 NEWSLETTER
NEWSLETTER
This is a guest post co-written with Ori Nakar of Imperva.
Imperva Cloud WAF protects hundreds of thousands of websites from cyber threats and blocks billions of security events every day. Counters and information based on security events are calculated daily and used by users in various departments. Millions of counters are added daily, along with 20 million insights updated daily to detect threat patterns.
Our goal was to improve the user experience of an existing application used to explore counters and information data. Data is stored in a data lake and retrieved by SQL using amazon Athena.
As part of our solution, we replaced multiple search fields with a single free text field. We use a large language model (LLM) with query examples so that the search works using the language used by Imperva's internal users (business analysts).
The following figure shows a search query translated to SQL and executed. The application then formatted the results as a graph. We have many types of information: global, industry and customer-level information used by multiple departments, such as marketing, support and research. Data was made available to our users through a simplified user experience powered by an LLM.
Figure 1: Search for insights by natural language
amazon Bedrock is a fully managed service that offers a selection of high-performance foundation models (FM) from leading artificial intelligence (ai) companies such as AI21 Labs, Anthropic, Cohere, Meta, Mistral, Stability ai, and amazon within a single API. , along with a broad set of capabilities you need to build generative ai applications with security, privacy, and responsible ai. amazon Bedrock Studio is a new single sign-on (SSO)-enabled web interface that provides a way for developers in an organization to experiment with LLM and other FMs, collaborate on projects, and iterate on generative ai applications. Provides a rapid prototyping environment and streamlines access to multiple FMs and development tools in amazon Bedrock.
Read more to learn about the problem and how we achieved quality results using amazon Bedrock for our experimentation and implementation.
The problem
Making data accessible to users through applications has always been a challenge. Data is typically stored in databases and can be queried using the most common query language, SQL. Applications use different user interface components to allow users to filter and query data. There are apps with dozens of different filters and other options, all created to make data accessible.
Querying databases through applications cannot be as flexible as running SQL queries against a known schema. Giving more power to the user comes down to a simple user experience (UX). Natural language can solve this problem: it is possible to support complex but readable natural language queries without knowledge of SQL. In schema changes, the app's UX and code remain the same, or with minor changes, saving development time and keeping the app's user interface (UI) stable for users.
Building SQL queries from natural language is not a simple task. SQL queries must be both syntactically and logically precise. Using an LLM with the right examples can make this task less difficult.
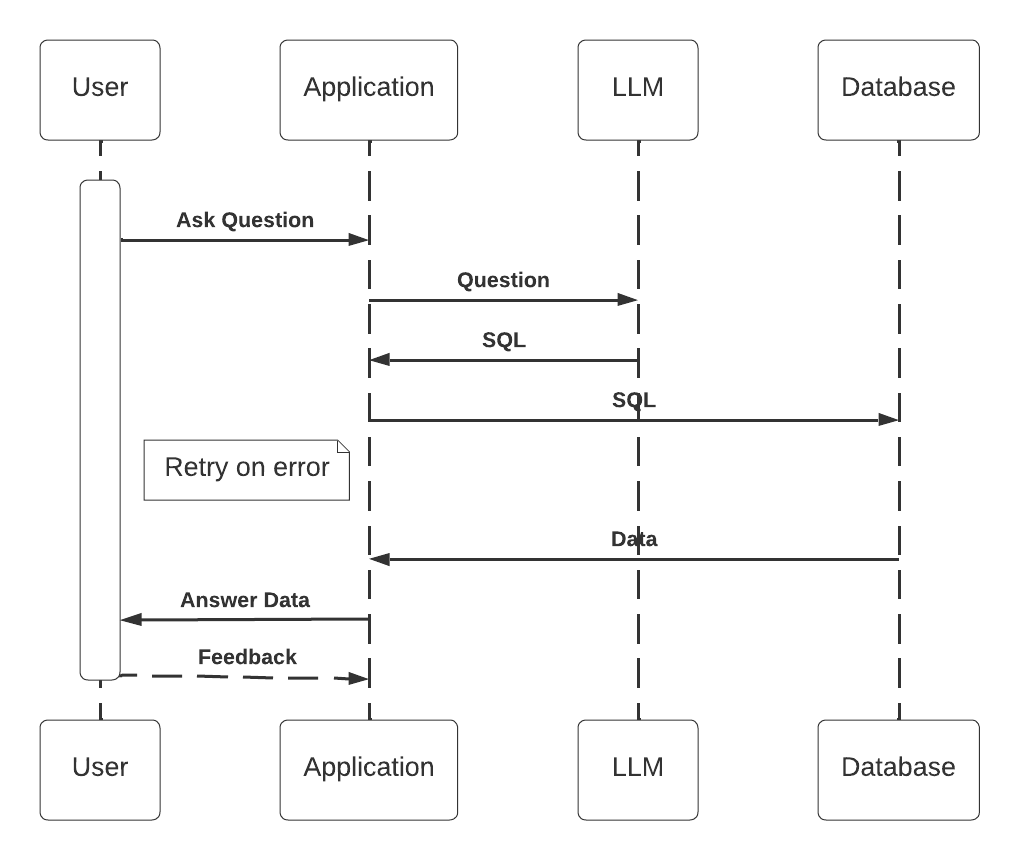
Figure 2: High-level database access using an LLM flow
The challenge
An LLM can build SQL queries based on natural language. The challenge is to ensure quality. The user can enter any text and the application builds a query based on it. There is no option, like in traditional applications, to cover all the options and make sure the application works correctly. Adding an LLM to an application adds another layer of complexity. The LLM response is not deterministic. The examples submitted to the LLM are based on data in the database, which makes it even more difficult to control the requests submitted to the LLM and ensure quality.
The solution: a data science approach
In data science, it is common to develop a model and tune it through experimentation. The idea is to use metrics to compare experiments during development. Experiments can differ from each other in many aspects, such as the input sent to the model, the type of model, and other parameters. The ability to compare different experiments allows progress. It is possible to know how each change contributes to the model.
A test set is a static set of records that includes a prediction result for each record. Running predictions on the test set records the results with the metrics necessary to compare experiments. A common metric is precision, which is the percentage of correct results.
In our case, the results generated by the LLM are SQL statements. The SQL statements generated by the LLM are non-deterministic and difficult to measure; however, running SQL statements against a static test database is deterministic and measurable. We use a test database and a list of questions with known answers as the test set. It allowed us to conduct experiments and fine-tune our LLM-based application.
Database Access through LLM: Question to Answer Flow
When faced with a question we define the following flow. The question is sent through a retrieval augmented generation (RAG) process, which finds similar documents. Each document contains an example question and information about it. The relevant documents are created as a message and sent to the LLM, which generates an SQL statement. This flow is used for both development and runtime of the application:
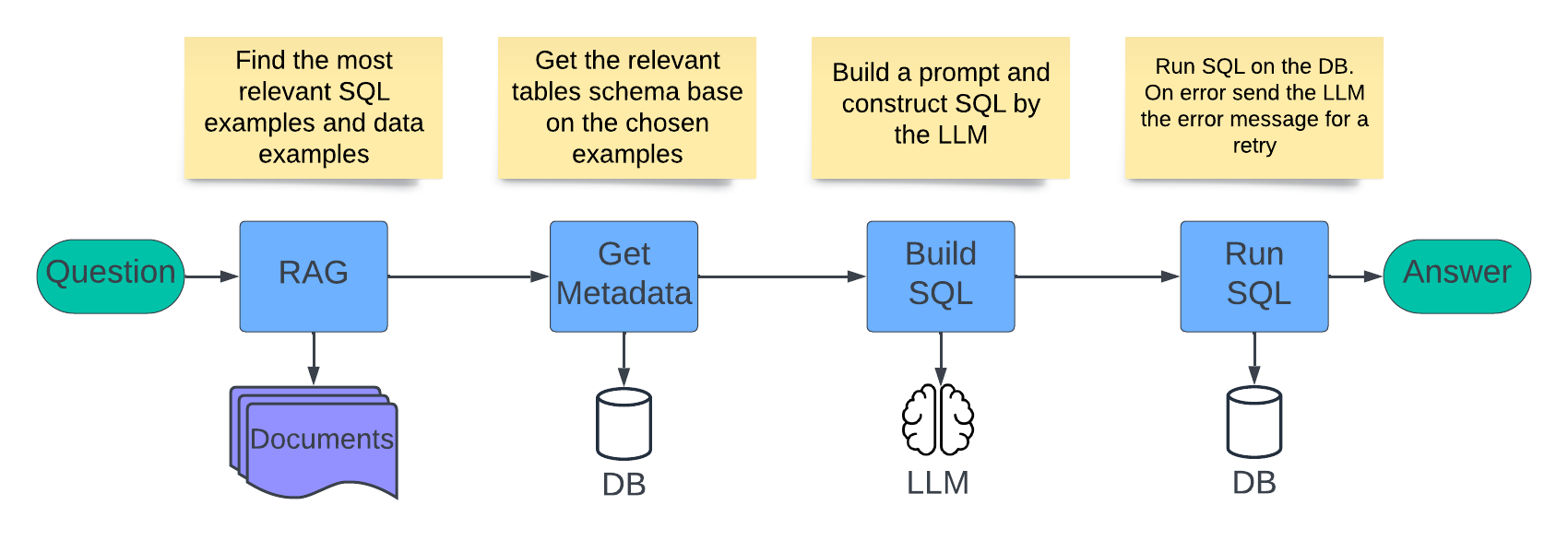
Figure 3: Flow from question to answer
As an example, consider a database schema with two tables: orders and items. The following figure is a question for the SQL example flow:
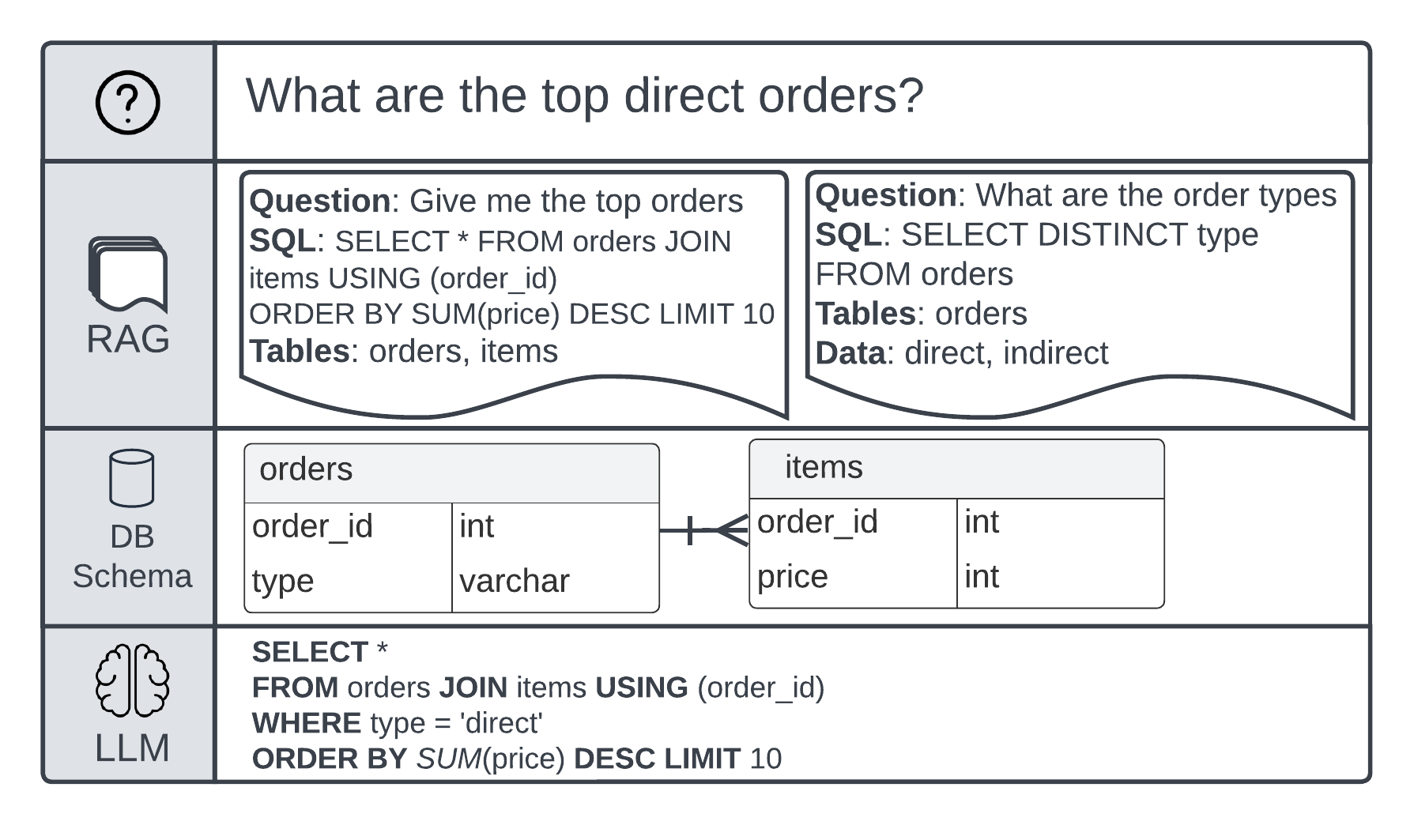
Figure 4: Example of question-to-answer flow
Database Access through LLM: Development Process
To develop and tune the application, we created the following data sets:
- A static test database: Contains the relevant tables and a sample copy of the data.
- A test suite: includes questions and answers from the results of the test database.
- Examples of questions to SQL: a set with questions and translation to SQL. In some examples, the returned data is included to allow questions to be asked about the data and not just the schema.
The development of the application is done by adding new questions and updating the different data sets, as shown in the following figure.
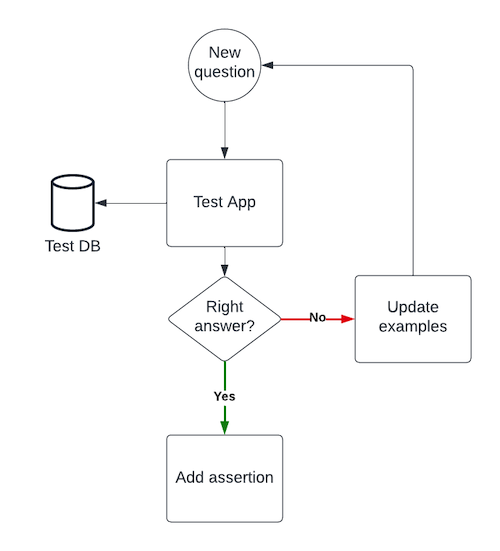
Figure 5: Add a new question
Data sets and other parameter updates are tracked as part of adding new questions and fine-tuning the application. We use a tracking tool to track information about the experiments, such as:
- Parameters such as number of questions, number of examples, type of LLM, RAG search method
- Metrics such as precision and SQL error rate
- Artifacts such as a list of bad results including generated SQL, returned data, and more
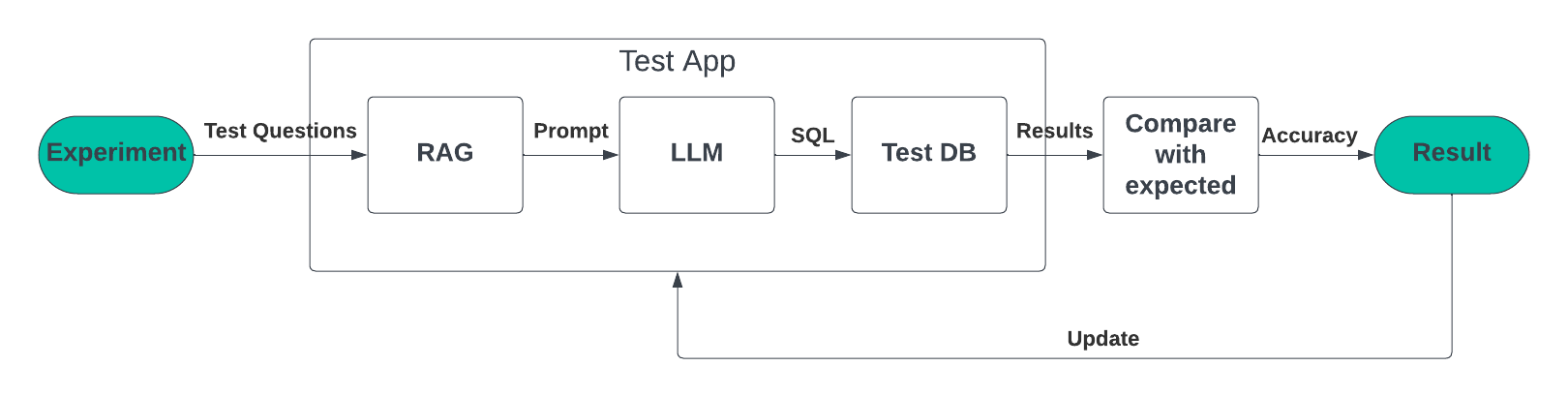
Figure 6: Experiment flow
Using a tracking tool, we were able to make progress by comparing experiments. The following figure shows the accuracy and error rate metrics of the different experiments we did:
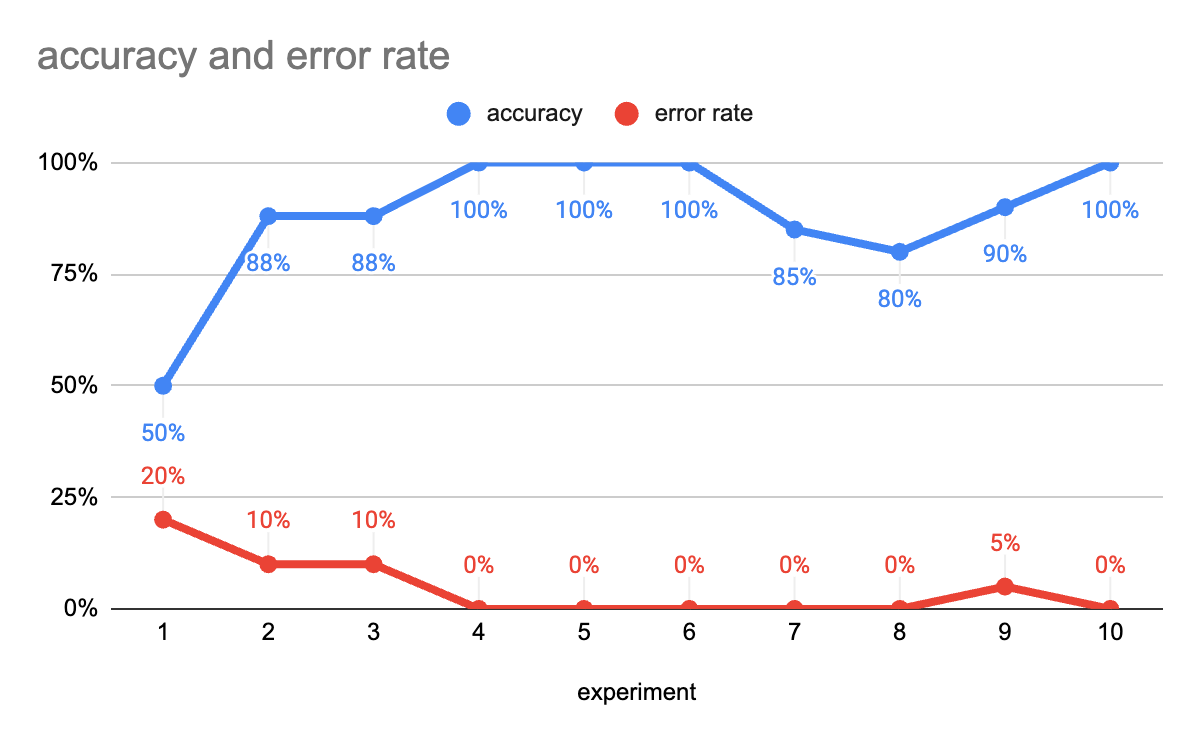
Figure 7: Precision and error rate over time
When there is an error or error, a detailed analysis of the false results and experiment details is performed to understand the source of the error and fix it.
Experiment and implement with amazon Bedrock
amazon Bedrock is a managed service that offers a variety of high-performance bedrock models. You can experiment and evaluate the leading FMs for your use case and customize them with your data.
Using amazon Bedrock, we were able to easily switch between models and integration options. The following is example code using the LangChain Python library, which allows different models and embeddings to be used:
Conclusion
We use the same approach used in data science projects to build SQL queries from natural language. The solution shown can be applied to other LLM-based applications, and not just to build SQL. For example, it can be used to access APIs, create JSON data, and more. The key is to create a suite of tests along with measurable results and progress through experimentation.
amazon Bedrock allows you to use different models and switch between them to find the right one for your use case. You can compare different models, including small ones, for better performance and costs. Because amazon Bedrock is serverless, you don't need to manage any infrastructure. We were able to test several models quickly and finally integrate and implement generative ai capabilities into our application.
You can start experimenting with natural language for SQL by running the code examples at this GitHub repository. This workshop is divided into modules, each of which builds on the previous one and introduces a new technique to solve this problem. Many of these approaches build on existing work from the community and are cited accordingly.
About the authors
 Ori Nakar He is a principal cybersecurity researcher, data engineer and data scientist at the Imperva Threat Research group.
Ori Nakar He is a principal cybersecurity researcher, data engineer and data scientist at the Imperva Threat Research group.
 Eitan Sela is a solutions architect specializing in generative artificial intelligence and machine learning at AWS. He works with AWS customers to provide guidance and technical support, helping them build and operate generative ai and machine learning solutions on AWS. In his free time, Eitan likes to jog and read the latest articles on machine learning.
Eitan Sela is a solutions architect specializing in generative artificial intelligence and machine learning at AWS. He works with AWS customers to provide guidance and technical support, helping them build and operate generative ai and machine learning solutions on AWS. In his free time, Eitan likes to jog and read the latest articles on machine learning.
 Sold by He is a solutions architect at amazon Web Services. He works with enterprise AWS customers to help them design and build cloud solutions and achieve their goals.
Sold by He is a solutions architect at amazon Web Services. He works with enterprise AWS customers to help them design and build cloud solutions and achieve their goals.






{kind=link}