
Machine translation (MT) allows people to connect with others and interact with content across language barriers. Grammatical gender presents a difficult challenge for these systems, as some languages require specificity for terms that may be ambiguous or neutral in other languages. For example, when translating the English word “nurse” into Spanish, you must decide whether the feminine word “enfermera” or the masculine word “enfermero” is appropriate. However, particularly when there are no contextual clues, such as when translating a single sentence, a model cannot determine which one would be correct. This challenge is especially prevalent in many European languages, which often require gender specificity not only for professional titles, but also for terms such as child, friend, and member, as well as sometimes for animals. Often machine translation systems will be biased towards the most frequent gender form in their training data, but in addition to not necessarily providing an accurate translation for the user, this can inadvertently reinforce harmful social stereotypes.
To address this issue and give people more control over grammatical gender in machine translations, we presented Generating Gender Alternatives in Machine Translation at GeBNLP 2024 (Workshop on Gender Bias in NLP). Our approach trains translation models that give users fine-grained control over how gender entities are translated, without requiring additional components or inference overhead. With our method, a single translation inference step provides all grammatically correct alternatives for gender terms, allowing the user to select the most appropriate one for their context. In addition to publishing this work, we have published training and test data sets to allow the broader ML community to more easily develop systems that allow such control over the translation of gender entities.
At Apple, we have also taken advantage of this research advancement to benefit Apple users. Translate application, which uses the underlying method to enhance the “grammatical gender” function. Currently, this feature allows users to choose the most appropriate translations from all possible combinations when translating English content with ambiguous gender entities into Spanish, French, or Portuguese.
Addressing the challenge of grammatical gender in machine translation
Previous work simplified the problem by producing only “all male” or “all female” translations, that is, forcing all entities in the translation to be of the same gender. However, requiring that both “doctor” and “nurse” in the phrase “The doctor met the nurse” be either male or female obviously does not provide adequate flexibility.
A central challenge in giving users control over the grammatical gender of translated terms is the number of possible combinations. For (n) gender entities, there are 2north possible translations. For the short example sentence above with only two entities, there are four possible Spanish translations, depending on the gender options for “nurse” and “doctor”; However, if there were four entities, there would be 16 possible translations. Previous approaches have used specialized systems such as “ambiguous entity detection” and/or “rewriters” at inference time to provide translations of different genres, but these systems have additional computational overhead at inference time, introduce latency additional and do not scale well to handle all possible combinations.
Instead of using those systems at inference time, our approach uses them to distill training data for our translation models. During the distillation process, these specialized systems add gender structure and alignment information to the training data. (see Figure 1). Each gender-sensitive phrase translates into a “gender structure” with both masculine and feminine forms. These gender structures are also aligned with the corresponding ambiguous gender entity in the source sentence that controls its form.
Source sentence in English
Spanish translation
With gender structures and alignments
The different forms of gender-sensitive phrases such as “The host/The hostess”, “the painter/the painter” are structured together as gender structures. Each gender structure is aligned with its corresponding ambiguous gender entity (shown here by color coding). Given a translation containing genre structures and alignments, translations corresponding to any combination of genre options can be easily derived.
By training on this data distilled with gender structures and alignments, our translation models learn to provide a single translation with the appropriate grammatical gender alternatives, without requiring any additional components that would add computational overhead and latency at inference time.
New resources for the research community
To enable the research community to build translation systems that generate gender alternatives, we have released supervised training data sets for five language pairs (English to Spanish, French, German, Russian, Portuguese) and evaluation benchmarks for six language pairs (those listed above, as well as English to Italian). These data sets contain gender ambiguity annotations in the original English sentences and gender alignment and structure annotations in the translations.
Give users control of grammatical gender in the translation app
At Apple, we've taken this advancement from research to production to improve Translate app experience for users (see Figure 2). With iOS 17, we ship the ““grammatical gender” characteristic, which is based on the underlying method of this research. Currently, the feature allows users to select the appropriate grammatical gender of ambiguous entities when translating from English to Spanish, French or Portuguese. Because our method trains a single translation model and does not require multiple full translations or other components at inference time, it does not incur additional computational overhead or introduce additional latency for users, and was suitable for production-scale applications. .
Figure 2A: How to control grammatical gender in the Translate application: find the function.
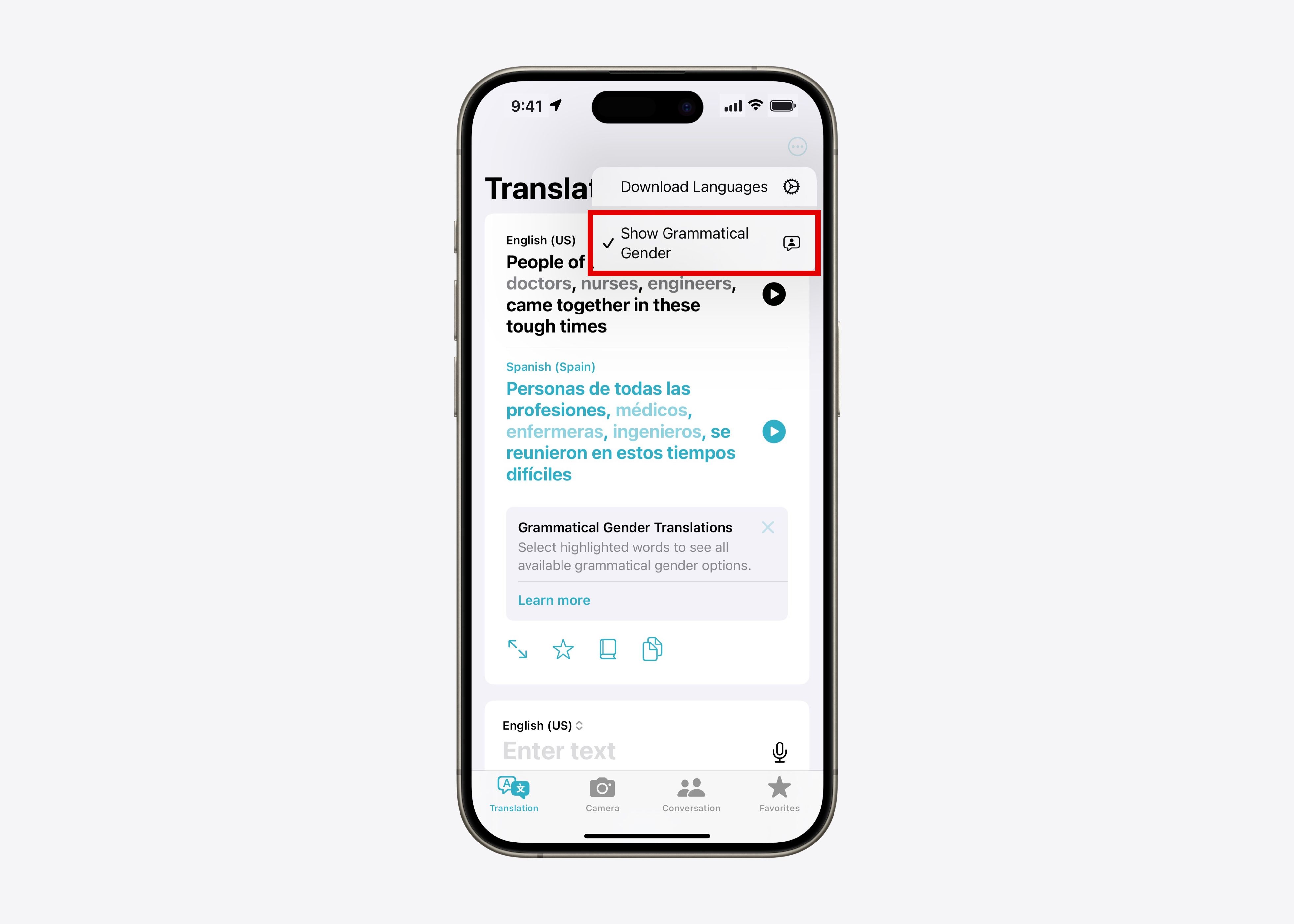
Figure 2B: How to control grammatical gender in the Translate application: by activating the function.
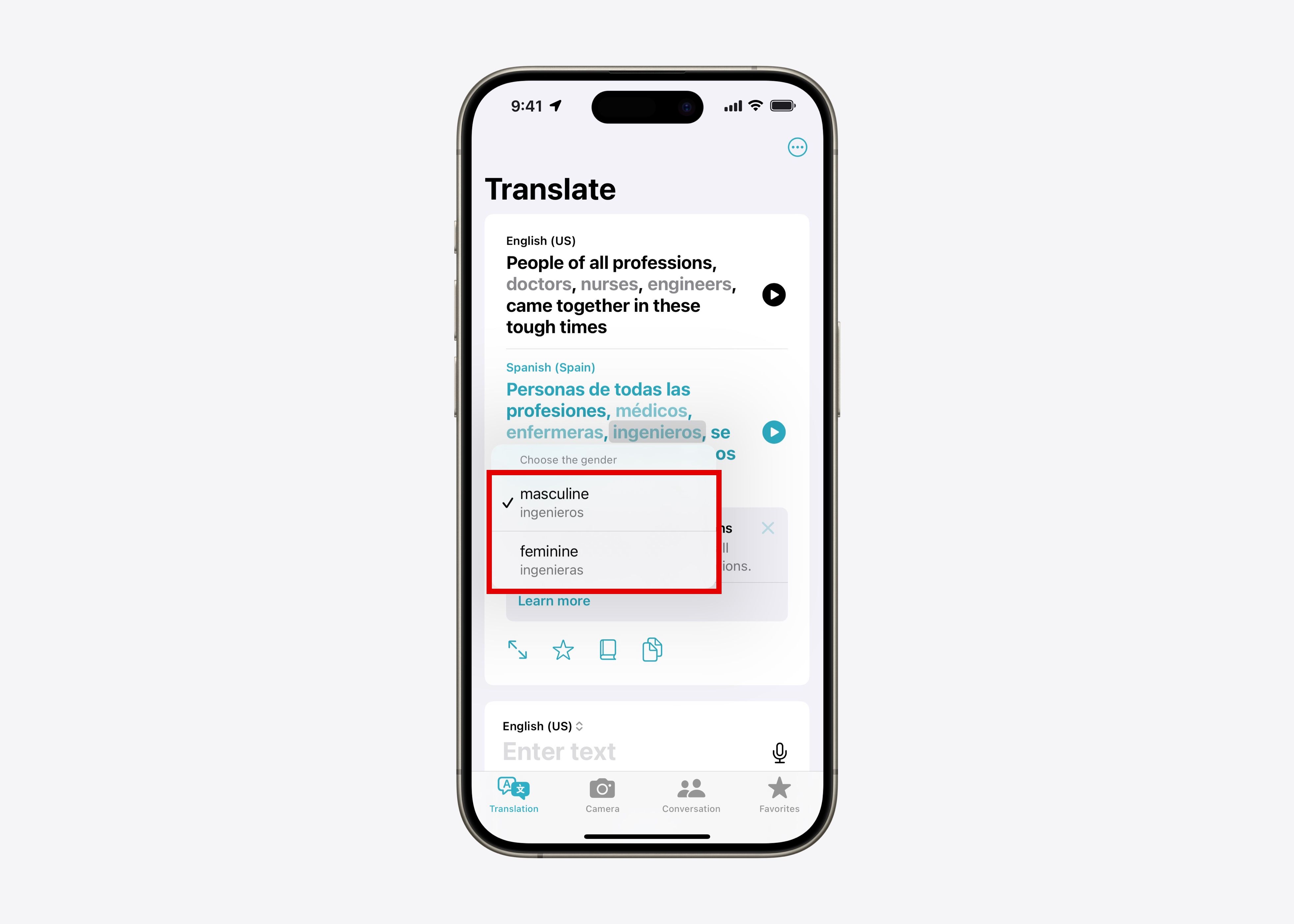
Figure 2C: How to control gender in the Translate app: by selecting gender.
Conclusion
Translating content with ambiguous gender entities into languages with gender-specific forms has been a challenge for machine translation and has often resulted in systems providing translations that reinforce social stereotypes reflected in the models' training data. Our research provides a new approach to training translation models, allowing them to provide all appropriate alternative translations for gender entities, without requiring additional components or computational overhead at inference time. Using this method, we have given users of the Translate app greater control over their translations, so that they can select the appropriate grammatical gender in cases of ambiguity when translating from English to various European languages.
While we have made significant progress on this issue in machine translation, additional challenges remain for future research, including expanding to additional language pairs, including gender-neutral forms, and adequately addressing non-binary gender identities. Our hope is that our publication and the new resources we have shared will help accelerate progress within the broader research community to continue improving translation systems for everyone.
Expressions of gratitude
Many people contributed to this project, including: Qin Gao, Sarthak Garg, Mozhdeh Gheini, Yi-Hsiu Liao, Tatiana Likhomanenko, Louie Livon-Bemel, Udhay Nallasamy, Alex Ovchinnikov, Matthias Paulik, Telmo Pessoa Pires and Hendra Setiawan.






{kind=link}