
Text-to-image generation is a rapidly growing field of artificial intelligence with applications in a variety of areas, such as media and entertainment, gaming, ecommerce product visualization, advertising and marketing, architectural design and visualization, artistic creations, and medical imaging.
ai/blog/stable-diffusion-announcement” target=”_blank” rel=”noopener”>Stable Diffusion is a text-to-image model that empowers you to create high-quality images within seconds. In November 2022, we announced that AWS customers can generate images from text with ai/blog/stable-diffusion-v2-release” target=”_blank” rel=”noopener”>Stable Diffusion models in Amazon SageMaker JumpStart, a machine learning (ML) hub offering models, algorithms, and solutions. The evolution continued in April 2023 with the introduction of Amazon Bedrock, a fully managed service offering access to cutting-edge foundation models, including Stable Diffusion, through a convenient API.
As an ever-increasing number of customers embark on their text-to-image endeavors, a common hurdle arises—how to craft prompts that wield the power to yield high-quality, purpose-driven images. This challenge often demands considerable time and resources as users embark on an iterative journey of experimentation to discover the prompts that align with their visions.
Retrieval Augmented Generation (RAG) is a process in which a language model retrieves contextual documents from an external data source and uses this information to generate more accurate and informative text. This technique is particularly useful for knowledge-intensive natural language processing (NLP) tasks. We now extend its transformative touch to the world of text-to-image generation. In this post, we demonstrate how to harness the power of RAG to enhance the prompts sent to your Stable Diffusion models. You can create your own ai assistant for prompt generation in minutes with large language models (LLMs) on Amazon Bedrock, as well as on SageMaker JumpStart.
Approaches to crafting text-to-image prompts
Creating a prompt for a text-to-image model may seem straightforward at first glance, but it’s a deceptively complex task. It’s more than just typing a few words and expecting the model to conjure an image that aligns with your mental image. Effective prompts should provide clear instructions while leaving room for creativity. They must balance specificity and ambiguity, and they should be tailored to the particular model being used. To address the challenge of prompt engineering, the industry has explored various approaches:
- Prompt libraries – Some companies curate libraries of pre-written prompts that you can access and customize. These libraries contain a wide range of prompts tailored to various use cases, allowing you to choose or adapt prompts that align with your specific needs.
- Prompt templates and guidelines – Many companies and organizations provide users with a set of predefined prompt templates and guidelines. These templates offer structured formats for writing prompts, making it straightforward to craft effective instructions.
- Community and user contributions – Crowdsourced platforms and user communities often play a significant role in improving prompts. Users can share their fine-tuned models, successful prompts, tips, and best practices with the community, helping others learn and refine their prompt-writing skills.
- Model fine-tuning – Companies may fine-tune their text-to-image models to better understand and respond to specific types of prompts. Fine-tuning can improve model performance for particular domains or use cases.
These industry approaches collectively aim to make the process of crafting effective text-to-image prompts more accessible, user-friendly, and efficient, ultimately enhancing the usability and versatility of text-to-image generation models for a wide range of applications.
Using RAG for prompt design
In this section, we delve into how RAG techniques can serve as a game changer in prompt engineering, working in harmony with these existing approaches. By seamlessly integrating RAG into the process, we can streamline and enhance the efficiency of prompt design.
Semantic search in a prompt database
Imagine a company that has accumulated a vast repository of prompts in its prompt library or has created a large number of prompt templates, each designed for specific use cases and objectives. Traditionally, users seeking inspiration for their text-to-image prompts would manually browse through these libraries, often sifting through extensive lists of options. This process can be time-consuming and inefficient. By embedding prompts from the prompt library using text embedding models, companies can build a semantic search engine. Here’s how it works:
- Embedding prompts – The company uses text embeddings to convert each prompt in its library into a numerical representation. These embeddings capture the semantic meaning and context of the prompts.
- User query – When users provide their own prompts or describe their desired image, the system can analyze and embed their input as well.
- Semantic search – Using the embeddings, the system performs a semantic search. It retrieves the most relevant prompts from the library based on the user’s query, considering both the user’s input and historical data in the prompt library.
By implementing semantic search in their prompt libraries, companies empower their employees to access a vast reservoir of prompts effortlessly. This approach not only accelerates prompt creation but also encourages creativity and consistency in text-to-image generation.y
Prompt generation from semantic search
Although semantic search streamlines the process of finding relevant prompts, RAG takes it a step further by using these search results to generate optimized prompts. Here’s how it works:
- Semantic search results – After retrieving the most relevant prompts from the library, the system presents these prompts to the user, alongside the user’s original input.
- Text generation model – The user can select a prompt from the search results or provide further context on their preferences. The system feeds both the selected prompt and the user’s input into an LLM.
- Optimized prompt – The LLM, with its understanding of language nuances, crafts an optimized prompt that combines elements from the selected prompt and the user’s input. This new prompt is tailored to the user’s requirements and is designed to yield the desired image output.
The combination of semantic search and prompt generation not only simplifies the process of finding prompts but also ensures that the prompts generated are highly relevant and effective. It empowers you to fine-tune and customize your prompts, ultimately leading to improved text-to-image generation results. The following are examples of images generated from Stable Diffusion XL using the prompts from semantic search and prompt generation.
| Original Prompt | Prompts from Semantic Search | Optimized Prompt by LLM |
|
a cartoon of a little dog
|
|
A cartoon scene of a boy happily walking hand in hand down a forest lane with his cute pet dog, in animation style.
|



RAG-based prompt design applications across diverse industries
Before we explore the application of our suggested RAG architecture, let’s start with an industry in which an image generation model is most applicable. In AdTech, speed and creativity are critical. RAG-based prompt generation can add instant value by generating prompt suggestions to create many images quickly for an advertisement campaign. Human decision-makers can go through the auto-generated images to select the candidate image for the campaign. This feature can be a standalone application or embedded into popular software tools and platforms currently available.
Another industry where the Stable Diffusion model can enhance productivity is media and entertainment. The RAG architecture can assist in use cases of avatar creation, for example. Starting from a simple prompt, RAG can add much more color and characteristics to the avatar ideas. It can generate many candidate prompts and provide more creative ideas. From these generated images, you can find the perfect fit for the given application. It increases the productivity by automatically generating many prompt suggestions. The variation it can come up with is the immediate benefit of the solution.
Solution overview
Empowering customers to construct their own RAG-based ai assistant for prompt design on AWS is a testament to the versatility of modern technology. AWS provides a plethora of options and services to facilitate this endeavor. The following reference architecture diagram illustrates a RAG application for prompt design on AWS.

When it comes to selecting the right LLMs for your ai assistant, AWS offers a spectrum of choices to cater to your specific requirements.
Firstly, you can opt for LLMs available through SageMaker JumpStart, utilizing dedicated instances. These instances support a variety of models, including Falcon, Llama 2, Bloom Z, and Flan-T5, or you can explore proprietary models such as Cohere’s Command and Multilingual Embedding, or Jurassic-2 from AI21 Labs.
If you prefer a more simplified approach, AWS offers LLMs on Amazon Bedrock, featuring models like Amazon Titan and Anthropic Claude. These models are easily accessible through straightforward API calls, allowing you to harness their power effortlessly. The flexibility and diversity of options ensure that you have the freedom to choose the LLM that best aligns with your prompt design goals, whether you’re seeking an innovation with open containers or the robust capabilities of proprietary models.
When it comes to building the essential vector database, AWS provides a multitude of options through their native services. You can opt for Amazon OpenSearch Service, Amazon Aurora, or Amazon Relational Database Service (Amazon RDS) for PostgreSQL, each offering robust features to suit your specific needs. Alternatively, you can explore products from AWS partners like Pinecone, Weaviate, Elastic, Milvus, or Chroma, which provide specialized solutions for efficient vector storage and retrieval.
To help you get started to construct a RAG-based ai assistant for prompt design, we’ve put together a comprehensive demonstration in our GitHub repository. This demonstration uses the following resources:
- Image generation: Stable Diffusion XL on Amazon Bedrock
- Text embedding: Amazon Titan on Amazon Bedrock
- Text generation: Claude 2 on Amazon Bedrock
- Vector database: FAISS, an open source library for efficient similarity search
- Prompt library: Prompt examples from DiffusionDB, the first large-scale prompt gallery dataset for text-to-image generative models
Additionally, we’ve incorporated LangChain for LLM implementation and Streamit for the web application component, providing a seamless and user-friendly experience.
Prerequisites
You need to have the following to run this demo application:
- An AWS account
- Basic understanding of how to navigate Amazon SageMaker Studio
- Basic understanding of how to download a repo from GitHub
- Basic knowledge of running a command on a terminal
Run the demo application
You can download all the necessary code with instructions from the GitHub repo. After the application is deployed, you will see a page like the following screenshot.
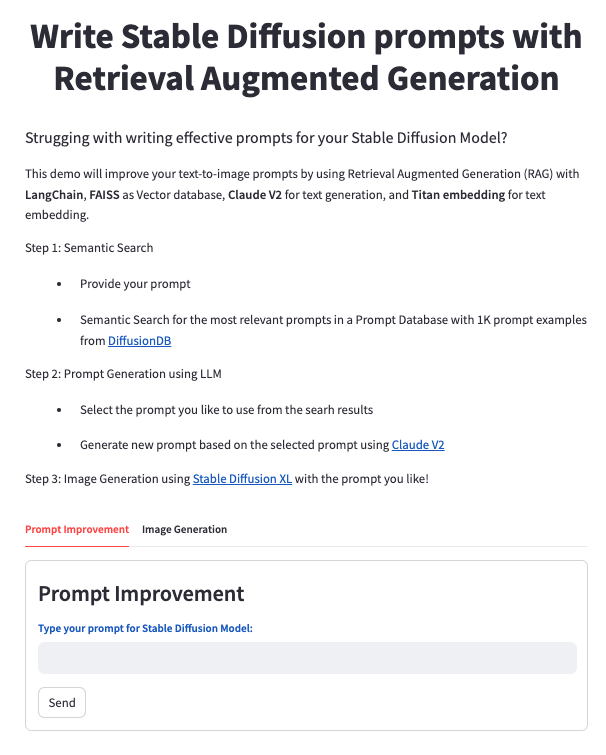
With this demonstration, we aim to make the implementation process accessible and comprehensible, providing you with a hands-on experience to kickstart your journey into the world of RAG and prompt design on AWS.
Clean up
After you try out the app, clean up your resources by stopping the application.
Conclusion
RAG has emerged as a game-changing paradigm in the world of prompt design, revitalizing Stable Diffusion’s text-to-image capabilities. By harmonizing RAG techniques with existing approaches and using the robust resources of AWS, we’ve uncovered a pathway to streamlined creativity and accelerated learning.
For additional resources, visit the following:
About the authors
 James Yi is a Senior ai/ML Partner Solutions Architect in the Emerging Technologies team at Amazon Web Services. He is passionate about working with enterprise customers and partners to design, deploy and scale ai/ML applications to derive their business values. Outside of work, he enjoys playing soccer, traveling and spending time with his family.
James Yi is a Senior ai/ML Partner Solutions Architect in the Emerging Technologies team at Amazon Web Services. He is passionate about working with enterprise customers and partners to design, deploy and scale ai/ML applications to derive their business values. Outside of work, he enjoys playing soccer, traveling and spending time with his family.
 Rumi Olsen is a Solutions Architect in the AWS Partner Program. She specializes in serverless and machine learning solutions in her current role, and has a background in natural language processing technologies. She spends most of her spare time with her daughter exploring the nature of Pacific Northwest.
Rumi Olsen is a Solutions Architect in the AWS Partner Program. She specializes in serverless and machine learning solutions in her current role, and has a background in natural language processing technologies. She spends most of her spare time with her daughter exploring the nature of Pacific Northwest.





{kind=link}