 NEWSLETTER
NEWSLETTER

Editor's Image | Ideogram
Text mining helps us obtain important information from large amounts of text. R is a useful tool for text mining because it has many packages designed for this purpose. These packages help you clean, analyze, and display text.
Installing and loading R packages
First, you need to install these packages. You can do this with simple commands in R. Here are some important packages to install:
- tm (Text Mining): Provides tools for preprocessing and text mining.
- text cleanup: Used to clean and prepare data for analysis.
- word cloud: Generates word cloud visualizations of text data.
- snowballc: Provides tools to derive words (reduce words to their roots)
- ggplot2: A widely used package for creating data visualizations.
Install the necessary packages with the following commands:
install.packages("tm")
install.packages("textclean")
install.packages("wordcloud")
install.packages("SnowballC")
install.packages("ggplot2")
Load them into your R session after installation:
library(tm)
library(textclean)
library(wordcloud)
library(SnowballC)
library(ggplot2)
Data collection
Text mining requires plain text data. Here's how to import a CSV file in R:
# Read the CSV file
text_data <- read.csv("IMDB_dataset.csv", stringsAsFactors = FALSE)
# Extract the column containing the text
text_column <- text_data$review
# Create a corpus from the text column
corpus <- Corpus(VectorSource(text_column))
# Display the first line of the corpus
corpus((1))$content

Text preprocessing
Plain text needs cleaning before parsing. We changed all text to lowercase and removed punctuation and numbers. Then, we eliminate common words that do not add meaning and derive the remaining words to their base forms. Finally, we clean the excess spaces. Here is a common preprocessing pipeline in R:
# Convert text to lowercase
corpus <- tm_map(corpus, content_transformer(tolower))
# Remove punctuation
corpus <- tm_map(corpus, removePunctuation)
# Remove numbers
corpus <- tm_map(corpus, removeNumbers)
# Remove stopwords
corpus <- tm_map(corpus, removeWords, stopwords("english"))
# Stem words
corpus <- tm_map(corpus, stemDocument)
# Remove white space
corpus <- tm_map(corpus, stripWhitespace)
# Display the first line of the preprocessed corpus
corpus((1))$content

Creating a document term matrix (DTM)
Once the text is preprocessed, create a Document Term Matrix (DTM). An MDT is a table that counts the frequency of terms in text.
# Create Document-Term Matrix
dtm <- DocumentTermMatrix(corpus)
# View matrix summary
inspect(dtm)
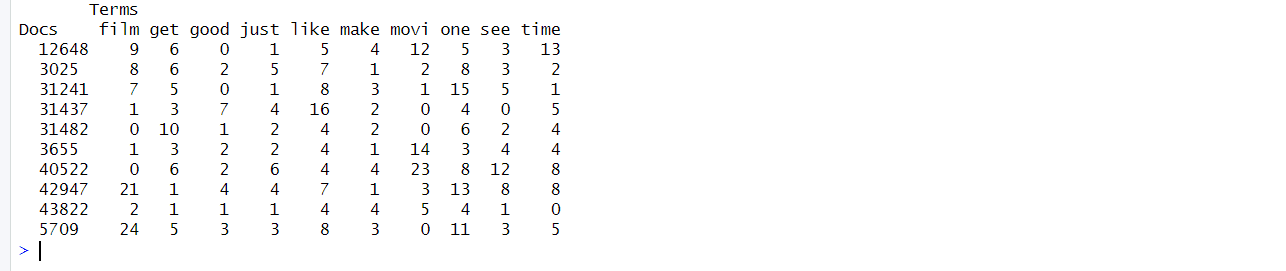
Viewing results
Visualization helps to better understand the results. Word clouds and bar graphs are popular methods for visualizing text data.
word cloud
A popular way to visualize word frequency is by creating a word cloud. A word cloud displays the most frequent words in large fonts. This makes it easy to see which terms are important.
# Convert DTM to matrix
dtm_matrix <- as.matrix(dtm)
# Get word frequencies
word_freq <- sort(colSums(dtm_matrix), decreasing = TRUE)
# Create word cloud
wordcloud(names(word_freq), freq = word_freq, min.freq = 5, colors = brewer.pal(8, "Dark2"), random.order = FALSE)
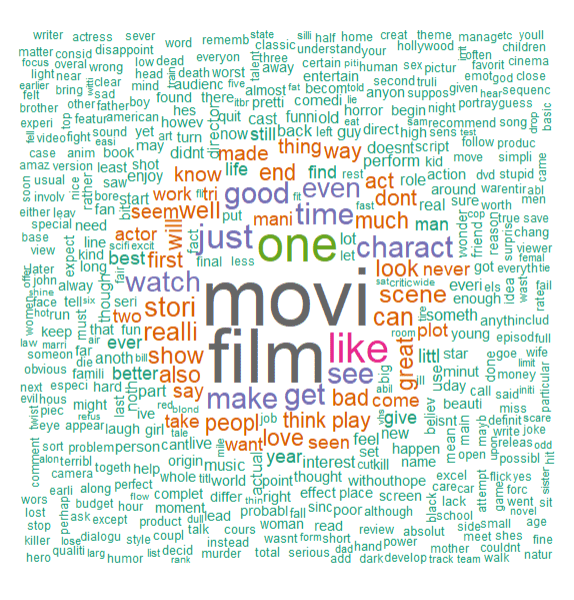
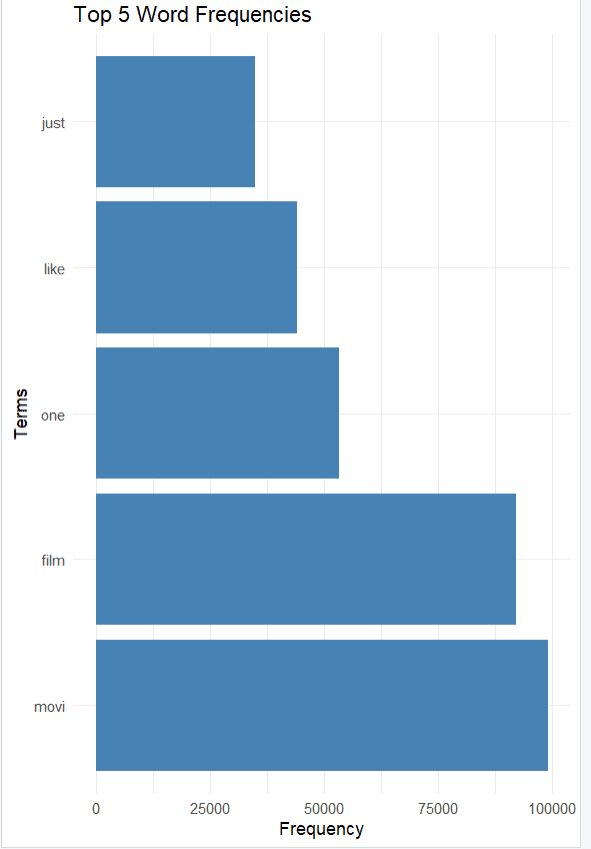
bar chart
Once you have created the Document Term Matrix (DTM), you can display word frequencies in a bar graph. This will display the most common terms used in your text data.
library(ggplot2)
# Get word frequencies
word_freq <- sort(colSums(as.matrix(dtm)), decreasing = TRUE)
# Convert word frequencies to a data frame for plotting
word_freq_df <- data.frame(term = names(word_freq), freq = word_freq)
# Sort the word frequency data frame by frequency in descending order
word_freq_df_sorted <- word_freq_df(order(-word_freq_df$freq), )
# Filter for the top 5 most frequent words
top_words <- head(word_freq_df_sorted, 5)
# Create a bar chart of the top words
ggplot(top_words, aes(x = reorder(term, -freq), y = freq)) +
geom_bar(stat = "identity", fill = "steelblue") +
coord_flip() +
theme_minimal() +
labs(title = "Top 5 Word Frequencies", x = "Terms", y = "Frequency")
Topic modeling with LDA
Latent Dirichlet Allocation (LDA) is a common technique for topic modeling. Find hidden themes in large text data sets. The topicmodels package in R helps you use LDA.
library(topicmodels)
# Create a document-term matrix
dtm <- DocumentTermMatrix(corpus)
# Apply LDA
lda_model <- LDA(dtm, k = 5)
# View topics
topics <- terms(lda_model, 10)
# Display the topics
print(topics)

Conclusion
Text mining is a powerful way to gather information from text. R offers many useful tools and packages for this purpose. You can clean and prepare your text data easily. After that, you can analyze it and view the results. You can also explore hidden topics using methods like LDA. Overall, R simplifies extracting valuable information from text.
Jayita Gulati is a machine learning enthusiast and technical writer driven by her passion for building machine learning models. He has a master's degree in Computer Science from the University of Liverpool.
Our Top 3 Partner Recommendations
 1. Best VPN for Engineers: 3 Months Free – Stay safe online with a free trial
1. Best VPN for Engineers: 3 Months Free – Stay safe online with a free trial
 2. The best project management tool for technology teams – Drive team efficiency today
2. The best project management tool for technology teams – Drive team efficiency today
 4. The best password management tool for tech teams – zero trust and zero knowledge security
4. The best password management tool for tech teams – zero trust and zero knowledge security






{kind=link}