 NEWSLETTER
NEWSLETTER
Large language models (LLMs) have become a fundamental part of artificial intelligence, as they enable systems to understand, generate, and respond to human language. These models are used in various domains, including natural language reasoning, code generation, and problem solving. LLMs are typically trained on large amounts of unstructured data from the internet, allowing them to develop a broad understanding of language. However, they need to be fine-tuned to make them more task-specific and align with human intent. Fine-tuning involves using instruction datasets consisting of structured question-answer pairs. This process is vital to improving the models’ ability to perform accurately in real-world applications.
The increasing availability of training datasets presents a key challenge for researchers: efficiently selecting a data subset that improves model training without exhausting computational resources. With datasets reaching into the hundreds of thousands of samples, it is difficult to determine which subset is optimal for training. This problem is compounded by the fact that some data points contribute more significantly to the learning process than others. More is required than simply relying on data quality. Instead, there must be a balance between data quality and diversity. Prioritizing diversity in training data ensures that the model can effectively generalize across various tasks, avoiding overfitting to specific domains.
Current data selection methods typically focus on local features such as data quality. For example, traditional approaches often filter out low-quality samples or duplicate instances to avoid training the model with suboptimal data. However, this approach often overlooks the importance of diversity. Selecting only high-quality data can result in models that perform well on specific tasks but need help with broader generalization. While quality-first sampling has been used in previous studies, it lacks a holistic view of the overall representativeness of the dataset. Furthermore, manually curated datasets or quality-based filters are time-consuming and may not capture the full complexity of the data.
Researchers from Northeastern University, Stanford University, Google Research and Cohere For ai have presented an innovative Iterative refinement method To overcome these challenges, their approach emphasizes diversity-focused data selection using k-means clustering. This method ensures that the selected data subset represents the entire dataset more accurately. The researchers propose an iterative refinement process inspired by active learning techniques, which allows the model to resample cluster instances during training. This iterative approach ensures that clusters containing low-quality or outlier data are gradually filtered out, focusing more on diverse and representative data points. The method aims to balance quality and diversity, ensuring that the model is not biased towards specific data categories.
The method introduced k-means quality sampling (kMQ) and groups the data points into clusters based on their similarity. The algorithm then samples data from each cluster to form a training data subset. Each cluster is assigned a sampling weight proportional to its size, which is adjusted during training based on how well the model learns from each cluster. Essentially, clusters with high-quality data are prioritized, while lower-quality data are given less weight in later iterations. The iterative process allows the model to refine its learning as it progresses through training, making adjustments as needed. This method is in contrast to traditional fixed-sampling methods, which do not consider the model’s learning behavior during training.
The performance of this method has been rigorously tested on multiple tasks including question answering, reasoning, mathematics, and code generation. The research team evaluated their model on several benchmark datasets such as MMLU (academic question answering), GSM8k (elementary mathematics), and HumanEval (code generation). The results were significant: the kMQ sampling method led to a 7% improvement in performance compared to random data selection and a 3.8% improvement compared to state-of-the-art methods such as Deita and QDIT. On tasks such as HellaSwag, which tests common sense reasoning, the model achieved 83.3% accuracy, while on GSM8k, the model improved from 14.5% to 18.4% accuracy using the kMQ iterative process. This demonstrated the effectiveness of diversity-first sampling in improving the generalization of the model across multiple tasks.
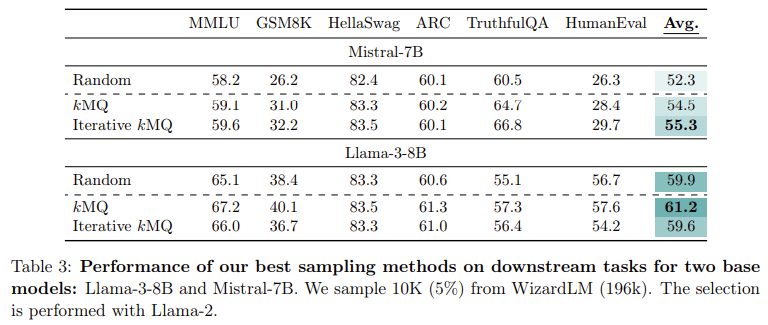
The researchers’ method surpassed previous efficiency techniques with these significant performance improvements. Unlike more complex processes that rely on large language models to score and filter data points, kMQ achieves competitive results without expensive computational resources. By using a simple clustering algorithm and iterative refinement, the process is scalable and accessible, making it suitable for a variety of models and datasets. This makes the method particularly useful for researchers working with limited resources and still looking to achieve high performance in LLM training.

In conclusion, this research addresses one of the most important challenges in training large language models: selecting a diverse and high-quality data subset that maximizes performance across all tasks. By introducing k-means clustering and iterative refinement, the researchers have developed an efficient method that balances diversity and quality in data selection. Their approach leads to performance improvements of up to 7% and ensures that the models can generalize across a broad spectrum of tasks.
Take a look at the Paper and ai/iterative-data-selection” target=”_blank” rel=”noreferrer noopener”>GitHubAll credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram Channel and LinkedIn GrAbove!. If you like our work, you will love our fact sheet..
Don't forget to join our SubReddit of over 50,000 ml
FREE ai WEBINAR: 'SAM 2 for Video: How to Optimize Your Data' (Wednesday, September 25, 4:00 am – 4:45 am EST)
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary engineer and entrepreneur, Asif is committed to harnessing the potential of ai for social good. His most recent initiative is the launch of an ai media platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easily understandable to a wide audience. The platform has over 2 million monthly views, illustrating its popularity among the public.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}