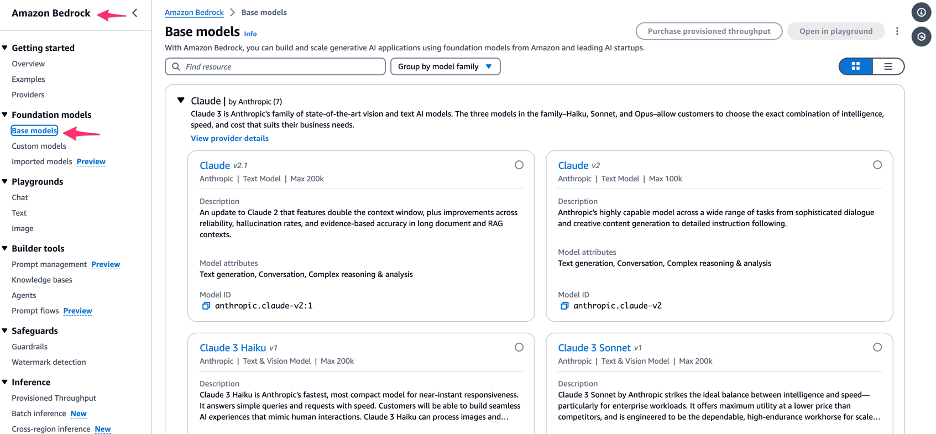
- Select Titan G1 Text – Fast.
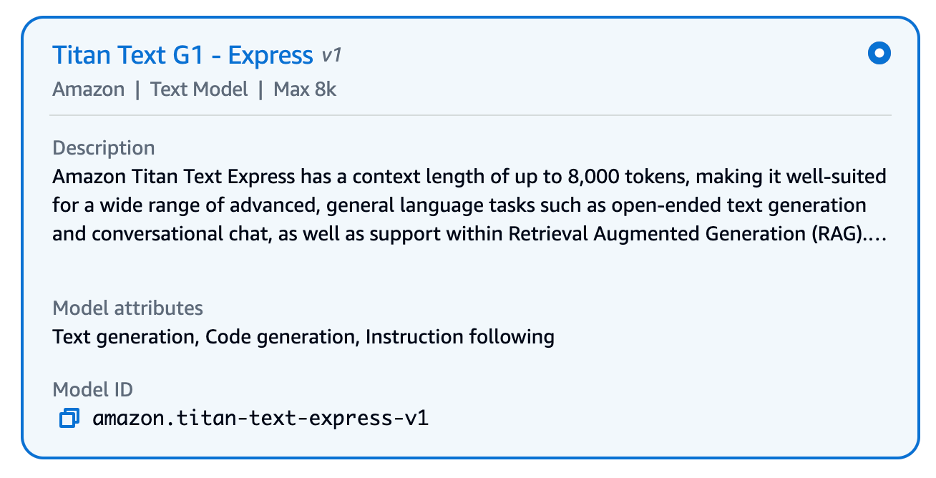
- Choose the model name (Titan G1 Text – Fast) and go to the API request.
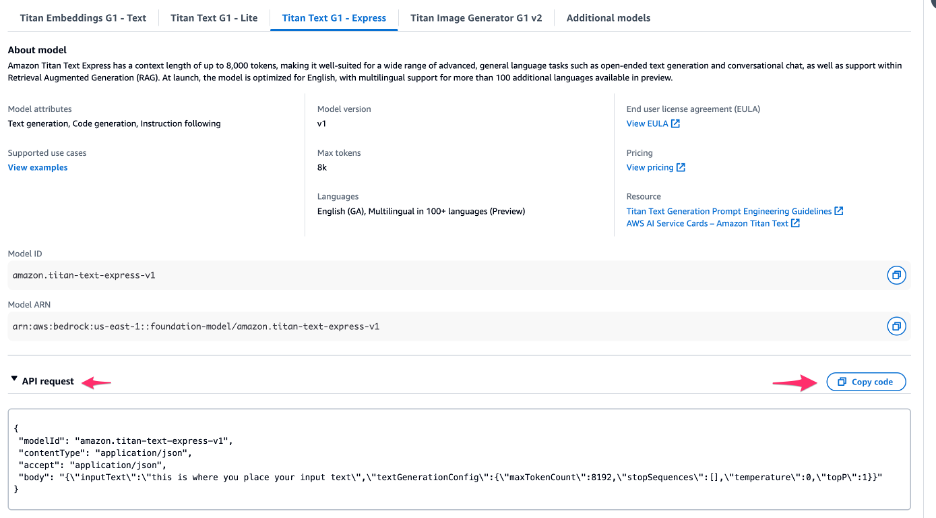
- Copy the API request:
- Insert this code into Jupyter notebook with the following minor modifications:
- We post API requests to keyword arguments (kwargs).
- The next change occurs in the message. We will replace \”this is where you put the entered text\” with \”Hello, who are you?\”
- Print the keyword arguments:
This should give you the following result:
{'modelId': 'amazon.titan-text-express-v1', 'contentType': 'application/json', 'accept': 'application/json', 'body': '{"inputText":"Hello, who are you?","textGenerationConfig":{"maxTokenCount":8192,"stopSequences":(),"temperature":0,"topP":1}}'}
Invoke the model
With the message defined, you can now invoke amazon Bedrock FM.
- Pass the message to the client:
This will invoke the amazon Bedrock model with the provided message and print the response from the generated stream body object.
{'ResponseMetadata': {'RequestId': '3cfe2718-b018-4a50-94e3-59e2080c75a3',
'HTTPStatusCode': 200,
'HTTPHeaders': {'date': 'Fri, 18 Oct 2024 11:30:14 GMT',
'content-type': 'application/json',
'content-length': '255',
'connection': 'keep-alive',
'x-amzn-requestid': '3cfe2718-b018-4a50-94e3-59e2080c75a3',
'x-amzn-bedrock-invocation-latency': '1980',
'x-amzn-bedrock-output-token-count': '37',
'x-amzn-bedrock-input-token-count': '6'},
'RetryAttempts': 0},
'contentType': 'application/json',
'body': }
The amazon Bedrock runtime invocation model above will work for the FM you choose to invoke.
- Unpack the JSON string as follows:
You should receive the following response (this is the response we received from the Titan Text G1 – Express model to the message we provided).
{'inputTextTokenCount': 6, 'results': ({'tokenCount': 37, 'outputText': '\nI am amazon Titan, a large language model built by AWS. It is designed to assist you with tasks and answer any questions you may have. How may I help you?', 'completionReason': 'FINISH'})}
Experiment with different models.
amazon Bedrock offers several FMs, each with their own strengths and capabilities. You can specify which model you want to use by passing the model_name parameter when creating the amazon Bedrock client.
- As in the Titan Text G1 – Express example above, get the API request from the amazon Bedrock console. This time, we used Claude from Anthropic on amazon Bedrock.
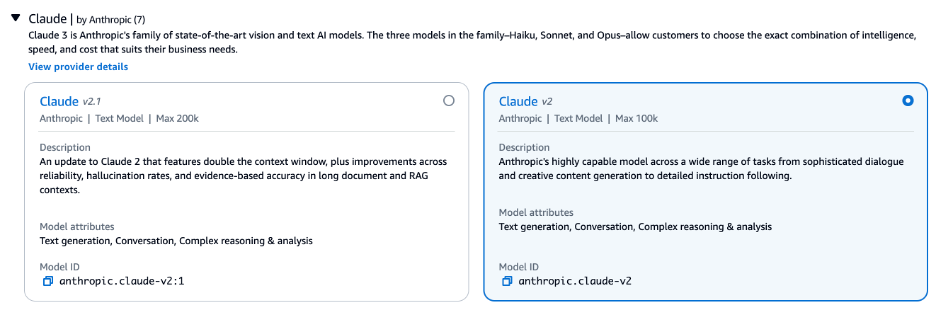
{"modelId": "anthropic.claude-v2","contentType": "application/json","accept": "*/*","body": "{\"prompt\":\"\\n\\nHuman: Hello world\\n\\nAssistant:\",\"max_tokens_to_sample\":300,\"temperature\":0.5,\"top_k\":250,\"top_p\":1,\"stop_sequences\":(\"\\n\\nHuman:\"),\"anthropic_version\":\"bedrock-2023-05-31\"}"}
Anthropic's Claude accepts the message in a different way (\\n\\nHuman:), so the API request in the amazon Bedrock console provides the message in the form that Anthropic's Claude can accept.
- Edit the API request and place it in the keyword argument:
You should get the following response:
{'modelId': 'anthropic.claude-v2', 'contentType': 'application/json', 'accept': '*/*', 'body': '{"prompt":"\\n\\nHuman: we have received some text without any context.\\nWe will need to label the text with a title so that others can quickly see what the text is about \\n\\nHere is the text between these XML tags\\n\\n\\nToday I sent to the beach and saw a whale. I ate an ice-cream and swam in the sea\\n\\n\\nProvide title between
- With the message defined, you can now invoke amazon Bedrock FM by passing the message to the client:
You should get the following result:
{'ResponseMetadata': {'RequestId': '72d2b1c7-cbc8-42ed-9098-2b4eb41cd14e', 'HTTPStatusCode': 200, 'HTTPHeaders': {'date': 'Thu, 17 Oct 2024 15:07:23 GMT', 'content-type': 'application/json', 'content-length': '121', 'connection': 'keep-alive', 'x-amzn-requestid': '72d2b1c7-cbc8-42ed-9098-2b4eb41cd14e', 'x-amzn-bedrock-invocation-latency': '538', 'x-amzn-bedrock-output-token-count': '15', 'x-amzn-bedrock-input-token-count': '100'}, 'RetryAttempts': 0}, 'contentType': 'application/json', 'body': }
- Unpack the JSON string as follows:
This results in the following result about the title of the given text.
{'type': 'completion',
'completion': '
'stop_reason': 'stop_sequence',
'stop': '\n\nHuman:'}
- Print the completion:
Because the response is returned in the XML tags as you defined them, you can consume the response and display it to the client.
'
Invoke model with transmission code
For certain models and use cases, amazon Bedrock supports streaming invocations, which allow you to interact with the model in real time. This can be especially useful for conversational ai or interactive applications where multiple prompts and responses need to be exchanged with the model. For example, if you ask the FM for an article or story, you may want to broadcast the result of the generated content.
- Import the dependencies and create the amazon Bedrock client:
- Define the message as follows:
- Edit the API request and put it in a keyword argument as before:
We use the claude-v2 model API request.
- You can now invoke amazon Bedrock FM by passing the message to the client:
We useinvoke_model_with_response_streamratherinvoke_model.
You will get a response like the following as streaming output:
Here is a draft article about the fictional planet Foobar: Exploring the Mysteries of Planet Foobar Far off in a distant solar system lies the mysterious planet Foobar. This strange world has confounded scientists and explorers for centuries with its bizarre environments and alien lifeforms. Foobar is slightly larger than Earth and orbits a small, dim red star. From space, the planet appears rusty orange due to its sandy deserts and red rock formations. While the planet looks barren and dry at first glance, it actually contains a diverse array of ecosystems. The poles of Foobar are covered in icy tundra, home to resilient lichen-like plants and furry, six-legged mammals. Moving towards the equator, the tundra slowly gives way to rocky badlands dotted with scrubby vegetation. This arid zone contains ancient dried up riverbeds that point to a once lush environment. The heart of Foobar is dominated by expansive deserts of fine, deep red sand. These deserts experience scorching heat during the day but drop to freezing temperatures at night. Hardy cactus-like plants manage to thrive in this harsh landscape alongside tough reptilian creatures. Oases rich with palm-like trees can occasionally be found tucked away in hidden canyons. Scattered throughout Foobar are pockets of tropical jungles thriving along rivers and wetlands.
Conclusion
In this post, we show how to integrate amazon Bedrock FM into your codebase. With amazon Bedrock, you can use next-generation generative ai capabilities without the need to train custom models, speeding up your development process and allowing you to build powerful applications with advanced NLP capabilities.
Whether you're building a conversational ai assistant, a code generation tool, or another application that requires NLP capabilities, amazon Bedrock provides a simple and efficient solution. By harnessing the power of FMs through amazon Bedrock APIs, you can focus on creating innovative solutions and delivering value to your users, without worrying about the underlying complexities of language models.
As you continue to explore and integrate amazon Bedrock into your projects, remember to stay up to date with the latest updates and features the service offers. Additionally, consider exploring other AWS services and tools that can complement and enhance your ai-powered applications, such as amazon SageMaker for training and deploying machine learning models, or amazon Lex for creating conversational interfaces.
To further explore the capabilities of amazon Bedrock, check out the following resources:
Share and learn with our generative ai community at ai?trk=e8665609-785f-4bbe-86e8-750a3d3e9e61&sc_channel=el” target=”_blank” rel=”noopener”>community.aws
Happy coding and building with amazon Bedrock!
About the authors
 Rajakumar Sampathkumar is a Senior Technical Account Manager at AWS, providing guidance to clients on enterprise technology alignment and supporting the reinvention of their cloud operating models and processes. He is passionate about the cloud and machine learning. Raj is also a machine learning specialist and works with AWS customers to design, deploy, and manage their AWS workloads and architectures.
Rajakumar Sampathkumar is a Senior Technical Account Manager at AWS, providing guidance to clients on enterprise technology alignment and supporting the reinvention of their cloud operating models and processes. He is passionate about the cloud and machine learning. Raj is also a machine learning specialist and works with AWS customers to design, deploy, and manage their AWS workloads and architectures.
 Yadu Kishore Tatavarthi is a Senior Partner Solutions Architect at amazon Web Services, supporting customers and partners around the world. For the past 20 years, he has helped clients create enterprise data strategies, advising them on generative ai, cloud deployments, migrations, creating reference architectures, data modeling best practices, and data lake/warehouse architectures. .
Yadu Kishore Tatavarthi is a Senior Partner Solutions Architect at amazon Web Services, supporting customers and partners around the world. For the past 20 years, he has helped clients create enterprise data strategies, advising them on generative ai, cloud deployments, migrations, creating reference architectures, data modeling best practices, and data lake/warehouse architectures. .





{kind=link}