
In this post, we demonstrate the potential of large language model (LLM) debates using a supervised dataset with ground truth. In this LLM debate, we have two debater LLMs, each one taking one side of an argument and defending it based on the previous arguments for N(=3) rounds. The arguments are saved for a judge LLM to review. After N(=3) rounds, the same judge LLM with no access to original dataset but only with the LLM arguments decides which side is correct.
One challenging use case that can be addressed using this technique is scaling up the ground truth curation/alignment process for unsupervised and raw datasets. We can start with human annotation for labelling ground truth, but it can be expensive, slow, hard to scale, and may not reach consensus. We can also use this LLM debate generated synthetic ground truth data to build and pre-train larger and more powerful LLMs.
This post and the subsequent code implementation were inspired by one of the International Conference on Machine Learning (ICML) 2024 best papers on LLM debates Debating with More Persuasive LLMs Leads to More Truthful Answers. It uses a different dataset, <a target="_blank" href="https://github.com/amazon-science/tofueval” target=”_blank” rel=”noopener”>TofuEval.
Note that the question asked to the judge LLM for every technique is always the same: `Which one of these summaries is the most factually consistent one?” The answer is binary. Either Summary A or summary B is correct. For each of these techniques, the same judge LLM is used to give the final answer.
The LLM debating technique can be more factually consistent (truthful) over existing methods like LLM consultancy and standalone LLM inferencing with <a target="_blank" href="https://www.promptingguide.ai/techniques/consistency” target=”_blank” rel=”noopener”>self-consistency. To demonstrate this, we compare each of the four techniques mentioned below in this post:
- Naive Judge: This standalone LLM has no access to the transcript, but only the question and two summaries. It is used to measure the baseline performance on pre-trained LLM knowledge.
- Expert Judge: This LLM has access to the transcript along with the question and two summaries.
- LLM Consultancy: The standalone LLM defends one side of the summary choice for N(=3) rounds, expanding in more depth why it thinks it is correct in selecting the summary choice. After 3 rounds, a judge LLM with no access to transcript but only the LLM defense notes decides which summary choice is correct.
- LLM Debates: 2 LLMs each take one side of the argument and defends it based on the previous arguments for 3 rounds. After 3 rounds, a judge LLM with no access to the transcript but only with the LLM arguments decides which summary choice is correct.
As an overall solution, we use amazon Sagemaker and amazon Bedrock to invoke the different types of LLMs for each technique.
amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading ai companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral ai, Stability ai, and amazon through a single API, along with a broad set of capabilities you need to build generative ai applications with security, privacy, and responsible ai. Using amazon Bedrock, you can quickly experiment with and evaluate top FMs for your use case, privately customize them with your data using techniques such as fine-tuning and Retrieval Augmented Generation (RAG), and build agents that execute tasks using your enterprise systems and data sources. Since amazon Bedrock is serverless, you don’t have to manage the infrastructure, and you can securely integrate and deploy generative ai capabilities into your applications using the AWS services you are already familiar with.
Use-case overview
The overall task of each of the four techniques is to choose which one of the two summaries is most appropriate for a given transcript. There is a total of 10 transcripts and each transcript has 2 summaries – one correct and the other incorrect. Refer to the dataset section of this post for the generation details. The incorrect summaries have various classes of errors like Nuanced Meaning Shift, Extrinsic Information and Reasoning errors.
In this post, we navigate the LLM debating technique with persuasive LLMs having two expert debater LLMs (Anthropic Claude 3 Sonnet and Mixtral 8X7B) and one judge LLM (Mistral 7B v2 to measure, compare, and contrast its performance against other techniques like self-consistency (with naive and expert judges) and LLM consultancy.
The choice of judge and all other candidate LLMs can be varied from very small to large LLMs (based on model parameters) based on the nature of the use case, task complexity, dataset, and cost incurred. In this post, we have used at least 7B or greater parameter LLMs to demonstrate the overall efficacy of each technique as well as keeping cost in mind. It is possible to choose smaller LLMs depending on the task complexity; For example, if complex common-sense reasoning is not involved, we can choose Claude Haiku over Sonnet. Depending on the use-case, task complexity, dataset, and budget constraints, LLMs can be switched out to observe the performance changes (if any). The model cards for each LLM also serve as a good starting point to understand at which ML tasks each LLM excels. We recommend that these experiments along with choosing LLMs are tried out over diverse smaller subsets of the original dataset before scaling up.
To demonstrate the measurement and improvement of factual consistency (veracity) with explainability, we conduct a series of experiments with each of the four techniques to choose the best summary for each transcript. In each experiment with a different technique, we measure the factual consistency of the summaries generated from the transcripts and improve upon the decision to choose the correct one via methods like LLM consultancy and LLM debates.
The following question is repeated for all 3 rounds:
"Which one of these summaries is the most factually consistent one?"
Dataset
The dataset for this post is manually distilled from the amazon Science evaluation benchmark dataset called <a target="_blank" href="https://github.com/amazon-science/tofueval” target=”_blank” rel=”noopener”>TofuEval. For this post, 10 meeting transcripts have been curated from the MediaSum repository inside the TofuEval dataset. Details on the exact dataset can be found in the GitHub repository.
MediaSum is a large-scale media interview dataset containing 463.6K transcripts with abstractive summaries, collected from interview transcripts and overview / topic descriptions from NPR and CNN.
We use the following AWS services:
In the following sections, we demonstrate how to use the GitHub repository to run all of the techniques in this post.
Setup Prerequisites
To run this demo in your AWS account, complete the following prerequisites:
- Create an AWS account if you don’t already have one.
- Clone the GitHub repository and follow the steps explained in the README.
- Set up a SageMaker notebook using an AWS CloudFormation template, available in the GitHub repository. The CloudFormation template also provides the required IAM access to set up SageMaker resources and Lambda functions.
- Acquire access to models hosted on amazon Bedrock. Choose Manage model access in the navigation pane on the amazon Bedrock console and choose from the list of available options. We are invoking Anthropic Claude 3 Sonnet, Mistral 7B, and Mixtral 8X7B using amazon Bedrock for this post.
Solution overview
In this section, we will deep-dive into each of the four techniques being compared against each other.
- Naive Judge
- Expert Judge
- LLM Consultancy
- LLM Debates
Details of prompt used for each technique can be found here
Commonalities across all four techniques
- Each question is repeated for 3 rounds. This is to introduce LLM self-consistency. The majority answer is deemed correct.
- We flip the side of the argument the LLM takes for each round. This accounts for errors due to position bias (choosing an answer due to its order/position) and verbosity bias (one answer longer than the other).
Part 1: Standalone LLMs
In , we use a standalone LLM Mistral 7B to find out which of the two summaries is more factually consistent. There are 2 techniques: naïve judge and expert judge.
Technique 1: (Naive judge)
This standalone LLM chooses on one of the two summaries as the more factually consistent answer. It is used to measure the baseline performance on this dataset for a pretrained LLM like Mistral 7B. The visualization of the naive judge technique is as follows:
Naive Judge LLM
Prompt template for Naïve Judge

Naive Judge LLM Response
For each question, we ask the LLM number_of_rounds=3 times to follow a self-consistency paradigm.
Technique 2: (Expert judge)
Mistral 7B now becomes an expert judge with access to the transcripts and chooses which of the two summaries is the more factually consistent one. The visualization of the expert judge technique is as follows:
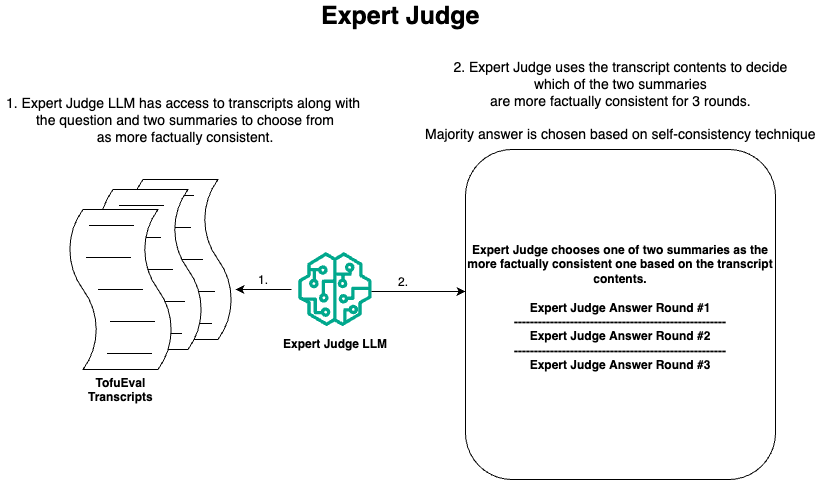
Expert Judge LLM Response
Prompt template for expert judge:

Expert Judge LLM response
For each question, we ask the LLM number_of_rounds=3 times to follow a self-consistency paradigm.
Technique 3: (LLM consultancy)
In , we use Anthropic Claude 3 Sonnet as an LLM consultant for both sides of the answers separately. In other words, in the first experiment the LLM consultant defends answer A for N(=3) and in the second experiment defends answer B for the N(=3) rounds. We take the average accuracy of both the experiments as final factual consistency accuracy. (Refer to the evaluation metrics section for accuracy definition) This continues for N(=3 in this notebook) rounds. We flip the argument sides for the consultant LLM and take the average of the experiments results as final accuracy. Refer to the Evaluation section to see how we calculate this accuracy.
The visualization of the LLM consultancy technique is as follows:
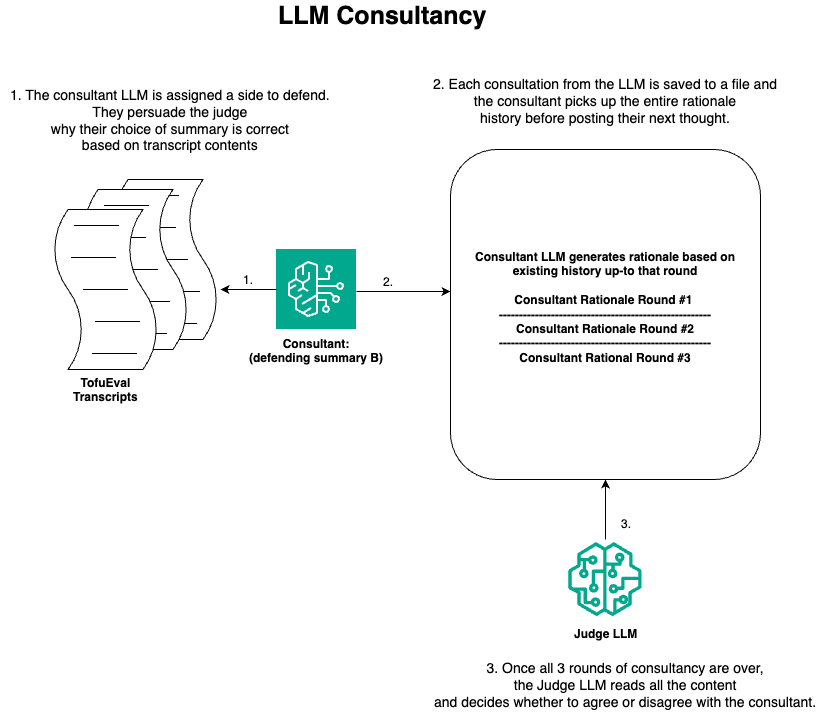
LLM Consultancy judge
Prompt template for LLM consultancy

LLM Consultancy Judge response
For each question, we ask the LLM number_of_rounds=3 times to follow a self-consistency paradigm.
Technique 4: (LLM Debate)
In , we use Anthropic Claude 3 Sonnet as the first debater and Mixtral 8X7B as the second debater with Mistral 7b as the judge. We let each debater argue their side for N(=3) rounds. Each round of debate is saved in a file. For the next round, each debater continues to defend their side based on the previous round’s argument. Once N(=3) rounds are over, the judge LLM uses only these arguments to decide which side is better. Now we flip Anthropic Claude 3 Sonnet (LLM-1) and Mixtral 8X7B (LLM-2) argument sides in both of the experiments and take the average of the experiment results as final accuracy. Refer to the Evaluation section to see how we calculate this accuracy.
The visualization of the LLM debate technique is as follows:
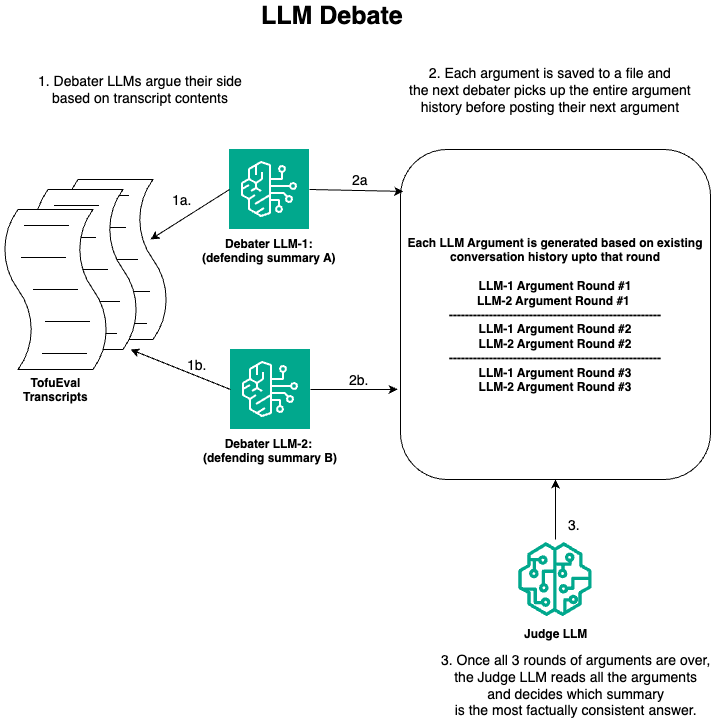
LLM Debate Judge
Prompt template for judge LLM

LLM Debate Judge Response
For each question, we ask the LLM number_of_rounds=3 times to follow a self-consistency paradigm.
Evaluation Metrics
Factual Consistency Accuracy (for all techniques):
For each question in every technique, the judge chooses whether summary A or B is True. As mentioned above, we also flip the position of summary A and B and repeat the same question to the same LLM. At the end of a run, we define the factual consistency accuracy as the number of times the judge chose the same answer regardless of its position being flipped (to account for position bias, verbosity bias, or random guess).
factual_consistency_accuracy = find_number_of_matching_elements(judge_regular_answers, judge_flipped_answers)/total_data_points
Finally, we compare the accuracy of each technique against each other.
Win rate per LLM (this metric only applies to LLM debates):
For the LLM debate, we can calculate the win rate of the LLM debaters to evaluate which of the LLMs got most of the answers right as adjudicated by the judge LLM. With this win rate of expert models, we empirically understand which LLM as a debater is more successful than the other. This metric may be used to choose one LLM over the other given a particular use case and dataset.
claude_avg_win_rate, mixtral_avg_win_rate = get_win_rate_per_model(debate_judge_regular_answers, debate_judge_flipped_answers)
Details about the win rate per model can be found in the GitHub repository here.
Cost considerations
The following are important cost considerations:
Conclusion
In this post, we demonstrated how LLM debate is a technique that can improve factual consistency. While it can be expensive to use three LLMs (two debaters and one judge), a potential direction could be scaling up the ground truth curation/alignment process for unsupervised/raw datasets for fine-tuning existing LLMs and building new LLMs.
From the examples in each of the techniques, we see the interpretability and rationale used by the LLMs in getting to the final answer. The naïve judge technique establishes a lower threshold of performance whereas the LLM debate technique is the most verbose providing a detailed explanation of how it got to the final answer. The expert judge technique outperforms the naïve judge and the LLM consultancy technique does better than the expert judge as shown in the figure below.
For many repeated runs across this small subset of TofuEval dataset, we observe the LLM debating technique out-performing the other techniques mentioned in this post. One entire end-to-end run snapshot of performance is as follows:
Compare accuracies across all four techniques
Depending on the use case and dataset volume, while we can start with human annotation, it can quickly become expensive, slow, and disagreement amongst human annotators can add layers of complexity. A scalable oversight direction could be this LLM debating technique to align on the ground truth options via this debating and critique mechanism thereby establishing factual consistency. However, before scaling up this technique for your use case, it is necessary to compare the LLM debate performance against human annotation over a diverse subset of the domain-specific dataset.
Readers are highly encouraged to switch LLMs that are apt for their use case with this debating technique. LLM debates need to be calibrated and aligned with human preference for the task and dataset. You can use amazon SageMaker Ground Truth for labeling jobs to record human preferences with their own private skilled work teams or use amazon SageMaker Ground Truth Plus for a fully managed experience for this human alignment task.
To learn more about customizing models with amazon Bedrock, see Customize your model to improve its performance for your use case.
Acknowledgements
The author thanks all the reviewers for their valuable feedback.
About the Author

Shayan Ray is an Applied Scientist at amazon Web Services. His area of research is all things natural language (like NLP, NLU, and NLG). His work has been focused on conversational ai, task-oriented dialogue systems and LLM-based agents. His research publications are on natural language processing, personalization, and reinforcement learning.





{kind=link}