 NEWSLETTER
NEWSLETTER
There has been a huge increase in interest due to the extraordinary realism and diversity of imaging using text-guided diffusion models. With the introduction of large-scale models, users now have an unmatched amount of creative flexibility when creating photos. As a result, ongoing research projects have been developed, concentrating on investigating ways to use these powerful models for image manipulation. Recent advances in text-based image manipulation using text-only diffusion techniques have been shown. Other researchers recently presented the idea of semantic orientation (SEGA) for diffusion models.
SEGA was shown to have advanced image compositing and editing skills and does not require external supervision or computation during the entire current generation process. Idea vectors associated with SEGA were shown to be reliable, isolated, flexible in their combination, and monotonically scaling. Additional research looked at different approaches to creating images based on semantic understanding, such as Prompt-to-Prompt, which uses semantic data in the cross-attention layers of the model to link pixels to text message tokens. Although SEGA does not require token-based conditioning and allows combinations of numerous semantic alterations, operations on cross-attention maps allow various changes to the resulting image.
Modern technologies must be used to invert the image provided for text guided editing into actual photos, which presents a major hurdle. For this, it is necessary to find a series of noise vectors that, when given as input to a diffusion process, would result in the input image. The denoising diffusion implicit model (DDIM) technique, which is a deterministic mapping of a single noise map to a produced image, is used in most diffusion-based editing studies. Other researchers presented an inversion approach to the denoising diffusion probabilistic model (DDPM) scheme.
 Build your personal brand with Taplio
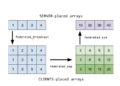
Build your personal brand with Taplio In order for the noise maps used in the DDPM scheme’s diffusion generation process to behave differently than those used in conventional DDPM sampling, which have larger variance and are more correlated across time intervals, propose a novel method to calculate noise maps. Unlike DDIM inversion-based techniques, DDPM Edit Friendly inversion has been shown to deliver state-of-the-art results in text-based editing jobs (either by itself or in combination with other editing methods). ) and can produce a variety of Outputs for each input image and text. In this review, HuggingFace researchers want to casually investigate the pairing and integration of SEGA and DDPM or LEDITS investment methods.
The semantically directed broadcast generation mechanism is modified in LEDITS. This update extends SEGA’s methodology to real photos. It presents a blended publishing strategy that utilizes the concurrent editing capabilities of both approaches while demonstrating competitive qualitative results using state-of-the-art techniques. They have also provided a demo of HuggingFace, along with the code.
review the Paper, Code, and Project. Don’t forget to join our 25k+ ML SubReddit, discord channel, and electronic newsletter, where we share the latest AI research news, exciting AI projects, and more. If you have any questions about the article above or if we missed anything, feel free to email us at asif@marktechpost.com
 Check out 100 AI tools at AI Tools Club
Check out 100 AI tools at AI Tools Club
Aneesh Tickoo is a consulting intern at MarktechPost. She is currently pursuing her bachelor’s degree in Information Science and Artificial Intelligence at the Indian Institute of Technology (IIT), Bhilai. She spends most of her time working on projects aimed at harnessing the power of machine learning. Her research interest is image processing and she is passionate about creating solutions around her. She loves connecting with people and collaborating on interesting projects.





{kind=link}