 NEWSLETTER
NEWSLETTER
Copying from PDF files can be a challenging task. When pasting copied text or data, formatting often needs to be corrected, with spaces, alignment, and special characters everywhere. Cleaning it can take years.
Extracting content from PDF files can be complicated, but with the right tools and techniques, it can be done with ease. This comprehensive guide will walk you through different methods to copy various types of content from PDF files, making the extraction process faster and more efficient.
1. Use Adobe Acrobat Reader's Select tool to copy text
Adobe Acrobat Reader is among the most popular PDF viewers out there. If you do not want to install or register for additional software, use Acrobat Reader's built-in text selection tool.
Follow these steps to get started:
- Open your PDF in Adobe Acrobat Reader.
- Click the “Select Tool” button (arrow icon) on the toolbar to highlight the text in the PDF.
- Click and drag to select the text. You can select text on multiple pages if necessary.
- Highlight the text, right-click, select “Copy” or use Ctrl+C on Windows or Command+C on Mac.
- Paste the text using Ctrl+V or Cmd+V.
This method is ideal for simple PDF files composed primarily of text. You can manually copy the content into segments and paste it into your destination document. Unlike other PDF readers, Acrobat Reader preserves formatting well.
Acrobat Reader has problems with complex PDF files: those with multiple columns and images mixed with text, tables, and text on colored backgrounds. The copied text may lose formatting and be pasted as plain text, requiring manual cleanup or editing later.
It may not be ideal for mass extraction of text from PDF files. For example, processing supplier contracts and extracting key terms and clauses from hundreds of PDF files can be tedious and time-consuming. It is even more difficult to copy text from scanned pages.
In general, Acrobat Reader's built-in text copy feature works well for simple PDF files or for quickly capturing text from almost any PDF.
Do you just want to copy data from a bunch of PDF files? MS Excel's Get Data function works wonders. It can automatically extract tables and data from PDF files to Excel spreadsheets.
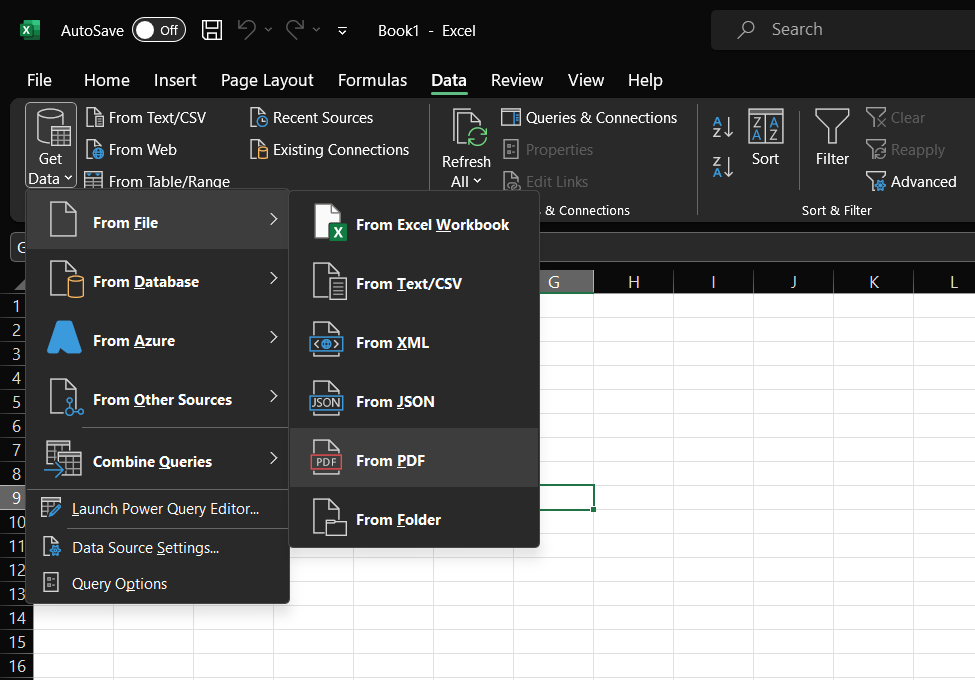
Follow these simple steps:
- Open Excel and go to the Data tab.
- Click Get Data > From File > From PDF.
- Select the PDF files you want to import data from. Excel will automatically detect and extract tables from PDF documents.
- The Import Data dialog box displays a preview of the data. Choose the tables you want to import and click Load.
- The extracted PDF data will be inserted into the spreadsheet as a table, resulting in clean data for analysis.
Data extraction works well for textual PDF files. You can select a table or multiple tables to import from one or more PDF files. Excel can intelligently separate data into rows and columns. It also allows users to add filters or transform imported data within Excel. This makes it easy to quickly get usable data from PDF files to Excel for later analysis and dashboards.
However, Excel has difficulty accurately extracting data from scanned documents or PDF files with complex layouts, such as columns of text or text over images. It works best with textual PDF files with clearly defined data tables and grid layouts. If your PDF data is neatly organized in tables, using Excel can save you tons of manual copy, paste, and reformat work.
You will need more advanced data extraction capabilities for unstructured data locked in scanned documents or complex reports.
3. Open the PDF using Google Docs or MS Word.
Google Docs and Microsoft Word are two of the most popular word processors. They now have built-in optical character recognition (OCR) capabilities to convert scanned images and documents into editable text.
Here's how you can take advantage of this:
- Open Google Docs or Word and go to File > Open.
- Select your PDF file. Google Docs/Word will extract the text and images from the PDF into a new document.
- Copy or edit the extracted text as necessary.
- Paste the copied text into any other application or document.
Note: You may need to accept the compatibility mode prompts before opening the PDF.
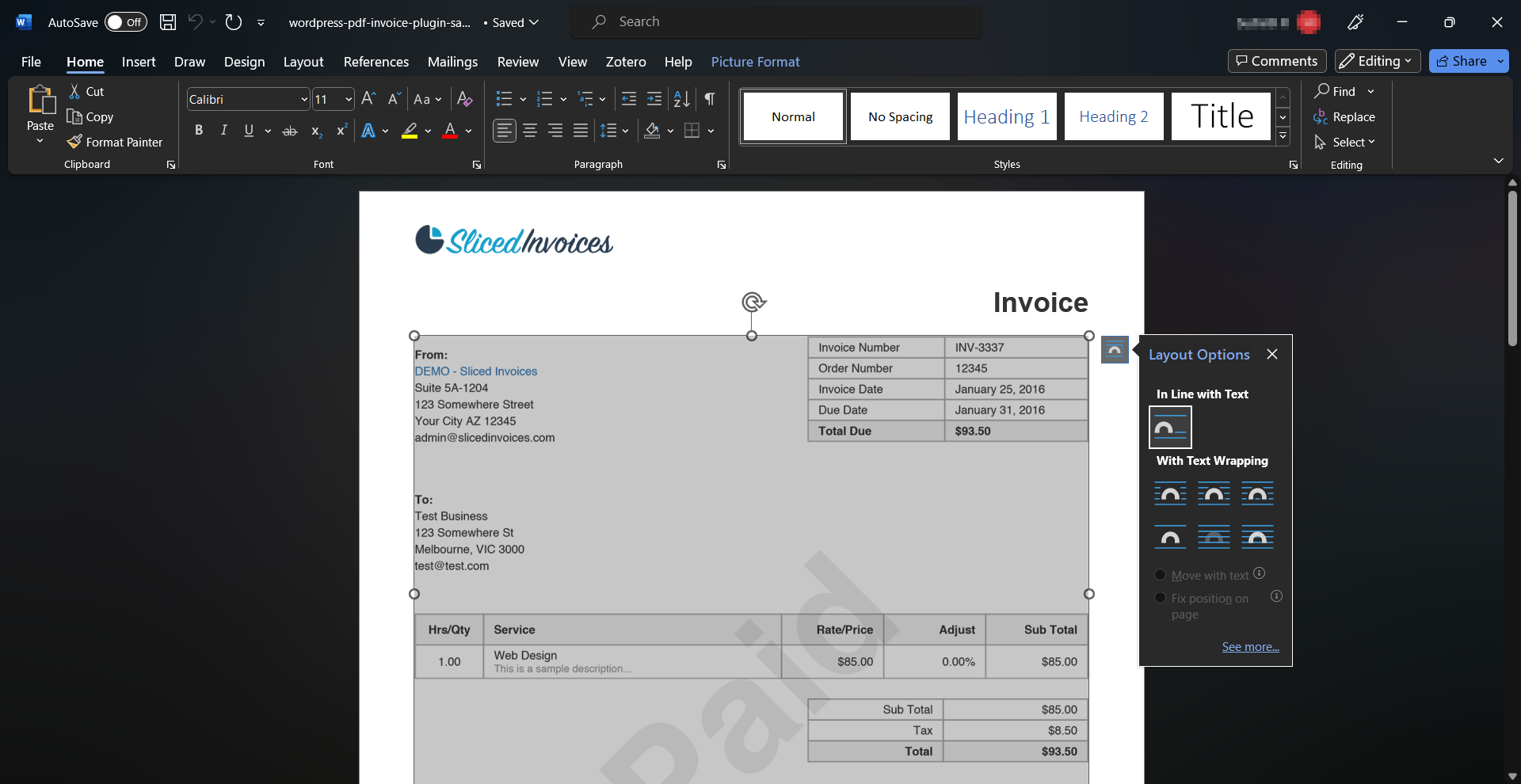
The extracted text retains basic formatting and can be edited in Google Docs or Word, allowing you to clean up the text, edit out typos, or make other changes before copying it.
Complex PDF layouts with multiple columns and images with text over them can pose challenges during conversion. The output document may have formatting problems or the text may be in the wrong order. So, while convenient for simple PDF files, Google Docs and Word can have problems with scanned documents or complex layouts.
In general, using Google Docs and Word to open and copy text from PDF files works well for everyday needs. However, more powerful PDF extraction tools are recommended for advanced data extraction from complex reports or bulk processing of contracts, legal documents, and other documents.
Dedicated tools with OCR (optical character recognition) capabilities can extract text from scanned documents or image-based PDF files. These convenient solutions allow you to upload your PDF file and receive the extracted text instantly without installing software.

Some of the popular online OCR tools include:
Numerous easy-to-use conversion tools available on the web can simplify the process of extracting text from a PDF document. These tools can handle a variety of output formats and can also make an image-based PDF searchable.
To use an online converter:
- Go to the tool's website.
- Upload your PDF file or enter the URL where it is hosted.
- Choose the output format: DOC, TXT, XLS, XLSX, JSON or CSV.
- Click “Convert” and wait for the extraction of all text to finish.
- Download the output file containing the extracted text and copy the required text.
Most online converters offer free basic use. However, certain advanced features and increased limits may require a paid subscription. Also, be aware of privacy policies before uploading sensitive data.
While convenient, these tools can fail with complex table layouts in PDF files. Traditional OCR tools often struggle to accurately extract text from complex layouts with columns of text, images, and other elements. Extracted data may require extensive manual cleaning before being used for analysis or reporting. Additionally, most online OCR converters have monthly page and file size limits that can quickly run out when processing large volumes of documents.
Nanonets is an ai-powered document processing platform with advanced automation and OCR capabilities to accurately extract text and data from PDF files and scanned documents.

Key capabilities
It can handle complex layouts with multiple columns of text, images, tables, and other elements with precision. Nanonets leverage machine learning (ML) and natural language processing (NLP) to “see” and “understand” document structures. This allows the extraction of text and data with context, maintaining the correct reading order and data relationships.
With built-in validation and approval workflows, you can ensure high-quality results before exporting extracted data. Nanonets also provides detailed accuracy reports to monitor OCR quality on various document types.
An example
Suppose you run a recruiting company that processes hundreds of PDF files daily. Your team must manually extract names, email addresses, phone numbers, skills, and experience from resumes and applications. With Nanonets, you can create an automated pipeline for OCRed PDFs and extract structured data from resumes at scale. The platform understands resume layouts and extracts precise data fields, enabling rapid processing of large volumes of documents with minimal manual work.
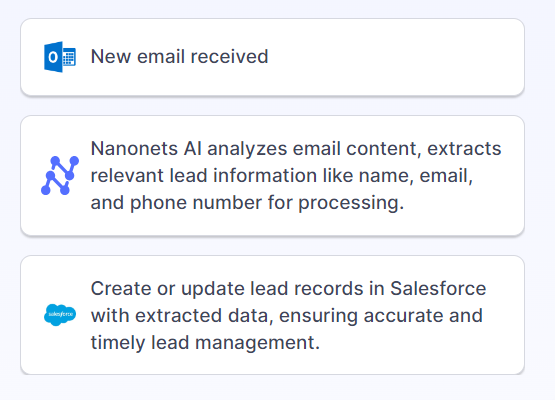
Additionally, Nanonets provides a robust API and integration ecosystem that allows you to connect it to your existing systems and workflows seamlessly. You can set up automatic import of documents from Gmail, Google Drive, OneDrive, and Dropbox. Integrations with tools like Microsoft Dynamics, QuickBooks, and Xero allow you to route extracted data to your business systems automatically. It also integrates with the popular workflow automation platform Zapier, which connects over 5,000 apps.
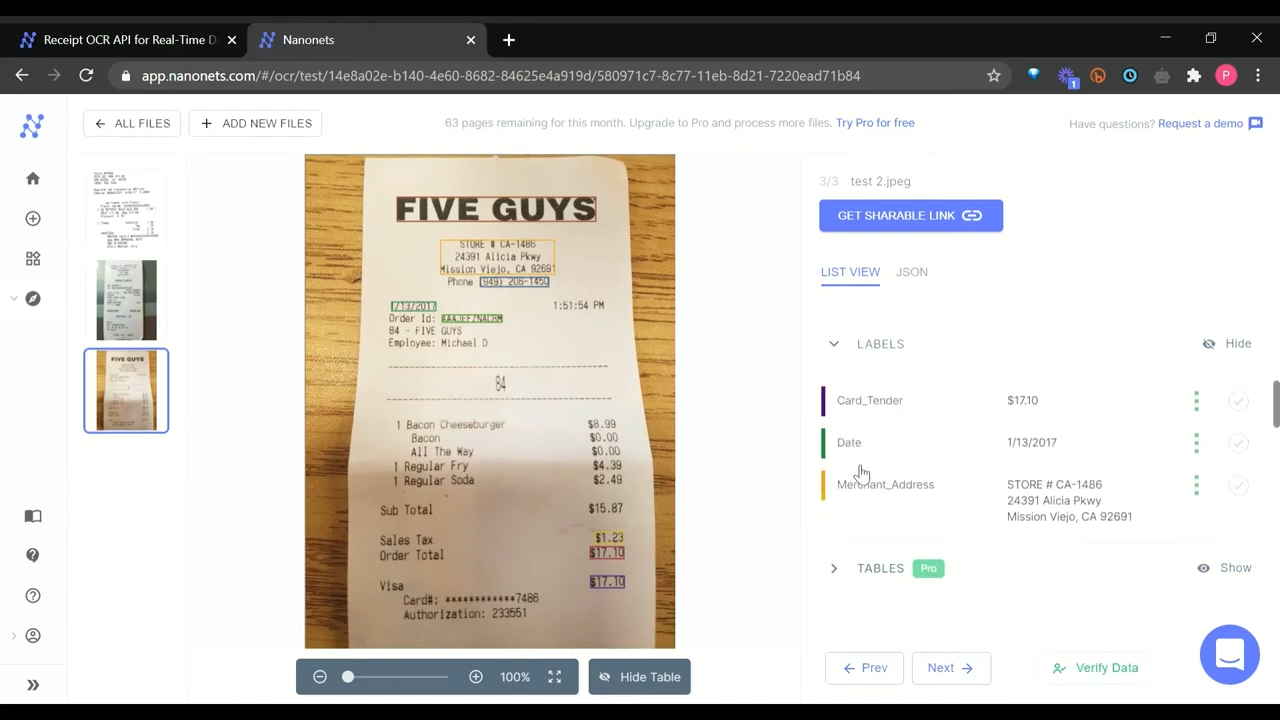
For example, you can create an automated workflow where OCRers resume PDF files uploaded to your Google Drive, pull names, emails, and phone numbers into a Google Sheet, and then use Zapier to add these contacts to your CRM and assign tasks to sales reps to follow up on high-potential candidates.
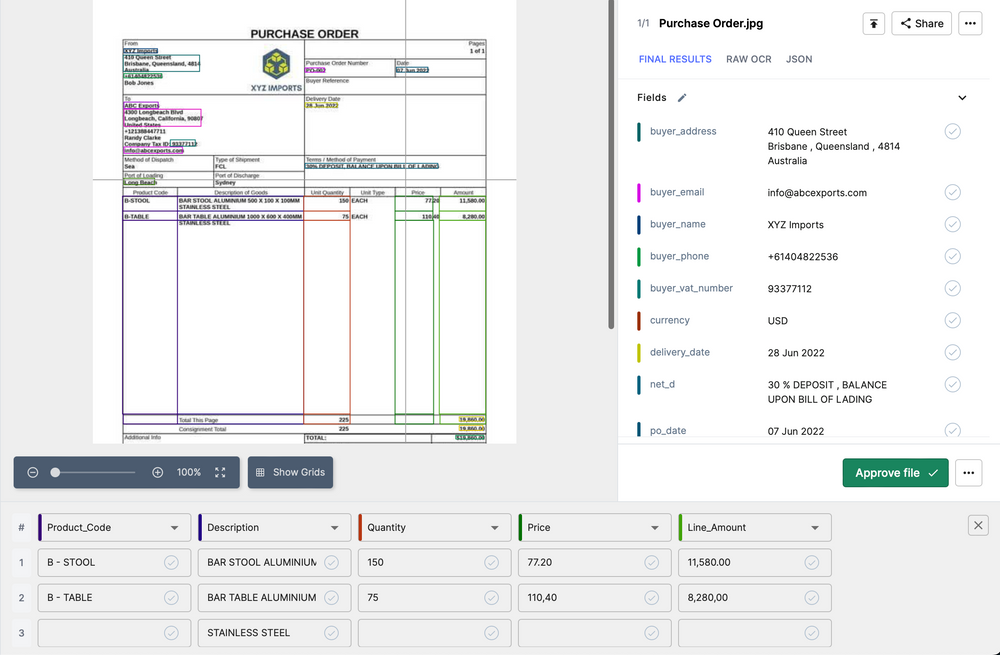
You can process documents in multiple currencies, languages, layouts, and formats without losing context. The ai learns from training data and manual interventions, improving its accuracy.
How to start?
Upload a sample set of 5 to 10 documents, write down the text you want to extract, and Nanonets will automatically create a custom ai model tailored to your documents. It can process thousands of pages per month while maintaining an accuracy rate of over 95%.
Nanonets are priced based on usage, allowing you to start small and expand as your needs grow. The first 500 pages are free, and you'll have access to three ai models, allowing you to test Nanonets on various document types before committing.
Final thoughts
Copying and pasting PDF files doesn't have to be a chore. You can simplify and streamline the process with the right tools and techniques.
The best approach depends on your specific needs and documents. Evaluate the complexity of your PDF files, workflow needs, data privacy policies, and more. Finding the solution that ticks all the boxes for your situation is critical to long-term efficiency. The goal is to eliminate the manual monotony of copying PDF text. Whether you handle a few documents a month or process thousands of pages daily, there are solutions to make your life easier.






{kind=link}