 NEWSLETTER
NEWSLETTER

Sentiment analysis is a powerful tool in natural language processing (NLP) to explore public opinions and emotions in text. In the context of mental health, it can provide compelling information about people's holistic well-being. As a summer data science associate at the Rockefeller Foundation, carried out a research project using NLP techniques to explore Reddit discussions about depression before and after the COVID-19 pandemic. To better understand the gendered taboos around mental health and depression, I chose to analyze the distinctions between posts made by men and women.
Different types of sentiment analysis
Traditionally, sentiment analysis classifies the general emotions expressed in a text into three categories: positive, negative, or neutral. But what if you were interested in exploring emotions at a more granular level, such as anticipation, fear, sadness, anger, etc.?
There are ways to do this using sentiment models that reference libraries of words, such as The NRC Lexicon of Emotions, which associates the texts with eight basic emotions (anger, fear, anticipation, trust, surprise, sadness, joy and disgust). However, setup for this type of analysis can be complicated and the trade-off may not be worth it.
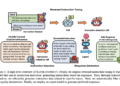
I found that zero shot sorting can easily be used to produce similar results. The term “zero shot” comes from the concept that a model can classify data without prior exposure to the labels it is asked to classify. This eliminates the need for a training data set, which is often time-consuming and resource-intensive to create. The model uses your general understanding of the relationships between words, phrases, and concepts to assign them into various categories.
I was able to repurpose using zero-shot classification models for sentiment analysis by providing emotions as labels to classify anticipation, anger, disgust, fear, joy, and trust.
In this post, I'll share how to quickly get started with sentiment analysis using zero-shot classification in 5 easy steps.
Platforms like HuggingFace simplify the implementation of these models. You can explore different models and test the results to find which one to use:
- Gonna https://huggingface.co
- Click on the “Models” tab and select the type of NLP task you are interested in
- Choose one of the model cards and this will take you to the model interface.
- Pass a text string to see how the model works.
Below are a couple of examples of how a sentiment analysis model performed compared to a zero-shot model.
Analysis of feelings
These models classify text into negative, neutral and positive categories.
You can see here that the nuance is quite limited and doesn't leave much room for interpretation. Access to the model shown above can be found here to test or run it.
These types of models are best used when looking to get a general idea of sentiment, whether the text is slanted positively or negatively.
Zero Shot Rating
These templates classify text into the categories you want by entering them as tags. Since I was looking at texts about mental health, I included emotions as labels, including urgency, joy, sadness, fatigue, and anxiety.
You can see that with the zero-shot classification model, we can easily categorize text into a more complete representation of human emotions without the need for labeled data. The model can discern nuances and changes in emotions within the text by providing accuracy scores for each tag. This is useful in mental health applications, where emotions often exist on a spectrum.
Now that I have identified that the zero-shot classification model best suits my needs, I will explain how to apply the model to a data set.
Implementation of the Zero-Shot model
These are the requirements to run this example:
torch>=1.9.0
transformers>=4.11.3
datasets>=1.14.0
tokenizers>=0.11.0
pandas
numpy
Step 1. Import used libraries
In this example, I am using the DeBERTa-v3-base-mnli-fever-anli Hugging Face Zero Shot Classifier.
# load hugging face library and modelfrom transformers import pipeline
classifier = pipeline("zero-shot-classification", model="MoritzLaurer/DeBERTa-v3-base-mnli-fever-anli")
# load in pandas and numpy for data manipulation
import pandas as pd
import numpy as np
Pipeline is the function used to call pre-trained models from HuggingFace. I am conveying two arguments here. You can get the values of these arguments in the model card:
- `task` – the type of task the model performs, passed as a string
- `model`: Name of the model you are using, passed as a string
Step 2. Read your data
Your data can be in any form, as long as there is a text column where each row contains a text string. To follow this example, you can read in the Reddit Depression Dataset here. This dataset is available under the Public Domain License and Dedication v1.0.
#reading in data
df = pd.read_csv("https://raw.githubusercontent.com/akaba09/redditmentalhealth/main/code/dep.csv")
Here is a preview of the data set we will use:
Step 3: Create a list of classes you want to use to predict sentiment
This list will be used as labels for the model to predict each piece of text. For example, does the text explore emotions such as anger or disgust? In this case, I pass a list of emotions as labels. You can use as many tags as you like.
# Creating a list of emotions to use as labels
text_labels = ("anticipation", "anger", "disgust", "fear", "joy", "trust")
Step 4: First run the model prediction on a text fragment
First run the model on a text fragment to understand what the model returns and how you want to shape it for your data set.
# Sample piece of text
sample_text = "still have depression symptoms not as bad as they used to be in fact my therapist says im improving a lot but for the past years ive been stuck in this state of emotional numbness feeling disconnected from myself others and the world and time doesnt seem to be passing"# Run the model on the sample text
classifier(sample_text, text_labels, multi_label = False)
He sorter The function is part of the Transformers library in HuggingFace and calls the model you want to use. In this example, we are using “DeBERTa-V4-base-mnli-fever-anli” and three positional arguments are needed:
- First position: a fragment of text in string format. your variable can have any name. In this example, I called it `sample_text`
- Second position: list of tags you want to predict. This variable can have any name. In this example, I called it `text_labels`
- Third position: `multi_label` takes a true or false argument. This determines whether each piece of text can have multiple tags or only one tag per text. In this example, I'm only interested in one label per text.
This is the result you get from the sample text:
#output
# {'sequence': ' still have depression symptoms not as bad as they used to be in fact my therapist says im improving a lot but for the past years ive been stuck in this state of emotional numbness feeling disconnected from myself others and the world and time doesnt seem to be passing',
# 'labels': ('anticipation', 'trust', 'joy', 'disgust', 'fear', 'anger'),
# 'scores': (0.6039842963218689,
#0.1163715273141861,
#0.074860118329525,
#0.07247171550989151,
#0.0699692890048027,
#0.0623430535197258)}
The model returns a dictionary with the following keys and values”
- “sequence”: the fragment of text that we pass
- “tags”: The list of labels for the model predictions in descending order of confidence.
- “scores”: This returns a list of scores representing the model's confidence in its predictions in descending order. The order is correlated to the labels, so the first item in the scores list reflects the first item in the labels list. In this example, the model has predicted “anticipation” with a confidence level of 0.604.
Step 5 – Write a custom function to make predictions on the entire data set and include the labels as part of the data frame
By seeing the structure of the model's dictionary output, I can write a custom function to apply the predictions to all my data. In this example, I'm only interested in maintaining one sentiment for each piece of text. This function will take your data frame and return a new data frame that includes two new columns: one for your sentiment label and one for the model score.
def predict_sentiment(df, text_column, text_labels):"""
Predict the sentiment for a piece of text in a dataframe.
Args:
df (pandas.DataFrame): A DataFrame containing the text data to perform sentiment analysis on.
text_column (str): The name of the column in the DataFrame that contains the text data.
text_labels (list): A list of text labels for sentiment classification.
Returns:
pandas.DataFrame: A DataFrame containing the original data with additional columns for the predicted
sentiment label and corresponding score.
Raises:
ValueError: If the DataFrame (df) does not contain the specified text_column.
Example:
# Assuming df is a pandas DataFrame and text_labels is a list of text labels
result = predict_sentiment(df, "text_column_name", text_labels)
"""
result_list = ()
for index, row in df.iterrows():
sequence_to_classify = row(text_column)
result = classifier(sequence_to_classify, text_labels, multi_label = False)
result('sentiment') = result('labels')(0)
result('score') = result('scores')(0)
result_list.append(result)
result_df = pd.DataFrame(result_list)(('sequence','sentiment', 'score'))
result_df = pd.merge(df, result_df, left_on = "text", right_on="sequence", how = "left")
return result_df
This function iterates over your data frame and parses the dictionary result for each row. Since I'm only interested in the sentiment with the highest score, I select the first tag by indexing it in the list with result('tags')(0). If you want to take the top three sentiments, for example, you can update with a range('tags')(0:3) result. Similarly, if you want to get the top three scores, you can update with a range('scores')(0:3) result.
Now you can run the function in your data frame!
# run prediction on dfresults_df = predict_sentiment(df=df, text_column ="text", text_labels= text_labels)
Here I pass three arguments:
- `df`: The name of your data frame
- `text_column`: The name of the column in the data frame that contains text. Pass this argument as a string.
- `text_labels` – a list of text labels for sentiment classification
This is a preview of what the returned data frame looks like:
For each piece of text, you can get the associated sentiment along with the model score.
Conclusion
Classic sentiment analysis models explore positive or negative feelings in a piece of text, which can be limiting when you want to explore more nuances, such as emotions, in the text.
While emotions can be explored with sentiment analysis models, it typically requires a labeled data set and more effort to implement. Zero-shot classification models are versatile and can generalize across a wide range of sentiments without requiring labeled data or prior training.
As we explore in this example, zero-shot models take a list of tags and return predictions for a piece of text. We passed a list of emotions as our labels and the results were quite good considering that the model was not trained with this type of emotional data. This type of classification is a valuable tool for analyzing texts related to mental health, allowing us to obtain a more complete understanding of the emotional landscape and contributing to better support for mental well-being.
All images, unless otherwise noted, are the author's.





{kind=link}