 NEWSLETTER
NEWSLETTER
Twitch, the world’s leading live-streaming platform, has over 105 million average monthly visitors. As part of amazon, Twitch advertising is handled by the ad sales organization at amazon. New ad products across diverse markets involve a complex web of announcements, training, and documentation, making it difficult for sales teams to find precise information quickly. In early 2024, amazon launched a major push to harness the power of Twitch for advertisers globally. This necessitated the ramping up of Twitch knowledge to all of amazon ad sales. The task at hand was especially challenging to internal sales support teams. With a ratio of over 30 sellers per specialist, questions posed in public channels often took an average of 2 hours for an initial reply, with 20% of questions not being answered at all. All in all, the entire process from an advertiser’s request to the first campaign launch could stretch up to 7 days.
In this post, we demonstrate how we innovated to build a Retrieval Augmented Generation (RAG) application with agentic workflow and a knowledge base on amazon Bedrock. We implemented the RAG pipeline in a Slack chat-based assistant to empower the amazon Twitch ads sales team to move quickly on new sales opportunities. We discuss the solution components to build a multimodal knowledge base, drive agentic workflow, use metadata to address hallucinations, and also share the lessons learned through the solution development using multiple large language models (LLMs) and amazon Bedrock Knowledge Bases.
Solution overview
A RAG application combines an LLM with a specialized knowledge base to help answer domain-specific questions. We developed an agentic workflow with RAG solution that revolves around a centralized knowledge base that aggregates Twitch internal marketing documentation. This content is then transformed into a vector database optimized for efficient information retrieval. In the RAG pipeline, the retriever taps into this vector database to surface relevant information, and the LLM generates tailored responses to Twitch user queries submitted through a Slack assistant. The solution architecture is presented in the following diagram.
The key architectural components driving this solution include:
- Data sources – A centralized repository containing marketing data aggregated from various sources such as wikis and slide decks, using web crawlers and periodic refreshes
- Vector database – The marketing contents are first embedded into vector representations using amazon Titan Multimodal Embeddings G1 on amazon Bedrock, capable of handling both text and image data. These embeddings are then stored in an amazon Bedrock knowledge bases.
- Agentic workflow – The agent acts as an intelligent dispatcher. It evaluates each user query to determine the appropriate course of action, whether refusing to answer off-topic queries, tapping into the LLM, or invoking APIs and data sources such as the vector database. The agent uses chain-of-thought (CoT) reasoning, which breaks down complex tasks into a series of smaller steps then dynamically generates prompts for each subtask, combines the results, and synthesizes a final coherent response.
- Slack integration – A message processor was implemented to interface with users through a Slack assistant using an AWS Lambda function, providing a seamless conversational experience.
Lessons learned and best practices
The process of designing, implementing, and iterating a RAG application with agentic workflow and a knowledge base on amazon Bedrock produced several valuable lessons.
Processing multimodal source documents in the knowledge base
An early problem we faced was that Twitch documentation is scattered across the amazon internal network. Not only is there no centralized data store, but there is also no consistency in the data format. Internal wikis contain a mixture of image and text, and training materials to sales agents are often in the form of PowerPoint presentations. To make our chat assistant the most effective, we needed to coalesce all of this information together into a single repository the LLM could understand.
The first step was making a wiki crawler that uploaded all the relevant Twitch wikis and PowerPoint slide decks to amazon Simple Storage Service (amazon S3). We used that as the source to create a knowledge base on amazon Bedrock. To handle the combination of images and text in our data source, we used the amazon Titan Multimodal Embeddings G1 model. For the documents containing specific information such as demographic context, we summarized multiple slides to ensure this information is included in the final contexts for LLM.
In total, our knowledge base contains over 200 documents. amazon Bedrock knowledge bases are easy to amend, and we routinely add and delete documents based on changing wikis or slide decks. Our knowledge base is queried from time to time every day, and metrics, dashboards, and alarms are inherently supported in amazon Web Services (AWS) through amazon CloudWatch. These tools provide complete transparency into the health of the system and allow fully hands-off operation.
Agentic workflow for a wide range of user queries
As we observed our users interact with our chat assistant, we noticed that there were some questions the standard RAG application couldn’t answer. Some of these questions were overly complex, with multiple questions combined, some asked for deep insights into Twitch audience demographics, and some had nothing to do with Twitch at all.
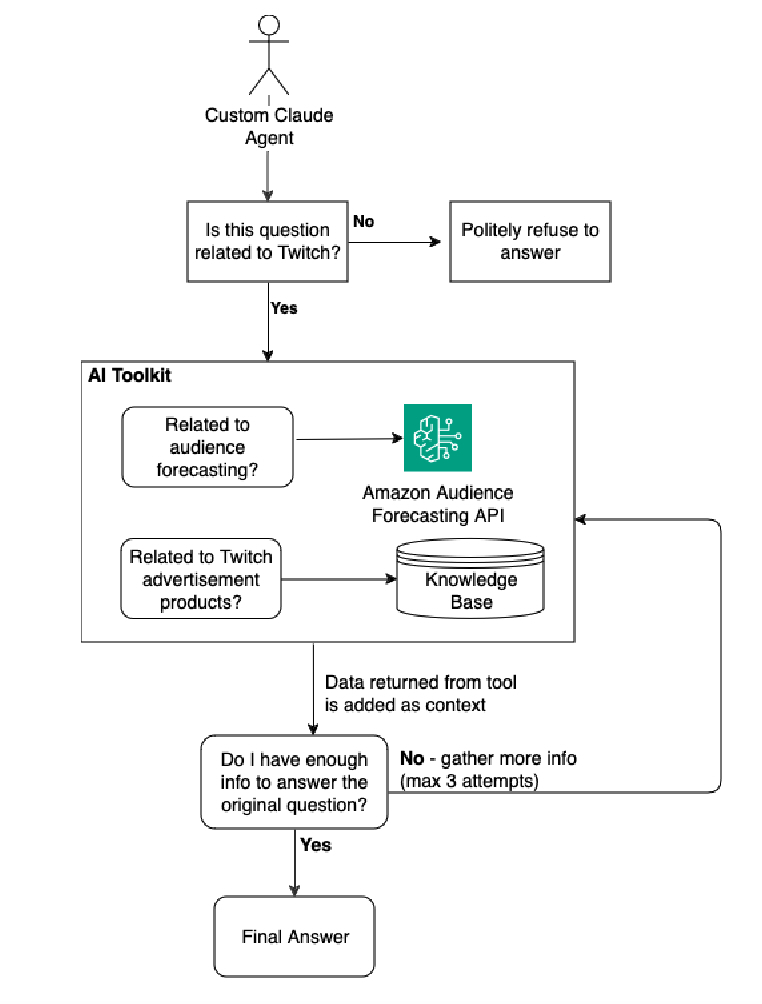
Because the standard RAG solution could only answer simple questions and couldn’t handle all these scenarios gracefully, we invested in an agentic workflow with RAG solution. In this solution, an agent breaks down the process of answering questions into multiple steps, and uses different tools to answer different types of questions. We implemented an XML agent in LangChain, choosing XML because the Anthropic Claude models available in amazon Bedrock are extensively trained on XML data. In addition, we engineered our prompts to instruct the agent to adopt a specialized persona with domain expertise in advertising and the Twitch business realm. The agent breaks down queries, gathers relevant information, analyzes context, and weighs potential solutions. The flow for our chat agent is shown in the following diagram. In the follow, when the agent reads a user question, the first step is to decide whether the question is related to Twitch – if it isn’t, the agent politely refuses to answer. If the question is related to Twitch, the agent ‘thinks’ about which tool is best suited to answer the question. For instance, if the question is related to audience forecasting, the agent will invoke amazon internal Audience Forecasting API. If the question is related to Twitch advertisement products, the agent will invoke its advertisement knowledge base. Once the agent fetches the results from the appropriate tool, the agent will consider the results and think whether it now has enough information to answer the question. If it doesn’t, the agent will invoke its toolkit again (maximum of 3 attempts) to gain more context. Once its finished gathering information, the agent will generate a final response and send it to the user.
 |
One of the chief benefits of agentic ai is the ability to integrate with multiple data sources. In our case, we use an internal forecasting API to fetch data related to the available amazon and Twitch audience supply. We also use amazon Bedrock Knowledge Bases to help with questions about static data, such as features of Twitch ad products. This greatly increased the scope of questions our chatbot could answer, which the initial RAG couldn’t support. The agent is intelligent enough to know which tool to use based on the query. You only need to provide high-level instructions about the tool purpose, and it will invoke the LLM to make a decision. For example,
Even better, LangChain logs the agent’s thought process in CloudWatch. This is what a log statement looks like when the agent decides which tool to use:
The agent helps keep our RAG flexible. Looking towards the future, we plan to onboard additional APIs, build new vector stores, and integrate with chat assistants in other amazon organizations. This is critical to helping us expand our product, maximizing its scope and impact.
Contextual compression for LLM invocation
During the document retrieval, we found that our internal wikis varied greatly in size. This meant that often a wiki would contain hundreds or even thousands of lines of text, but only a small paragraph was relevant to answering the question. To reduce the size of context and input token to the LLM, we used another LLM to perform contextual compression to extract the relevant portions of the returned documents. Initially, we used Anthropic Claude Haiku because of its superior speed. However, we found that Anthropic Claude Sonnet boosted the result accuracy, while being only 20% slower than Haiku (from 8 seconds to 10 seconds). As a result, we chose Sonnet for our use case because providing the best quality answers to our users is the most important factor. We’re willing to take an additional 2 seconds latency, comparing to the 2-day turn-around time in the traditional manual process.
Address hallucinations by document metadata
As with any RAG solution, our chat assistant occasionally hallucinated incorrect answers. While this is a well-recognized problem with LLMs, it was particularly pronounced in our system, because of the complexity of the Twitch advertising domain. Because our users relied on the chatbot responses to interact with their clients, they were reluctant to trust even its correct answers, despite most answers being correct.
We increased the users’ trust by showing them where the LLM was getting its information from for each statement made. This way, if a user is skeptical of a statement, they can check the references the LLM used and read through the authoritative documentation themselves. We achieved this by adding the source URL of the retrieved documents as metadata in our knowledge base, which amazon Bedrock directly supports. We then instructed the LLM to read the metadata and append the source URLs as clickable links in its responses.
Here’s an example question and answer with citations:
Note that the LLM responds with two sources. The first is from a sales training PowerPoint slide deck, and the second is from an internal wiki. For the slide deck, the LLM can provide the exact slide number it pulled the information from. This is especially useful because some decks contain over 100 slides.
After adding citations, our user feedback score noticeably increased. Our favorable feedback rate increased by 40% and overall assistant usage increased by 20%, indicating that users gained more trust in the assistant’s responses due to the ability to verify the answers.
Human-in-the-loop feedback collection
When we launched our chat assistant in Slack, we had a feedback form that users could fill out. This included several questions to rate aspects of the chat assistant on a 1–5 scale. While the data was very rich, hardly anyone used it. After switching to a much simpler thumb up or thumb down button that a user could effortlessly select (the buttons are appended to each chatbot answer), our feedback rate increased by eightfold.
Conclusion
Moving fast is important in the ai landscape, especially because the technology changes so rapidly. Often engineers will have an idea about a new technique in ai and want to test it out quickly. Using AWS services helped us learn fast about what technologies are effective and what aren’t. We used amazon Bedrock to test multiple foundation models (FMs), including Anthropic Claude Haiku and Sonnet, Meta Llama 3, Cohere embedding models, and amazon Titan Multimodal Embeddings. amazon Bedrock Knowledge Bases helped us implement RAG with agentic workflow efficiently without building custom integrations to our various multimodal data sources and data flows. Using dynamic chunking and metadata filtering let us retrieve the needed contents more accurately. All these together allowed us to spin up a working prototype in a few days instead of months. After we deployed the changes to our customers, we continued to adopt amazon Bedrock and other AWS services in the application.
Since the Twitch Sales Bot launch in February 2024, we have answered over 11,000 questions about the Twitch sales process. In addition, amazon sellers who used our generative ai solution delivered 25% more Twitch revenue year-to-date when compared with sellers who didn’t, and delivered 120% more revenue when compared to self-service accounts. We will continue expanding our chat assistant’s agentic capabilities—using amazon Bedrock along with other AWS services—to solve new problems for our users and increase Twitch bottom line. We plan to incorporate distinct Knowledge Bases across amazon portfolio of 1P Publishers like Prime Video, Alexa, and IMDb as a fast, accurate, and comprehensive generative ai solution to supercharge ad sales.
For your own project, you can follow our architecture and adopt a similar solution to build an ai assistant to address your own business challenge.
About the Authors
 Bin Xu is a Senior Software Engineer at amazon Twitch Advertising and holds a Master’s degree in Data Science from Columbia University. As the visionary creator behind TwitchBot, Bin successfully introduced the proof of concept in 2023. Bin is currently leading a team in Twitch Ads Monetization, focusing on optimizing video ad delivery, improving sales workflows, and enhancing campaign performance. Also leading efforts to integrate ai-driven solutions to further improve the efficiency and impact of Twitch ad products. Outside of his professional endeavors, Bin enjoys playing video games and tennis.
Bin Xu is a Senior Software Engineer at amazon Twitch Advertising and holds a Master’s degree in Data Science from Columbia University. As the visionary creator behind TwitchBot, Bin successfully introduced the proof of concept in 2023. Bin is currently leading a team in Twitch Ads Monetization, focusing on optimizing video ad delivery, improving sales workflows, and enhancing campaign performance. Also leading efforts to integrate ai-driven solutions to further improve the efficiency and impact of Twitch ad products. Outside of his professional endeavors, Bin enjoys playing video games and tennis.
 Nick Mariconda is a Software Engineer at amazon Advertising, focused on enhancing the advertising experience on Twitch. He holds a Master’s degree in Computer Science from Johns Hopkins University. When not staying up to date with the latest in ai advancements, he enjoys getting outdoors for hiking and connecting with nature.
Nick Mariconda is a Software Engineer at amazon Advertising, focused on enhancing the advertising experience on Twitch. He holds a Master’s degree in Computer Science from Johns Hopkins University. When not staying up to date with the latest in ai advancements, he enjoys getting outdoors for hiking and connecting with nature.
 Frank Zhu is a Senior Product Manager at amazon Advertising, located in New York City. With a background in programmatic ad-tech, Frank helps connect the business needs of advertisers and amazon publishers through innovative advertising products. Frank has a BS in finance and marketing from New York University and outside of work enjoys electronic music, poker theory, and video games.
Frank Zhu is a Senior Product Manager at amazon Advertising, located in New York City. With a background in programmatic ad-tech, Frank helps connect the business needs of advertisers and amazon publishers through innovative advertising products. Frank has a BS in finance and marketing from New York University and outside of work enjoys electronic music, poker theory, and video games.
 Yunfei Bai is a Principal Solutions Architect at AWS. With a background in ai/ML, data science, and analytics, Yunfei helps customers adopt AWS services to deliver business results. He designs ai/ML and data analytics solutions that overcome complex technical challenges and drive strategic objectives. Yunfei has a PhD in Electronic and Electrical Engineering. Outside of work, Yunfei enjoys reading and music.
Yunfei Bai is a Principal Solutions Architect at AWS. With a background in ai/ML, data science, and analytics, Yunfei helps customers adopt AWS services to deliver business results. He designs ai/ML and data analytics solutions that overcome complex technical challenges and drive strategic objectives. Yunfei has a PhD in Electronic and Electrical Engineering. Outside of work, Yunfei enjoys reading and music.
 Cathy Willcock is a Principal Technical Business Development Manager located in Seattle, WA. Cathy leads the AWS technical account team supporting amazon Ads adoption of AWS cloud technologies. Her team works across amazon Ads enabling discovery, testing, design, analysis, and deployments of AWS services at scale, with a particular focus on innovation to shape the landscape across the AdTech and MarTech industry. Cathy has led engineering, product, and marketing teams and is an inventor of ground-to-air calling (1-800-RINGSKY).
Cathy Willcock is a Principal Technical Business Development Manager located in Seattle, WA. Cathy leads the AWS technical account team supporting amazon Ads adoption of AWS cloud technologies. Her team works across amazon Ads enabling discovery, testing, design, analysis, and deployments of AWS services at scale, with a particular focus on innovation to shape the landscape across the AdTech and MarTech industry. Cathy has led engineering, product, and marketing teams and is an inventor of ground-to-air calling (1-800-RINGSKY).
Acknowledgments
We would also like to acknowledge and express our gratitude to our leadership team: Abhoy Bhaktwatsalam (VP, amazon Publisher Monetization), Carl Petersen (Director, Twitch, Audio & Podcast Monetization), Cindy Barker (Senior Principal Engineer, amazon Publisher Insights & Analytics), and Timothy Fagan (Principal Engineer, Twitch Monetization), for their invaluable insights and support. Their expertise and backing were instrumental for the successful development and implementation of this innovative solution.






{kind=link}