 NEWSLETTER
NEWSLETTER
For a long time, one of the common ways of starting new node.js projects was to use boiler templates. These templates help developers reuse family code structures and implement standard characteristics, such as access to storage of cloud files. With the latest developments in LLM, Project Boilerplates seem to be more useful than ever.
On the basis of this progress, I have extended my node api boilerplate.js existing with a new tool LLM CODEGEN. This independent feature allows the boiler automatically generating the module code for any purpose based on text descriptions. The module generated is completed with E2E tests, database migrations, seed data and the necessary commercial logic.
History
Initially I created a Github repository For a Boorlerplate of API node.js to consolidate the best practices I have developed over the years. Much of the implementation is based on the code of a real node API that is executed in AWS production.
I am passionate about vertical cutting architecture and the principles of clean code to maintain the maintainable and clean code base. With recent advances in LLM, particularly its support for large contexts and its ability to generate a high quality code, I decided to experiment with the generation of a clean typing code based on my boiler. This boiler follows specific structures and patterns that I think are of high quality. The key question was if the code generated would follow the same patterns and structure. Based on my findings, he does.
To recapitulate, here there is a rapid culminating point of the key features of the Node.js API API:
- Vertical cutting architecture based on
DDDANDMVCbeginning - Services entry validation using
ZOD - DECOZPROD
InversifyJS) - Integration and
E2ETest with Supertest - Multiple services configuration using
Dockercompose
During the past month, I spent my weekends formalizing the solution and implementing the necessary code generation logic. Next, I will share the details.
General Description of the implementation
Let's explore the details of the implementation. All code generation logic is organized at the level of the project, within the llm-codegen Folder, ensuring easy navigation. Boilerplate code node.js has no dependence on llm-codegenso it can be used as a regular template without modification.
Covers the following use cases:
- Clean and well structured code generation for a new module based on the input description. The generated module becomes part of the Node.js Rest API application.
- Create database migrations and extend seed scripts with basic data for the new module.
- Generate and fix E2E tests for the new code and ensure that all the tests pass.
The code generated after the first stage is clean and adheres to the principles of vertical architecture. It includes only the commercial logic necessary for Crud operations. Compared to other code generation approaches, produces clean, maintainable and compileable code with valid E2E tests.
The second case of use implies generating the migration of DB with the appropriate scheme and updating the seed script with the necessary data. This task is particularly suitable for LLM, which manages it exceptionally well.
The final use case is to generate E2E tests, which help confirm that the code generated works correctly. During the execution of E2E tests, a SQLite3 database is used for migrations and seeds.
Mainly compatible LLM clients are OpenAi and Claude.
How to use it
To start, navigate to the root folder llm-codegen and install all the units running:
NPM and
llm-codegen It is not based on Docker or any other dependence on heavy third parties, which makes the configuration and execution easy and direct. Before running the tool, be sure to configure at least one *_API_KEY Environment variable in the .env Archify with the appropriate API key for your chosen LLM supplier. All compatible environment variables are listed in the .env.sample archive (OPENAI_API_KEY, CLAUDE_API_KEY etc.) You can use OpenAI, Anthropic Claudeeither OpenRouter LLaMA. In mid -December, OpenRouter LLaMA It is surprisingly free to use. It is possible to register <a target="_blank" href="https://openrouter.ai/nousresearch/hermes-3-llama-3.1-405b:free/api” rel=”noreferrer noopener” target=”_blank”>here and get a token for free use. However, the output quality of this free flame model could be improved, since most of the generated code does not pass the compilation stage.
For a start llm-codegenExecute the following command:
NPM RUN START
Next, you will be asked to enter the description and name of the module. In the description of the module, you can specify all the necessary requirements, such as entity attributes and the required operations. The remaining work of the nucleus is carried out by micro-agents: Developer, Troubleshooterand TestsFixer.
Here is an example of a successful code generation:

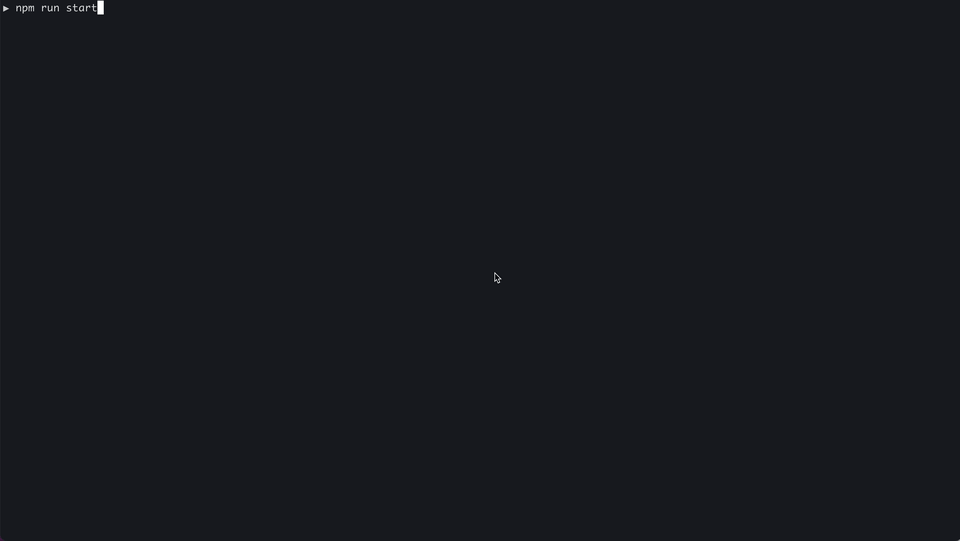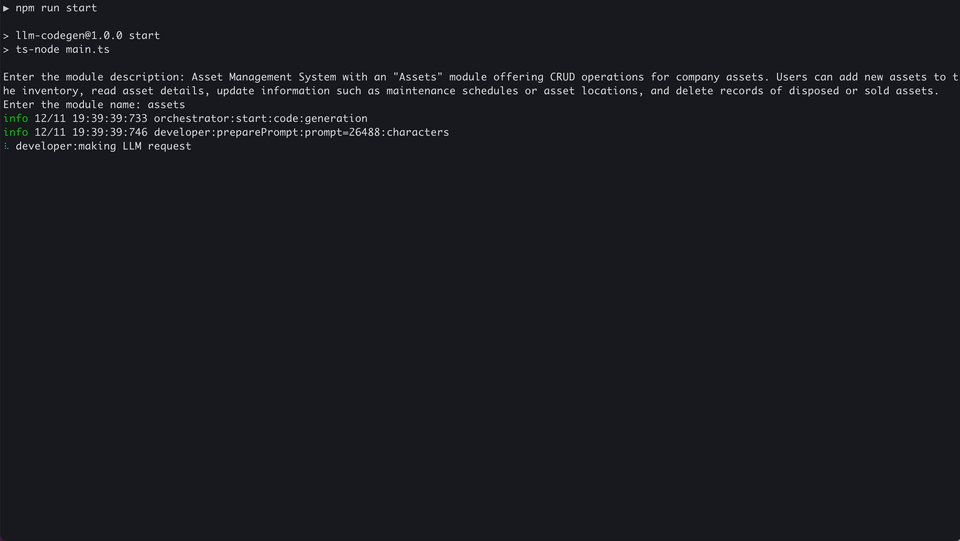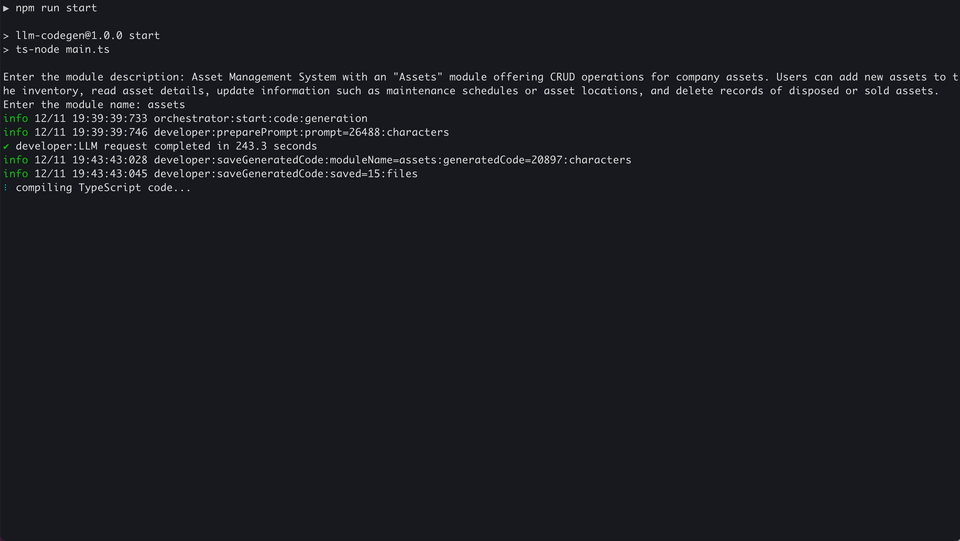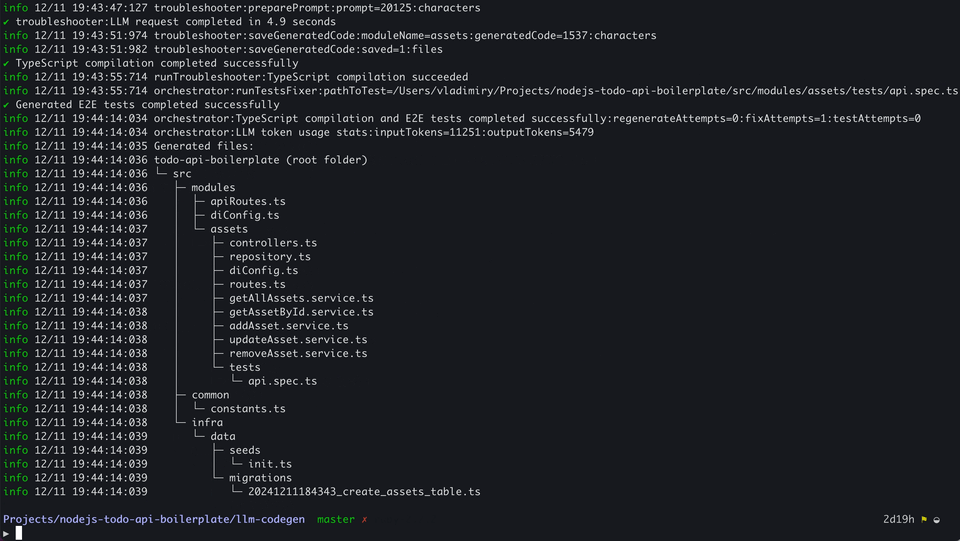
Below is another example that demonstrates how a compilation error was solved:
The following is an example of a generated orders Module code:

A key detail is that it can generate step by step code, starting with a module and adding others until all the required APIs are complete. This approach allows you to generate code for all the modules required in just a few command executions.
How it works
As mentioned above, all work is done by those micro-agents: Developer, Troubleshooter and TestsFixercontrolled by him Orchestrator. They are executed in the order listing, with the Developer Generating most of the code base. After each step generation step, a verification is made for missing files depending on their roles (for example, routes, controllers, services). If any file is missing, a new code generation attempt is made, including the instructions in the message about the files and missing examples for each role. Once the Developer Your work begins, TypeScript compilation begins. If any error is found, the Troubleshooter He takes over, passing the errors to the notice and waiting for the corrected code. Finally, when the compilation is successful, the E2E tests are executed. Whenever a test fails, the TestsFixer Start with specific instructions, ensuring that all the tests pass and the code remains clean.
All micro-agents derive from BaseAgent class and reuse actively its implementations of base methods. Here is the Developer Reference implementation:
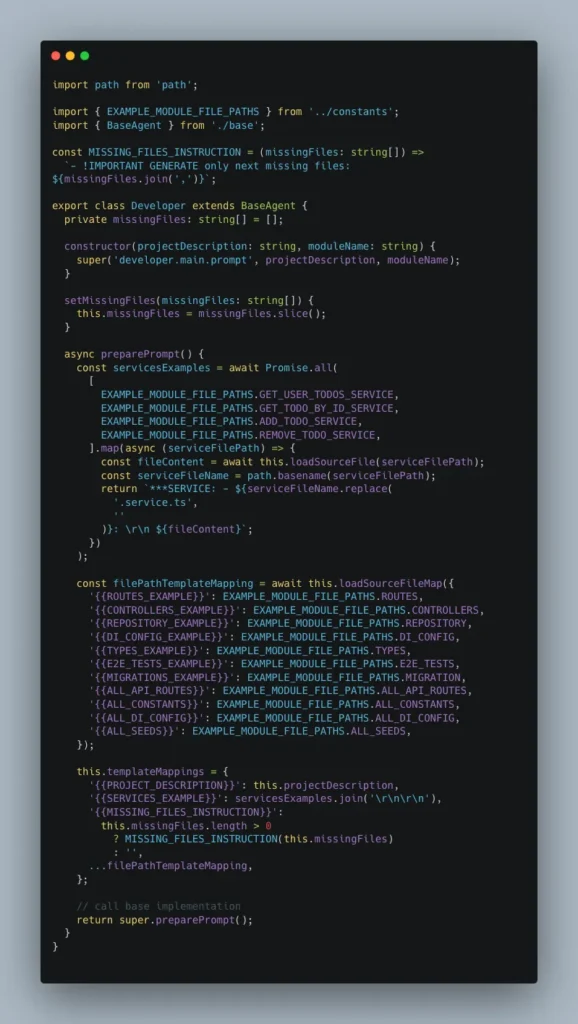
Each agent uses their specific notice. Look at this github link for the notice used by the Developer.
After dedicating a significant effort to research and tests, I refined the indications for all microgentes, which resulted in a clean and well structured code with very few problems.
During the development and tests, it was used with several descriptions of modules, ranging from simple to highly detailed. Here are some examples:
- The module responsible for library book management must handle endpoints for CRUD operations on books.
- The module responsible for the orders management. It must provide CRUD operations for handling customer orders. Users can create new orders, read order details, update order statuses or information, and delete orders that are canceled or completed. Order must have next attributes: name, status, placed source, description, image url
- Asset Management System with an "Assets" module offering CRUD operations for company assets. Users can add new assets to the inventory, read asset details, update information such as maintenance schedules or asset locations, and delete records of disposed or sold assets.Try with gpt-4o-mini and claude-3-5-sonnet-20241022 It showed the quality of the comparable output code, although the sonnet is more expensive. Claude haiku (claude-3–5-haiku-20241022), although cheaper and similar in price to gpt-4o-miniIt often produces non -compilable code. In general, with gpt-4o-miniA single code generation session consumes an average of about 11k input tokens and 15k output tokens. This is equivalent to a cost of approximately 2 cents per session, based on a 15 cents token price for 1 m input tokens and 60 cents for 1 m exit tokens (as of December 2024).
Below are anthropic use records that show token consumption:
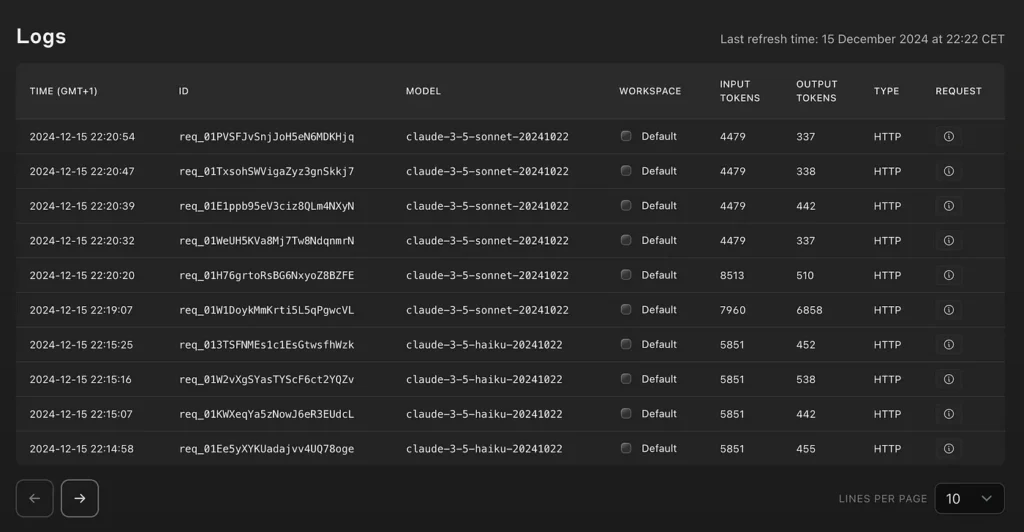
According to my experimentation in recent weeks, I conclude that, although there may still be some problems with the passing of the tests generated, 95% of the generated code is compileable and executable.
I hope you have found some inspiration here and serve as a starting point for your next API node.js or an update to your current project. If you have improvement suggestions, do not hesitate to contribute by sending public relations for code or rapid updates.
If you enjoyed this article, do not hesitate to applaud or share your thoughts in the comments, if ideas or questions. Thanks for reading and happy experiment!
UPDATE (February 9, 2025): The LLM-Codegen repository was updated with Speeek API support. It is cheaper than
gpt-4o-miniAnd it offers almost the same output quality, but it has a longer response time and sometimes fights with API application errors.






{kind=link}