 NEWSLETTER
NEWSLETTER
A voice replicator is a powerful tool for people at risk of losing the ability to speak, including those with a recent diagnosis of amyotrophic lateral sclerosis (ALS) or other conditions that can progressively affect the ability to speak. First introduced in May 2023 and available in iOS 17 in September 2023. personal voice is a tool that creates a synthesized voice for such users to speak on FaceTime, phone calls, support communication applications, and in-person conversations.
To start, the user reads aloud a random set of text prompts to record 150 sentences on the latest iPhone, iPad, or Mac. The voice audio is then tuned with machine learning techniques overnight right on the device while the device is charging, locked and connected. to wifi. This is just to download the pre-trained asset. The next day, the person can type what they want to say using Live Speech's text-to-speech (TTS) feature, as illustrated in Figure 1and be heard in conversation with a voice that sounds like theirs. Because model training and inference are performed entirely on the device, users can take advantage of personal voice whenever they want and keep their information private and secure.
In this research highlight, we look at the three machine learning approaches behind Personal Voice:
- Personal voice TTS system
- Voice model pre-training and tuning
- Improved on-device voice recording
Figure 1: Personal voice feature in iOS17. Image A shows instructions for creating a personal voice and how to use it.
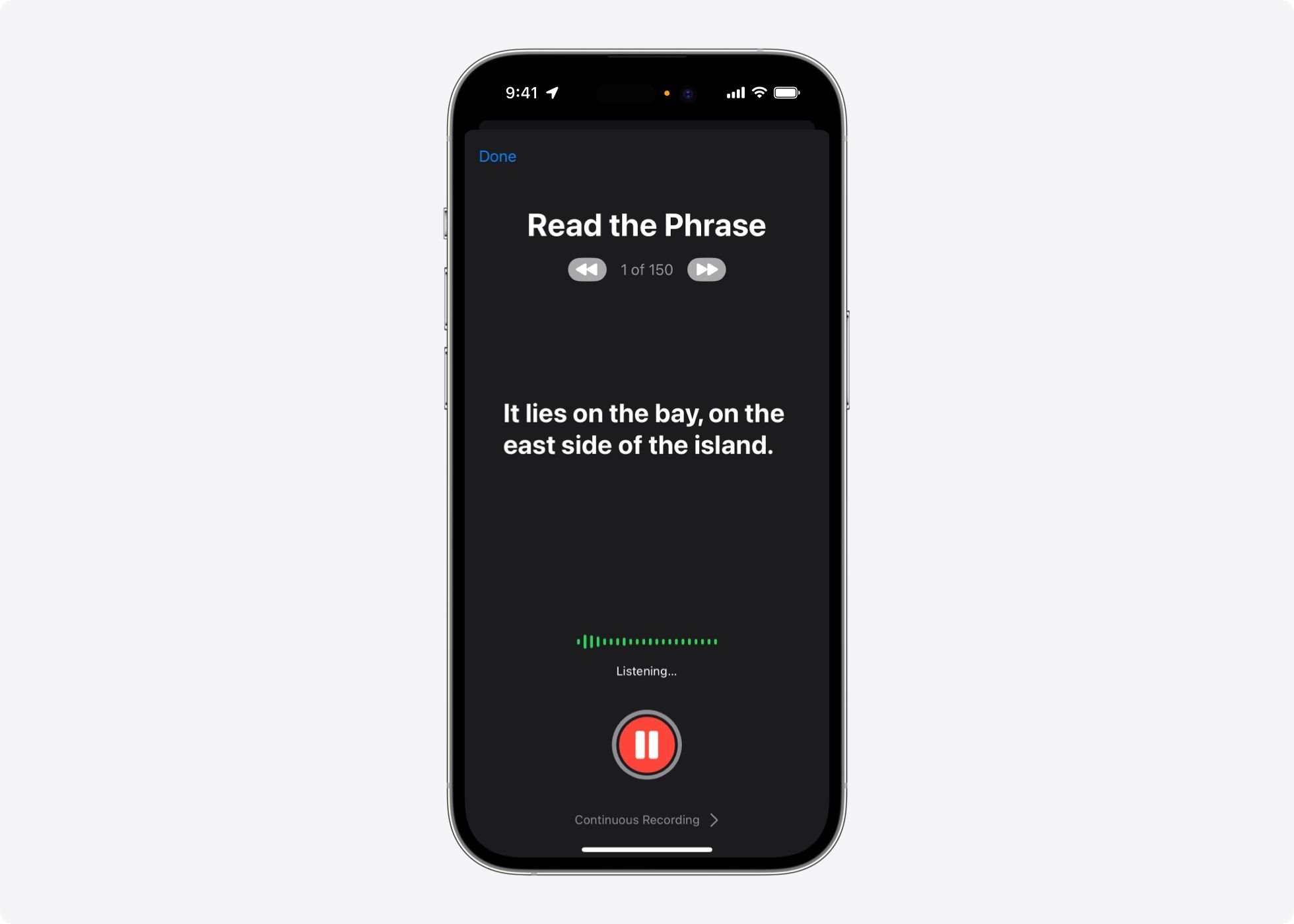
Figure 1: Personal voice feature in iOS17. Image B shows what a recording process looks like.
Personal voice TTS system
The first machine learning approach we will look at is a typical neural TTS system, which receives text and provides speech output. A TTS system includes three main components:
- Text processing: Converts graphemes (written text) to phonemes, a written notation that represents distinct units of sound (such as h of hat and the c of cat in English)
- acoustic model– converts phonemes into acoustic features (for example, into the Mel spectrum, a frequency representation of sound, designed to represent the range of human speech)
- vocoder model: Converts acoustic features into speech waveforms, providing a representation of the audio signal over time.
To develop Personal Voice, Apple researchers worked on the Open SLR LibriTTS data set. The clean data set includes 300 hours of 1000 speakers with very different speaking styles or accents. Personal Voice must produce voice output that others can recognize as the target speaker's voice. Both the acoustic model and the vocoder model depend on the speaker in a typical TTS system. To clone the voice of the target speaker, we fine-tune the acoustic model with on-device training. For the vocoder model, we consider both a universal model and an on-device adaptation. Our team found that adjusting just the acoustic model and using a universal vocoder often results in poorer voice quality. Unusual prosody, audio glitches, and noise were more common when tested with invisible speakers. Tuning both models, as seen in Figure 2requires additional training time on the device but results in better overall quality.

Listening tests showed that fitting both models achieved the best voice quality and similarity to the target speaker's voice, measured by the mean opinion score (MOS) and voice similarity score (VS), respectively. The MOS is 0.43 higher on average than the universal vocoder version. Additionally, tuning can reduce the actual size of the model enough to achieve real-time speech synthesis for a faster and more satisfying conversation experience.
Voice model pre-training and tuning
The next machine learning approaches we will look at are speech model pre-training and tuning. The models contain two parts:
- Modified acoustic model based on FastSpeech2
- WaveRNN-based vocoder model
The acoustic model follows an architecture similar to quick speech2. However, we add the speaker ID as part of the decoder input to learn general speech information during the pre-training stage. Additionally, our team uses dilated convolution layers for decoding instead of transformer-based layers. This results in faster training and inference, as well as lower memory consumption, making the models shippable on iPhone and iPad.
We use a general pre-training and tuning strategy for Personal Voice. Both the acoustic and vocoder models are pretrained with the same Open SLR LibriTTS data set.
During the fitting stage with the target speaker data, we fit only the decoder part and variation adapters of the acoustic model. Variation adapters are used to predict the duration, pitch, and energy of the target speaker's phoneme. However, we do a full model adaptation, in which all parameters will be adjusted, for the vocoder model. Additionally, the entire setup stage (and the Personal TTS system) happens on the user's Apple device, not the server. To speed up on-device training performance, we use full bfloat16 precision with fp32 accumulation for vocoder model tuning with a batch size of 32. Each batch contains 10 ms audio samples.
Improved on-device voice recording
The last machine learning approach we will look at is improving on-device voice recording. Those who use the Personal Voice feature can record their voice samples wherever they want. As a result, those recordings may include unwanted sounds, such as traffic noise or the voices of other people nearby. In our research, we found that the quality of the generated or synthesized voice is highly related to the quality of the user's recordings. Therefore, we apply speech augmentation to the target speaker data to achieve the best speech quality.
Our speech augmentation contains four main components as seen in figure 3:
- Sound pressure level (SPL) and signal-to-noise ratio (SNR) filtering: Eliminates very noisy recordings that are difficult to improve.
- Voice Isolation: Eliminates general noise and leaves speech alone.
- Mel Spectrum Augmentation – Model-based solution providing cleaner Mel spectrum with better audio fidelity
- Audio Recovery – Model-based solution to recover audio signal from enhanced Mel spectrum

Our Mel spectrum augmentation model is a model based on U-Net, trained with a noisy Mel spectrum as input and a clean Mel spectrum as output. The audio recovery model is simple. Chunked Autoregressive GAN (CarGAN) Model which converts a clean Mel spectrum into an audio signal.
With the voice augmentation stream, we found that the quality of the generated voice improved significantly, especially with the real-world iPhone recorded data we collected from the internal and external speakers. The MOS score is 0.25 higher compared to the reference stream that has no audio boost.
Figure 4 shows the final results of the Personal Voice quality assessment, both in average opinion score and voice similarity score.
Conclusion
In this research spotlight, we cover the technical details behind the Personal Voice feature, which accessibility users can use to create their own voice overnight entirely on the device and use it with real-time speech synthesis to talk to others. Our hope is that people at risk of losing the ability to speak, such as those with ALS or other conditions that may decrease their ability to speak, can benefit greatly from the Personal Voice feature.
Expressions of gratitude
Many people contributed to this work, including Dipjyoti Paul, Jiangchuan Li, Luke Chang, Petko Petkov, Pierre Su, Shifas Padinjaru Veettil, and Ye Tian.
Apple Resources
Apple developer. 2023. “Extended speech synthesis with personal and personalized voices.” (link.)
Apple Newsroom. 2023. “Apple introduces new cognitive accessibility features, along with live voice, personal voice, and point-and-talk with magnifying glass.” (link.)
Apple Support. 2023. “Create a personal voice on your iPhone, iPad or Mac.” (link.)
Apple Youtube. 2023. “Personal Voice on iPhone: The Lost Voice.” (link.)
References
Kalchbrenner, Nal, Erich Elsen, Karen Simonyan, Seb Noury, Norman Casagrande, Edward Lockhart, Florian Stimberg, et al. 2018. “Efficient Neural Audio Synthesis.” (link.)
Morrison, Max, Rithesh Kumar, Kundan Kumar, Prem Seetharaman, Aaron Courville, and Yoshua Bengio. 2022. “Chunked Autoregressive GAN for Conditional Waveform Synthesis.” March. ,link.)
Open reflex camera. and “Corpus LibriTTS”. (link.)
Ren, Yi, Chenxu Hu, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, and Tie-Yan Liu. 2021. “FastSpeech 2: Fast, high-quality end-to-end text to speech.” March. (link.)
Silva-Rodríguez, J., MF Dolz, M. Ferrer, A. Castelló, V. Naranjo, and G. Piñero. 2021. “Acoustic Echo Cancellation Using Residual U-Nets.” September. (link.)




{kind=link}