 NEWSLETTER
NEWSLETTER
Protein docking, the process of predicting the structure of protein-protein complexes, remains a complex challenge in computational biology. While advances like AlphaFold have transformed prediction from sequence to structure, accurately modeling protein interactions is often complicated by conformational flexibility, where proteins undergo structural changes upon binding. For example, AlphaFold-multimer (AFm), an extension of AlphaFold, achieves a success rate of only 43% in modeling complex interactions, particularly for targets that require significant structural adjustments. These challenges are especially evident in highly flexible targets, such as antibody-antigen complexes, which are further complicated by scarce evolutionary data. Conventional physics-based docking tools, such as ReplicaDock 2.0, address some aspects of these problems, but often struggle with efficiency and adaptability, highlighting the need for approaches that combine multiple strengths.
Johns Hopkins researchers have introduced AlphaRED, a docking pipeline that integrates the predictive capabilities of AlphaFold with the physics-based sampling methods of ReplicaDock 2.0. AlphaRED is designed to address the specific challenges of conformational flexibility and binding site prediction. By leveraging AlphaFold multimer confidence metrics, such as the predicted local distance difference test (pLDDT), the pipeline identifies flexible protein regions and refines docking predictions to improve accuracy. For challenging cases such as antigen-antibody targets, AlphaRED demonstrates a 43% success rate, doubling the performance of the AlphaFold multimer. Additionally, it generates CAPRI models of acceptable quality for 63% of benchmark targets, compared to 43% for AlphaFold. This approach effectively combines the strengths of deep learning and physics-based methods to improve the prediction of protein complexes.
Technical details and benefits
AlphaRED begins by using AlphaFold-multimer to generate structural templates, which are then evaluated based on interface-specific pLDDT scores. When predictions show low confidence in the interface, the pipeline employs ReplicaDock 2.0 for global docking simulations, using Monte Carlo replica sharing to explore various conformations. For high confidence models, AlphaRED performs localized refinements, focusing on backbone flexibility in regions indicated by low per-residue pLDDT scores. This targeted approach captures binding-induced conformational changes and improves prediction accuracy. By combining the complementary strengths of machine learning and physics-based sampling, AlphaRED addresses scenarios involving high flexibility or limited evolutionary data more effectively than either approach alone.
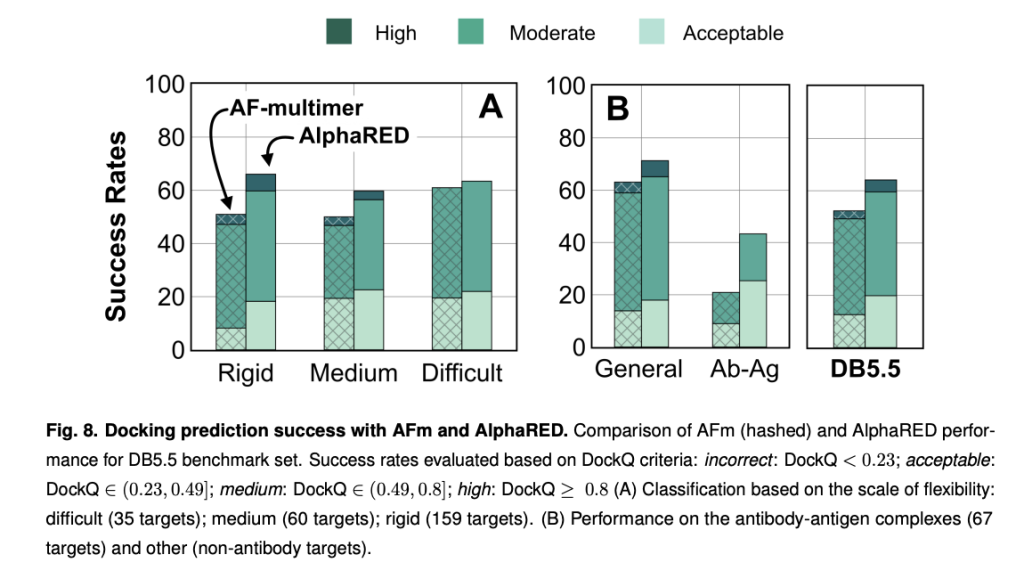
Results and insights
AlphaRED was tested on a curated data set of 254 targets, including rigid, medium, and highly flexible protein complexes. It showed significant improvements in all categories, with notable success in antibody-antigen coupling. For example, AlphaRED's DockQ scores exceeded 0.23 for 63% of the data set, compared to 43% for AlphaFold-multimer. In blinded evaluations such as CASP15, AlphaRED excelled, particularly in nanobody-antigen complexes where AlphaFold struggled due to limited coevolutionary information. Additionally, AlphaRED significantly reduced the root mean square deviations (RMSDs) of the interface, refining initial AlphaFold predictions into models closer to the native structures. These results suggest that AlphaRED has promise for applications in therapeutic antibody design and structural biology.
Conclusion
AlphaRED offers a careful integration of AlphaFold's deep learning capabilities with ReplicaDock 2.0's adaptive sampling techniques. This pipeline improves coupling accuracy while providing a practical solution for complex cases involving conformational flexibility. Its demonstrated success in challenging docking scenarios, such as antibody-antigen complexes and blinded screens, makes it a valuable tool for advancing structural biology and drug discovery. By effectively combining the strengths of machine learning and physics-based approaches, AlphaRED represents an important step forward in the reliable prediction of protein complexes and opens up new possibilities for computational biology research.
Verify he Paper and GitHub page. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 60,000 ml.
UPCOMING FREE ai WEBINAR (JANUARY 15, 2025): <a target="_blank" href="https://info.gretel.ai/boost-llm-accuracy-with-sd-and-evaluation-intelligence?utm_source=marktechpost&utm_medium=newsletter&utm_campaign=202501_gretel_galileo_webinar”>Increase LLM Accuracy with Synthetic Data and Assessment Intelligence–<a target="_blank" href="https://info.gretel.ai/boost-llm-accuracy-with-sd-and-evaluation-intelligence?utm_source=marktechpost&utm_medium=newsletter&utm_campaign=202501_gretel_galileo_webinar”>Join this webinar to learn practical information to improve LLM model performance and accuracy while protecting data privacy..
Sana Hassan, a consulting intern at Marktechpost and a dual degree student at IIT Madras, is passionate about applying technology and artificial intelligence to address real-world challenges. With a strong interest in solving practical problems, he brings a new perspective to the intersection of ai and real-life solutions.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}