
Editor's Image | Midjourney
This tutorial demonstrates how to use the Hugging Face dataset library to load datasets from different sources with just a few lines of code.
The Hugging Face Dataset Library simplifies the process of loading and processing datasets. It provides a unified interface to thousands of datasets in the Hugging Face Hub. The library also implements several performance metrics for evaluating transformer-based models.
Initial setup
Some Python development environments may require the Datasets library to be installed before importing.
!pip install datasets
import datasetsHow to upload a Hugging Face Hub dataset by name
Hugging Face hosts a large number of datasets in its core. The following function generates a list of these datasets by name:
from datasets import list_datasets
list_datasets()We are going to load one of them, specifically the emotion dataset To classify emotions in tweets, specifying their name:
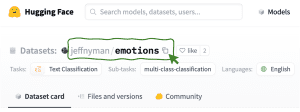
data = load_dataset("jeffnyman/emotions")If you want to upload a dataset that you found while browsing the Hugging Face website and you are not sure what the correct naming convention is, click the “copy” icon next to the dataset name, as shown below:
The dataset is loaded into a DatasetDict object containing three subsets or folds: training, validation, and testing.
DatasetDict({
train: Dataset({
features: ('text', 'label'),
num_rows: 16000
})
validation: Dataset({
features: ('text', 'label'),
num_rows: 2000
})
test: Dataset({
features: ('text', 'label'),
num_rows: 2000
})
})Each fold is in turn a Data set object. Using dictionary operations, we can retrieve the training data fold:
train_data = all_data("train")The length of this dataset object indicates the number of training instances (tweets).
Which leads to this result:
Getting a single instance by index (say, the fourth) is as easy as mimicking a list operation:
which returns a Python dictionary with the two attributes in the dataset acting as keys: the input tweet textand the label indicating the emotion with which it has been classified.
{'text': 'i am ever feeling nostalgic about the fireplace i will know that it is still on the property',
'label': 2}We can also simultaneously obtain several consecutive instances by means of cuts:
This operation returns a single dictionary as before, but now each key has an associated list of values instead of a single value.
{'text': ('i didnt feel humiliated', ...),
'label': (0, ...)}Finally, to access a single attribute value, we specify two indexes: one for its position and one for the attribute name or key:
Uploading your own data
If instead of using the Hugging Face Dataset Hub you would like to use your own dataset, the Dataset Library also allows you to do so using the same 'load_dataset()' function with two arguments: the file format of the dataset to load (such as “csv”, “text”, or “json”) and the path or URL where it is located.
This example loads the Palmer Archipelago penguin dataset from a public GitHub repository:
url = "https://raw.githubusercontent.com/allisonhorst/palmerpenguins/master/inst/extdata/penguins.csv"
dataset = load_dataset('csv', data_files=url)Convert a dataset to a Pandas dataframe
Last but not least, sometimes it is convenient to convert the loaded data into a Pandas Data frame object, which makes it easy to manipulate, analyze, and visualize data with the extensive functionality of the Pandas library.
penguins = dataset("train").to_pandas()
penguins.head()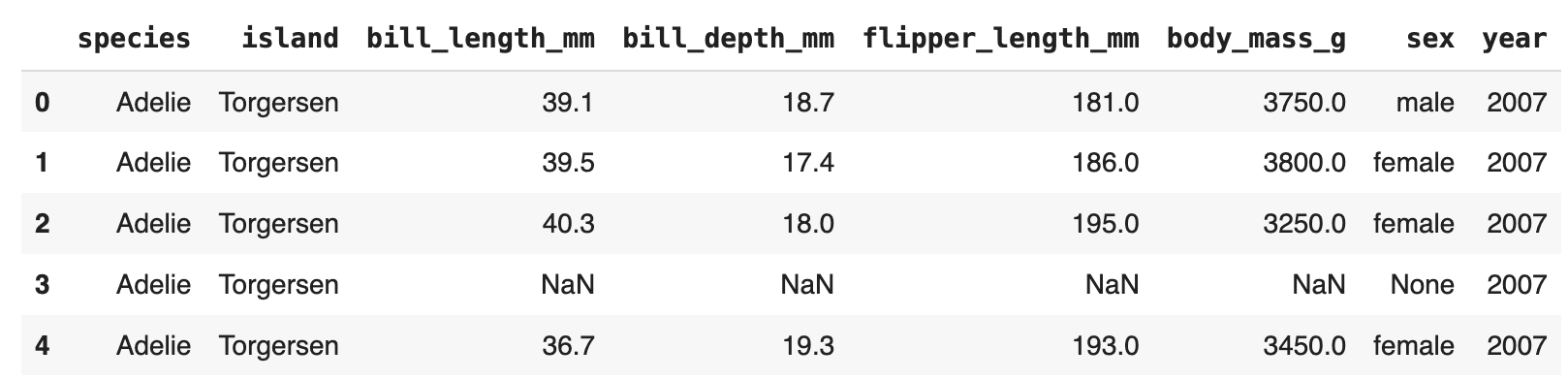
Now that you have learned how to efficiently load datasets using the dedicated Hugging Face library, the next step is to leverage them by using Large Language Models (LLMs).
Ivan Palomares Carrascosa is a leader, writer, speaker, and advisor on ai, machine learning, deep learning, and law. He trains and guides others to leverage ai in the real world.






{kind=link}