
Recent large language models (LLMs) have enabled tremendous progress in natural language understanding. However, they are prone to generating confident but nonsensical explanations, which poses a significant obstacle to establishing trust with users. In this post, we show how to incorporate human feedback on the incorrect reasoning chains for multi-hop reasoning to improve performance on these tasks. Instead of collecting the reasoning chains from scratch by asking humans, we instead learn from rich human feedback on model-generated reasoning chains using the prompting abilities of the LLMs. We collect two such datasets of human feedback in the form of (correction, explanation, error type) for StrategyQA and Sports Understanding datasets, and evaluate several common algorithms to learn from such feedback. Our proposed methods perform competitively to chain-of-thought prompting using the base Flan-T5, and ours is better at judging the correctness of its own answer.
Solution overview
With the onset of large language models, the field has seen tremendous progress on various natural language processing (NLP) benchmarks. Among them, the progress has been striking on relatively simpler tasks such as short context or factual question answering, compared to harder tasks that require reasoning such as multi-hop question answering. The performance of certain tasks using LLMs may be similar to random guessing at smaller scales, but improves significantly at larger scales. Despite this, the prompting abilities of LLMs have the potential to provide some relevant facts required to answer the question.
However, those models may not reliably generate correct reasoning chains or explanations. Those confident but nonsensical explanations are even more prevalent when LLMs are trained using Reinforcement Learning from Human Feedback (RLHF), where reward hacking may occur.
Motivated by this, we try to address the following research question: can we improve reasoning of LLMs by learning from human feedback on model-generated reasoning chains? The following figure provides an overview of our approach: we first prompt the model to generate reasoning chains for multi-hop questions, then collect diverse human feedback on these chains for diagnosis and propose training algorithms to learn from the collected data.
We collect diverse human feedback on two multi-hop reasoning datasets, StrategyQA and Sports Understanding from BigBench. For each question and model-generated reasoning chain, we collect the correct reasoning chain, the type of error in the model-generated reasoning chain, and a description (in natural language) of why that error is presented in the provided reasoning chain. The final dataset contains feedback for 1,565 samples from StrategyQA and 796 examples for Sports Understanding.
We propose multiple training algorithms to learn from the collected feedback. First, we propose a variant of self-consistency in chain-of-thought prompting by considering a weighted variant of it that can be learned from the feedback. Second, we propose iterative refinement, where we iteratively refine the model-generated reasoning chain until it’s correct. We demonstrate empirically on the two datasets that fine-tuning an LLM, namely Flan-T5 using the proposed algorithms, performs comparably to the in-context learning baseline. More importantly, we show that the fine-tuned model is better at judging if its own answer is correct compared to the base Flan-T5 model.
Data collection
In this section, we describe the details of the feedback we collected and the annotation protocol followed during data collection. We collected feedback for model generations based on two reasoning-based datasets: StrategyQA and Sports Understanding from BigBench. We used GPT-J to generate the answer for StrategyQA and Flan-T5 to generate the answer for the Sports Understanding dataset. In each case, the model was prompted with k in-context examples containing question, answer, and explanation, followed by the test question.
The following figure shows the interface we used. Annotators are given the question, the model-generated answer, and the explanation split into steps.
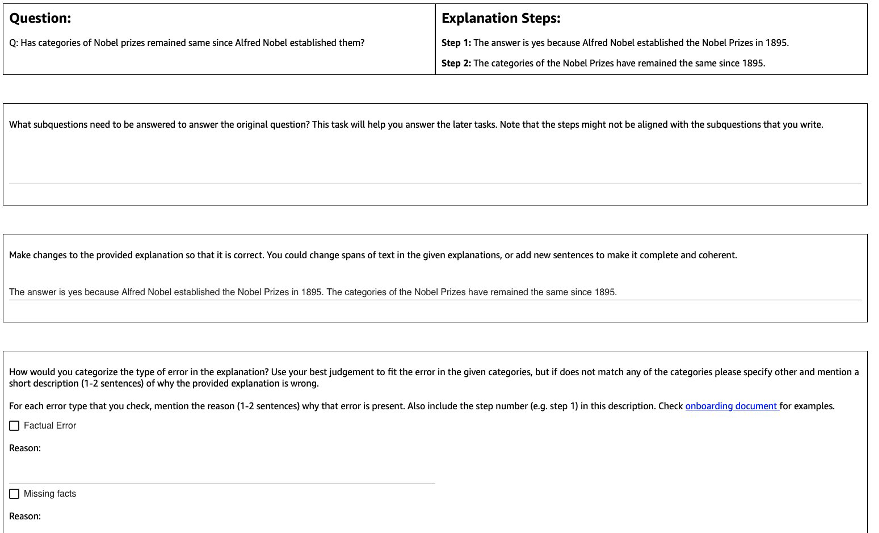
For each question, we collected the following feedback:
- Subquestions – The annotators decompose the original question into simpler subquestions required to answer the original question. This task was added after a pilot where we found that adding this task helps prepare the annotators and improve the quality of the rest of the tasks.
- Correction – Annotators are provided with a free-form text box pre-filled with the model-generated answer and explanation, and asked to edit it to obtain the correct answer and explanation.
- Error type – Among the most common types of error we found in the model generations (Factual Error, Missing Facts, Irrelevant Facts, and Logical Inconsistency), annotators were asked to pick one or more of the error types that apply to the given answer and explanation.
- Error description – The annotators were instructed to not only classify the errors but also give a comprehensive justification for their categorization, including pinpointing the exact step where the mistake occurred and how it applies to the answer and explanation provided.
We used Amazon SageMaker Ground Truth Plus in our data collection. The data collection took place over multiple rounds. We first conducted two small pilots of 30 examples and 200 examples, respectively, after which the annotator team was given detailed feedback on the annotation. We then conducted the data collection over two batches for StrategyQA, and over one batch for Sports Understanding, giving periodic feedback throughout—a total of 10 annotators worked on the task over a period of close to 1 month.
We gathered feedback on a total of 1,565 examples for StrategyQA and 796 examples for Sports Understanding. The following table illustrates the percentage of examples that were error-free in the model generation and the proportion of examples that contained a specific error type. It’s worth noting that some examples may have more than one error type.
| Error Type | StrategyQA | Sports Understanding |
| None | 17.6% | 31.28% |
| Factual Error | 27.6% | 38.1% |
| Missing Facts | 50.4% | 46.1% |
| Irrelevant Facts | 14.6% | 3.9% |
| Logical Inconsistency | 11.2% | 5.2% |
Learning algorithms
For each question q, and model-generated answer and explanation m, we collected the following feedback: correct answer and explanation c, type of error present in m (denoted by t), and error description d, as described in the previous section.
We used the following methods:
- Multitask learning – A simple baseline to learn from the diverse feedback available is to treat each of them as a separate task. More concretely, we fine-tune Flan-T5 (text to text) with the objective maximize p(c|q) + p(t|q, m) + p(d|q, m). For each term in the objective, we use a separate instruction appropriate for the task (for example, “Predict error in the given answer”). We also convert the categorical variable t into a natural language sentence. During inference, we use the instruction for the term p(c|q) (“Predict the correct answer for the given question”) to generate the answer for the test question.
- Weighted self-consistency – Motivated by the success of self-consistency in chain-of-thought prompting, we propose a weighted variant of it. Instead of treating each sampled explanation from the model as correct and considering the aggregate vote, we instead first consider whether the explanation is correct and then aggregate accordingly. We first fine-tune Flan-T5 with the same objective as in multitask learning. During inference, given a test question q, we sample multiple possible answers with the instruction for p(c|q)): a1, a2, .., an. For each sampled answer ai, we use the instruction for the term p(t|q, m) (“Predict error in the given answer”) to identify if it contains error ti = argmax p(t|q, a_i). Each answer ai is assigned a weight of 1 if it’s correct, otherwise it’s assigned a weight smaller than 1 (tunable hyperparameter). The final answer is obtained by considering a weighted vote over all the answers a1 to an.
- Iterative refinement – In the previous proposed methods, the model directly generates the correct answer c conditioned on the question q. Here we propose to refine the model-generated answer m to obtain the correct answer for a given question. More specifically, we first fine-tune Flan-T5 (text to text with the objective) with maximize p(t; c|q, m), where ; denotes the concatenation (error type t followed by the correct answer c). One way to view this objective is that the model is first trained to identify the error in given generation m, and then to remove that error to obtain the correct answer c. During inference, we can use the model iteratively until it generates the correct answer—given a test question q, we first obtain the initial model generation m (using pre-trained Flan-T5). We then iteratively generate the error type ti and potential correct answer ci until ti = no error (in practice, we set a maximum number of iterations to a hyperparameter), in which case the final correct answer will be ci-1 (obtained from p(ti ; ci | q, ci-1)).
Results
For both datasets, we compare all the proposed learning algorithms with the in-context learning baseline. All models are evaluated on the dev set of StrategyQA and Sports Understanding. The following table shows the results.
| Method | StrategyQA | Sports Understanding |
| Flan-T5 4-shot Chain-of-Thought In-Context Learning | 67.39 ± 2.6% | 58.5% |
| Multitask Learning | 66.22 ± 0.7% | 54.3 ± 2.1% |
| Weighted Self Consistency | 61.13 ± 1.5% | 51.3 ± 1.9% |
| Iterative Refinement | 61.85 ± 3.3% | 57.0 ± 2.5% |
As observed, some methods perform comparable to the in-context learning baseline (multitask for StrategyQA, and iterative refinement for Sports Understanding), which demonstrates the potential of gathering ongoing feedback from humans on model outputs and using that to improve language models. This is different from recent work such as RLHF, where the feedback is limited to categorical and usually binary.
As shown in the following table, we investigate how models adapted with human feedback on reasoning mistakes can help improve the calibration or the awareness of confidently wrong explanations. This is evaluated by prompting the model to predict if its generation contains any errors.
| Method | Error Correction | StrategyQA |
| Flan-T5 4-shot Chain-of-Thought In-Context Learning | No | 30.17% |
| Multitask Finetuned Model | Yes | 73.98% |
In more detail, we prompt the language model with its own generated answer and reasoning chain (for which we collected feedback), and then prompt it again to predict the error in the generation. We use the appropriate instruction for the task (“Identify error in the answer”). The model is scored correctly if it predicts “no error” or “correct” in the generation if the annotators labeled the example as having no error, or if it predicts any of the error types in the generation (along with “incorrect” or “wrong”) when the annotators labeled it as having an error. Note that we don’t evaluate the model’s ability to correctly identify the error type, but rather if an error is present. The evaluation is done on a set of 173 additional examples from the StrategyQA dev set that were collected, which aren’t seen during fine-tuning. Four examples out of these are reserved for prompting the language model (first row in the preceding table).
Note that we do not show the 0-shot baseline result because the model is unable to generate useful responses. We observe that using human feedback for error correction on reasoning chains can improve the model’s prediction of whether it makes errors or not, which can improve the awareness or calibration of the wrong explanations.
Conclusion
In this post, we showed how to curate human feedback datasets with fine-grained error corrections, which is an alternative way to improve the reasoning abilities of LLMs. Experimental results corroborate that human feedback on reasoning errors can improve performance and calibration on challenging multi-hop questions.
If you’re looking for human feedback to improve your large language models, visit Amazon SageMaker Data Labeling and the Ground Truth Plus console.
About the Authors
 Erran Li is the applied science manager at humain-in-the-loop services, AWS AI, Amazon. His research interests are 3D deep learning, and vision and language representation learning. Previously he was a senior scientist at Alexa AI, the head of machine learning at Scale AI and the chief scientist at Pony.ai. Before that, he was with the perception team at Uber ATG and the machine learning platform team at Uber working on machine learning for autonomous driving, machine learning systems and strategic initiatives of AI. He started his career at Bell Labs and was adjunct professor at Columbia University. He co-taught tutorials at ICML’17 and ICCV’19, and co-organized several workshops at NeurIPS, ICML, CVPR, ICCV on machine learning for autonomous driving, 3D vision and robotics, machine learning systems and adversarial machine learning. He has a PhD in computer science at Cornell University. He is an ACM Fellow and IEEE Fellow.
Erran Li is the applied science manager at humain-in-the-loop services, AWS AI, Amazon. His research interests are 3D deep learning, and vision and language representation learning. Previously he was a senior scientist at Alexa AI, the head of machine learning at Scale AI and the chief scientist at Pony.ai. Before that, he was with the perception team at Uber ATG and the machine learning platform team at Uber working on machine learning for autonomous driving, machine learning systems and strategic initiatives of AI. He started his career at Bell Labs and was adjunct professor at Columbia University. He co-taught tutorials at ICML’17 and ICCV’19, and co-organized several workshops at NeurIPS, ICML, CVPR, ICCV on machine learning for autonomous driving, 3D vision and robotics, machine learning systems and adversarial machine learning. He has a PhD in computer science at Cornell University. He is an ACM Fellow and IEEE Fellow.
 Nitish Joshi was an applied science intern at AWS AI, Amazon. He is a PhD student in computer science at New York University’s Courant Institute of Mathematical Sciences advised by Prof. He He. He works on Machine Learning and Natural Language Processing, and he was affiliated with the Machine Learning for Language (ML2) research group. He was broadly interested in robust language understanding: both in building models which are robust to distribution shifts (e.g. through human-in-the-loop data augmentation) and also in designing better ways to evaluate/measure the robustness of models. He has also been curious about the recent developments in in-context learning and understanding how it works.
Nitish Joshi was an applied science intern at AWS AI, Amazon. He is a PhD student in computer science at New York University’s Courant Institute of Mathematical Sciences advised by Prof. He He. He works on Machine Learning and Natural Language Processing, and he was affiliated with the Machine Learning for Language (ML2) research group. He was broadly interested in robust language understanding: both in building models which are robust to distribution shifts (e.g. through human-in-the-loop data augmentation) and also in designing better ways to evaluate/measure the robustness of models. He has also been curious about the recent developments in in-context learning and understanding how it works.
 Kumar Chellapilla is a General Manager and Director at Amazon Web Services and leads the development of ML/AI Services such as human-in-loop systems, AI DevOps, Geospatial ML, and ADAS/Autonomous Vehicle development. Prior to AWS, Kumar was a Director of Engineering at Uber ATG and Lyft Level 5 and led teams using machine learning to develop self-driving capabilities such as perception and mapping. He also worked on applying machine learning techniques to improve search, recommendations, and advertising products at LinkedIn, Twitter, Bing, and Microsoft Research.
Kumar Chellapilla is a General Manager and Director at Amazon Web Services and leads the development of ML/AI Services such as human-in-loop systems, AI DevOps, Geospatial ML, and ADAS/Autonomous Vehicle development. Prior to AWS, Kumar was a Director of Engineering at Uber ATG and Lyft Level 5 and led teams using machine learning to develop self-driving capabilities such as perception and mapping. He also worked on applying machine learning techniques to improve search, recommendations, and advertising products at LinkedIn, Twitter, Bing, and Microsoft Research.






{kind=link}