
amazon Bedrock es un servicio completamente administrado que ofrece una selección de modelos base (FM) de alto rendimiento de empresas líderes de inteligencia artificial (IA) como AI21 Labs, Anthropic, Cohere, Meta, Stability ai y amazon a través de una única API, junto con un amplio conjunto de capacidades para crear aplicaciones de IA generativa con seguridad, privacidad e IA responsable.
Con amazon Bedrock, puede experimentar y evaluar los mejores FM para varios casos de uso. Le permite personalizarlos de forma privada con sus datos empresariales mediante técnicas como Retrieval Augmented Generation (RAG) y crear agentes que ejecuten tareas utilizando sus sistemas empresariales y fuentes de datos. Las bases de conocimiento para amazon Bedrock le permiten agregar fuentes de datos en un repositorio de información. Con las bases de conocimiento, puede crear sin esfuerzo una aplicación que aproveche RAG.
Acceder a información actualizada y completa de varios sitios web es fundamental para muchas aplicaciones de IA a fin de contar con datos precisos y relevantes. Los clientes que utilizan bases de conocimiento para amazon Bedrock desean ampliar la capacidad de rastrear e indexar sus sitios web públicos. Al integrar rastreadores web en la base de conocimiento, puede recopilar y utilizar estos datos web de manera eficiente. En esta publicación, exploramos cómo lograr esto sin inconvenientes.
Rastreador web para bases de conocimiento
Con una fuente de datos de rastreo web en la base de conocimientos, puede crear una aplicación web de IA generativa para sus usuarios finales en función de los datos del sitio web que rastrea mediante la consola de administración de AWS o la API. El comportamiento de rastreo predeterminado del conector web comienza con la obtención de las URL iniciales proporcionadas y, luego, recorre todos los enlaces secundarios dentro del mismo dominio principal superior (TPD) y que tengan la misma ruta de URL o una más profunda.
Las consideraciones actuales son que la URL no puede requerir ninguna autenticación, no puede ser una dirección IP para su host y su esquema debe comenzar con http:// o https://Además, el conector web recuperará archivos que no sean compatibles con HTML, como archivos PDF, archivos de texto, archivos Markdown y archivos CSV a los que se haga referencia en las páginas rastreadas, independientemente de su URL, siempre que no se excluyan explícitamente. Si se proporcionan varias URL de origen, el conector web rastreará una URL si se ajusta a la TPD y la ruta de cualquier URL de origen. Puede tener hasta 10 URL de origen, que la base de conocimientos utiliza como punto de partida para rastrear.
Sin embargo, el conector web no recorre páginas de distintos dominios de forma predeterminada. Sin embargo, el comportamiento predeterminado recuperará los archivos que no sean HTML compatibles. Esto garantiza que el proceso de rastreo se mantenga dentro de los límites especificados, manteniendo el foco y la relevancia para las fuentes de datos de destino.
Comprender el alcance de sincronización
Al configurar una base de conocimiento con funcionalidad de rastreo web, puede elegir entre diferentes tipos de sincronización para controlar qué páginas web se incluyen. La siguiente tabla muestra las rutas de ejemplo que se rastrearán según la URL de origen para diferentes ámbitos de sincronización (https://example.com se utiliza con fines ilustrativos).
| Tipo de alcance de sincronización | URL de origen | Ejemplo de rutas de dominio rastreadas | Descripción |
| Por defecto | https://example.com/products |
|
El mismo host y la misma ruta inicial que la URL de origen |
| Solo anfitrión | https://example.com/sellers |
|
El mismo host que la URL de origen |
| Subdominios | https://example.com |
|
Subdominio del dominio principal de las URL de origen |
Puede establecer la limitación máxima de la velocidad de rastreo para controlar la tasa máxima de rastreo. Los valores más altos reducirán el tiempo de sincronización. Sin embargo, el trabajo de rastreo siempre se ajustará a los parámetros del dominio. robots.txt archivo si hay alguno presente, respetando las directivas estándar de robots.txt como 'Permitir', 'No permitir' y velocidad de rastreo.
Puede refinar aún más el alcance de las URL que desea rastrear utilizando filtros de inclusión y exclusión. Estos filtros son patrones de expresiones regulares (regex) que se aplican a cada URL. Si una URL coincide con algún filtro de exclusión, se ignorará. Por el contrario, si se establecen filtros de inclusión, el rastreador solo procesará las URL que coincidan con al menos uno de estos filtros y que aún estén dentro del alcance. Por ejemplo, para excluir las URL que terminan en .pdfpuedes usar la expresión regular ^.*\.pdf$Para incluir solo las URL que contienen la palabra “productos”, puede utilizar la expresión regular .*products.*.
Descripción general de la solución
En las siguientes secciones, repasaremos los pasos necesarios para crear una base de conocimiento con un rastreador web y probarla. También mostramos cómo crear una base de conocimiento con un modelo de incrustación específico y una colección de vectores de amazon OpenSearch Service como base de datos de vectores, y analizamos cómo monitorear su rastreador web.
Prerrequisitos
Asegúrate de tener permiso para rastrear las URL que deseas utilizar y de cumplir con la Política de uso aceptable de amazon. Asegúrate también de que las funciones de detección de bots estén desactivadas para esas URL. Un rastreador web en una base de conocimiento utiliza el agente de usuario bedrockbot Al rastrear páginas web.
Crear una base de conocimientos con un rastreador web
Complete los siguientes pasos para implementar un rastreador web en su base de conocimientos:
- En la consola de amazon Bedrock, en el panel de navegación, seleccione Bases de conocimiento.
- Elegir Crear una base de conocimientos.
- Sobre el Proporcionar detalles de la base de conocimientos página, configure las siguientes configuraciones:
- Proporcione un nombre para su base de conocimientos.
- En el Permisos de IAM sección, seleccionar Crear y utilizar un nuevo rol de servicio.
- En el Elegir fuente de datos sección, seleccionar Rastreador web como fuente de datos.
- Elegir Próximo.
- Sobre el Configurar fuente de datos página, configure las siguientes configuraciones:
- Bajo URL de origeningresar
https://www.aboutamazon.com/news/amazon-offices. - Para Ámbito de sincronizaciónseleccionar Solo anfitrión.
- Para Incluir patronesingresar
^https?://www.aboutamazon.com/news/amazon-offices/.*$. - Para excluir el patrón, ingrese
.*plants.*(no queremos ninguna publicación cuya URL contenga la palabra “plantas”). - Para Fragmentación y análisis de contenidoeligió Por defecto.
- Elegir Próximo.
- Bajo URL de origeningresar
- Sobre el Seleccionar el modelo de incrustaciones y configurar el almacén de vectores página, configure las siguientes configuraciones:
- En el Modelo de incrustaciones sección, eligió Incorporaciones de texto Titan v2.
- Para Dimensiones vectorialesingresar
1024. - Para Base de datos de vectoreselegir Cree rápidamente una nueva tienda de vectores.
- Elegir Próximo.
- Revisa los detalles y elige Crear una base de conocimientos.
En las instrucciones anteriores, la combinación de Incluir patrones y Solo anfitrión El ámbito de sincronización se utiliza para demostrar el uso del patrón de inclusión para el rastreo web. Se pueden lograr los mismos resultados con el ámbito de sincronización predeterminado, como aprendimos en la sección anterior de esta publicación.
Puedes utilizar el Creación rápida de una tienda de vectores Opción al crear la base de conocimiento para crear una colección de búsquedas vectoriales de amazon OpenSearch Serverless. Con esta opción, se configura una colección de búsquedas vectoriales públicas y un índice vectorial con los campos y las configuraciones necesarios. Además, Knowledge Bases for amazon Bedrock administra los flujos de trabajo de consulta e ingesta de extremo a extremo.
Poner a prueba la base de conocimientos
Repasemos los pasos para probar la base de conocimientos con un rastreador web como fuente de datos:
- En la consola de amazon Bedrock, navegue hasta la base de conocimiento que creó.
- Bajo Fuente de datosseleccione el nombre de la fuente de datos y elija SincronizarLa sincronización podría tardar varios minutos u horas, dependiendo del tamaño de sus datos.
- Cuando se complete el trabajo de sincronización, en el panel derecho, debajo de Base de conocimientos de pruebaelegir Seleccionar modelo y selecciona el modelo de tu preferencia.
- Ingrese una de las siguientes indicaciones y observe la respuesta del modelo:
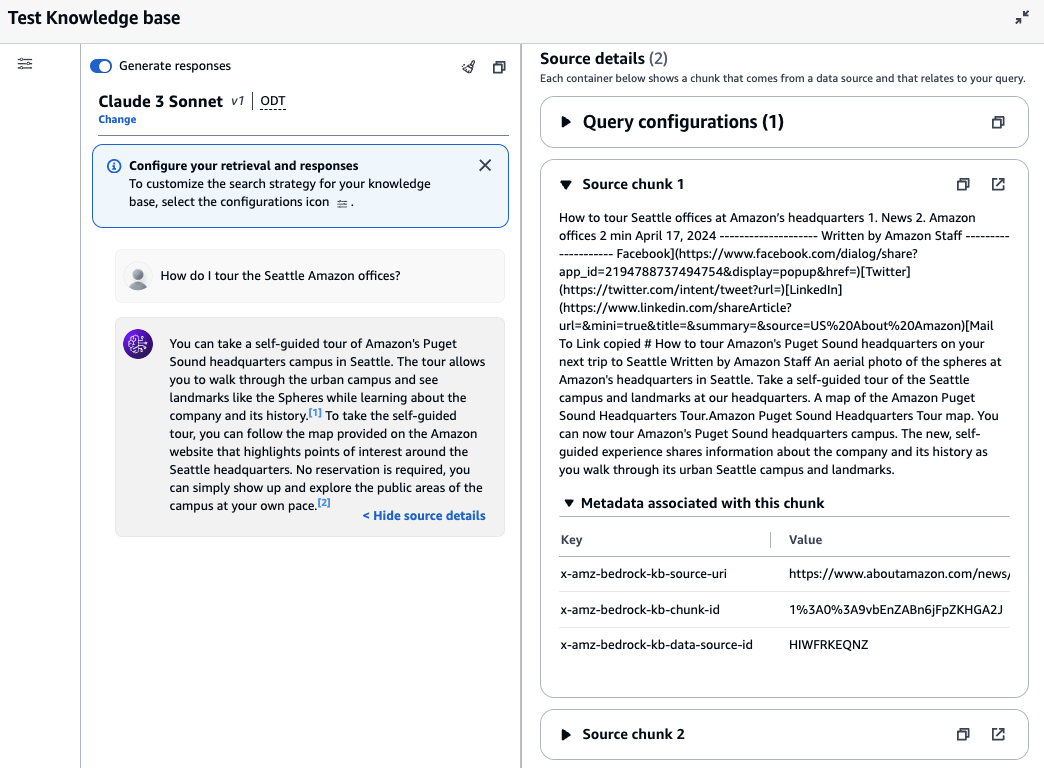
Como se muestra en la siguiente captura de pantalla, las citas se devuelven dentro de las páginas web de referencia de respuesta. El valor de x-amz-bedrock-kb-source-uri es un enlace a una página web que le ayuda a verificar la precisión de la respuesta.
Cree una base de conocimientos utilizando el SDK de AWS
El siguiente código utiliza el AWS SDK para Python (Boto3) para crear una base de conocimiento en amazon Bedrock con un modelo de integración específico y una colección de vectores de OpenSearch Service como base de datos de vectores:
El siguiente código Python utiliza Boto3 para crear una fuente de datos de rastreador web para una base de conocimiento de amazon Bedrock, especificando semillas de URL, límites de rastreo y filtros de inclusión y exclusión:
Supervisión
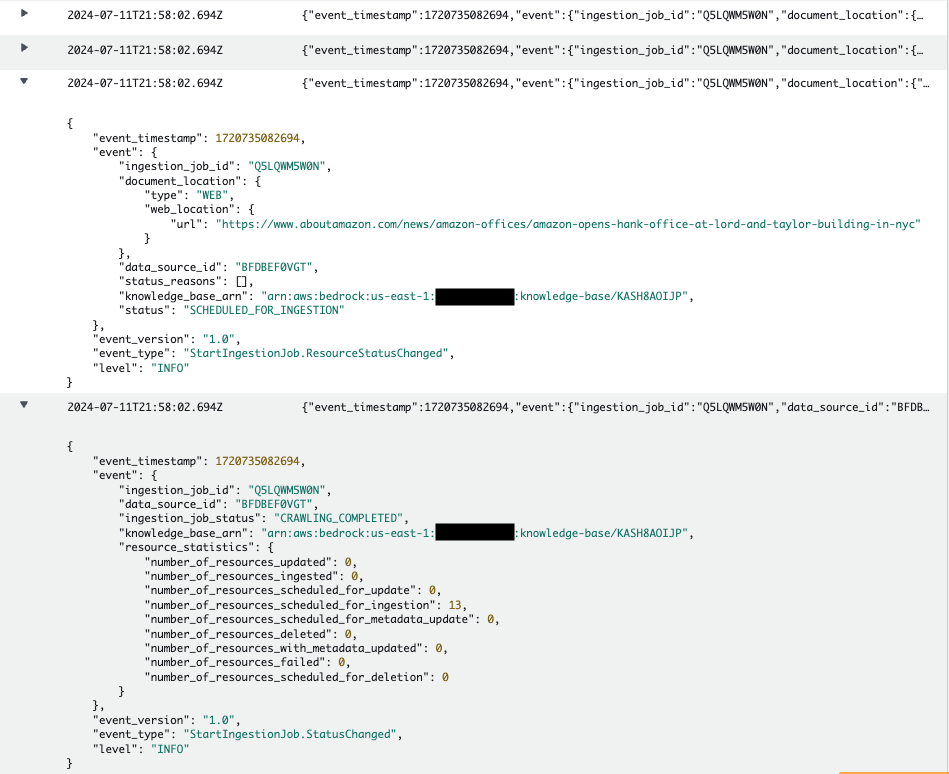
Puede realizar un seguimiento del estado de un rastreo web en curso en los registros de amazon CloudWatch, que deberían informar las URL que se visitan y si se recuperan correctamente, se omiten o fallan. La siguiente captura de pantalla muestra los registros de CloudWatch para el trabajo de rastreo.
Limpiar
Para limpiar sus recursos, complete los siguientes pasos:
- Eliminar la base de conocimientos:
- En la consola de amazon Bedrock, seleccione Bases de conocimiento bajo Orquestación en el panel de navegación.
- Seleccione la base de conocimientos que ha creado.
- Tome nota del nombre del rol del servicio AWS Identity and Access Management (IAM) en la descripción general de la base de conocimiento.
- En el Sección de base de datos de vectorestome nota del ARN de la colección OpenSearch Serverless.
- Elegir Borrarluego ingrese
deletepara confirmar.
- Eliminar la base de datos de vectores:
- En la consola del servicio OpenSearch, seleccione Colecciones bajo Sin servidor en el panel de navegación.
- Ingresa el ARN de la colección que guardaste en la barra de búsqueda.
- Seleccione la colección y elija Borrar.
- Ingresar
confirmEn el mensaje de confirmación, seleccione Borrar.
- Eliminar la función del servicio IAM:
- En la consola IAM, seleccione Roles en el panel de navegación.
- Busque el nombre del rol que anotó anteriormente.
- Seleccione el rol y elija Borrar.
- Ingrese el nombre del rol en el mensaje de confirmación y elimine el rol.
Conclusión
En esta publicación, mostramos cómo las bases de conocimiento para amazon Bedrock ahora admiten la fuente de datos web, lo que le permite indexar páginas web públicas. Esta función le permite rastrear e indexar sitios web de manera eficiente, de modo que su base de conocimiento incluya información diversa y relevante de la web. Al aprovechar la infraestructura de amazon Bedrock, puede mejorar la precisión y la eficacia de sus aplicaciones de IA generativa con datos actualizados y completos.
Para obtener información sobre precios, consulte Precios de amazon Bedrock. Para comenzar a utilizar las bases de conocimiento de amazon Bedrock, consulte Crear una base de conocimiento. Para obtener contenido técnico detallado, consulte Explorar páginas web para su base de conocimiento de amazon Bedrock. Para obtener más información sobre cómo nuestras comunidades de Builder utilizan amazon Bedrock en sus soluciones, visite nuestro sitio web. ai?trk=e8665609-785f-4bbe-86e8-750a3d3e9e61&sc_channel=el” target=”_blank” rel=”noopener”>comunidad.aws sitio web.
Sobre los autores
 Hardik Vasa es arquitecto de soluciones sénior en AWS. Se centra en la inteligencia artificial generativa y las tecnologías sin servidor, y ayuda a los clientes a aprovechar al máximo los servicios de AWS. Hardik comparte sus conocimientos en diversas conferencias y talleres. En su tiempo libre, disfruta aprendiendo sobre nuevas tecnologías, jugando videojuegos y pasando tiempo con su familia.
Hardik Vasa es arquitecto de soluciones sénior en AWS. Se centra en la inteligencia artificial generativa y las tecnologías sin servidor, y ayuda a los clientes a aprovechar al máximo los servicios de AWS. Hardik comparte sus conocimientos en diversas conferencias y talleres. En su tiempo libre, disfruta aprendiendo sobre nuevas tecnologías, jugando videojuegos y pasando tiempo con su familia.
 Malini Chatterjee es arquitecta de soluciones sénior en AWS. Brinda orientación a los clientes de AWS sobre sus cargas de trabajo en una variedad de tecnologías de AWS. Aporta una amplia experiencia en análisis de datos y aprendizaje automático. Antes de unirse a AWS, diseñaba soluciones de datos en industrias financieras. Le apasiona la danza semiclásica y actúa en eventos comunitarios. Le encanta viajar y pasar tiempo con su familia.
Malini Chatterjee es arquitecta de soluciones sénior en AWS. Brinda orientación a los clientes de AWS sobre sus cargas de trabajo en una variedad de tecnologías de AWS. Aporta una amplia experiencia en análisis de datos y aprendizaje automático. Antes de unirse a AWS, diseñaba soluciones de datos en industrias financieras. Le apasiona la danza semiclásica y actúa en eventos comunitarios. Le encanta viajar y pasar tiempo con su familia.






{kind=link}