 NEWSLETTER
NEWSLETTER
In the current digital world, companies and individuals aim to provide instant and precise responses to visitors to the website. With a greater demand for perfect communication, Chatbots driven by ai have become a crucial tool for user interaction and offering useful information in a second fraction. Chatbots can search, understand and use the website data efficiently, making customers satisfy and improve customer experience for companies. In this article, we will explain how to build a chatbot that obtains information from a website, process it efficiently and participate in significant conversations with the help of QWEN-2.5, Langchain and Faiss. We will learn the main components and the integration process.
Learning objectives
- Understand the importance of chatbots propelled by ai for companies.
- Learn how to extract and process website data for the use of chatbot.
- Get information about the use of FAISS for efficient text recovery.
- Explore the role of embedded facials in Chatbot Intelligence.
- Discover how to integrate QWEN-2.5-32B to generate answers.
- Create an interactive chatbot interface using streamlit.
This article was published as part of the Blogathon of Data Sciences.
Why use a chatbot website?
Many companies struggle to handle large volumes of customer consultations efficiently. Traditional customer service equipment often face delays, which leads to frustrated users and increased operating costs. In addition, the hiring and training of support agents can be expensive, which makes it difficult for companies to scale effectively.
A chatbot helps offering instant and automated answers to user's questions without the need for a human. Companies can significantly reduce support costs, increase customer interaction and provide users with instantaneous answers to their questions. Chatbots based on AIs are able to handle large volumes of data, determine the correct information in seconds and react correctly depending on the context, making them very beneficial for companies today.
The website chatbots are mainly used on electronic learning platforms, electronic commerce websites, customer support platforms and news websites.
Also read: Build a writing wizard with Langchain and QWEN-2.5-32b
Key Chatbot Components
- Unstructured URL loader: Extract content from the website.
- Text divider: Draw great documents in manageable pieces.
- FAISS (facebook ai Simility Search): They storing and recovering documents efficiently.
- QWEN-2.5-32B: A powerful language model that includes consultations and generates answers.
- Rationalize: A frame to create an interactive chatbot interface.
How does this chatbot work?
Here is a flow diagram that explains the operation of our chatbot.
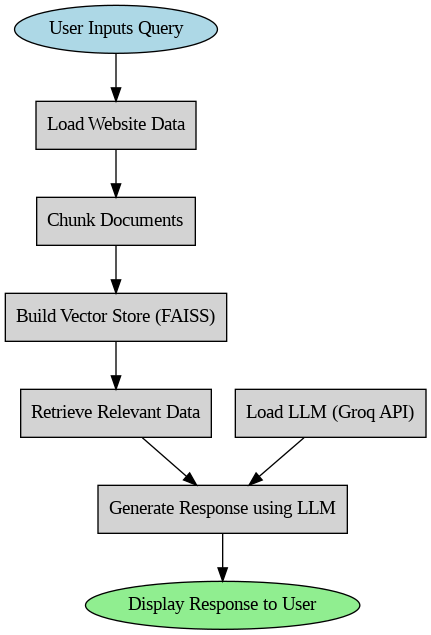
Building a personalized chatbot using Qwen-2.5-32b and Langchain
Now let's see how to build a Chatbot custom website using QWEN-2.5-32B, Langchain and Faiss.
Step 1: Base configuration
Let's start by configuring the previous requirements.
1. Environment configuration
# Create a Environment
python -m venv env
# Activate it on Windows
.\env\Scripts\activate
# Activate in MacOS/Linux
source env/bin/activate2. Install the requirements.txt
pip install -r https://raw.githubusercontent.com/Gouravlohar/Chatbot/refs/heads/main/requirements.txt3. API key configuration
Paste the API key in the .env file.
API_KEY="Your API KEY PASTE HERE"Now let's enter the real coding part.
Step 2: Windows event loop management (for compatibility)
import sys
import asyncio
if sys.platform.startswith("win"):
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())Ensures Windows compatibility by configuring the correct event loop policy for Asyncio, since Windows uses a different predetermined event loop.
Step 3: Import required libraries
import streamlit as st
import os
from dotenv import load_dotenv- Streamlit is used to create the chatbot user interface.
- The operating system is used to establish environment variables.
- Dotenv helps load the API keys from a .env file.
os.environ("STREAMLIT_SERVER_FILEWATCHER_TYPE") = "none" This disables the streamlit file observer to improve performance by reducing unnecessary monitoring of the file system.
Step 4: Import Langchain modules
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.document_loaders import UnstructuredURLLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_groq import ChatGroq
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate- Huggingfacedings : Convert text into vector embeddes.
- FAISS: It stores and recovers fragments of relevant documents based on consultations.
- Unstructured: Load Web URL text content.
- RecursiCharacterTextsplitter: Divide a large text into smaller pieces for processing.
- Chatg more: Use the API Groq for answers with ai.
- create_retrieval_chain – Build a pipe that recovers relevant documents before passing them to the LLM.
- create_stuff_documes_chain – Combine documents recovered in an adequate format for LLM processing.
Step 5: Cargo environment variables
load_dotenv()
groq_api_key = os.getenv("API_KEY")
if not groq_api_key:
st.error("Groq API Key not found in .env file")
st.stop()- Load the API GROQ key from the .env file.
- If the key is missing, the application shows an error and stops the execution.
1. Work to load website data
def load_website_data(urls):
loader = UnstructuredURLLoader(urls=urls)
return loader.load()- Use an unstructured to obtain content from a URL list.
2. Work to fragment documents
def chunk_documents(docs):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
return text_splitter.split_documents(docs)- Divide a large text into pieces of 500 characters with overlap of 50 characters for better context retention.
3. Work to build Faiss Vector Store
def build_vectorstore(text_chunks):
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
return FAISS.from_documents(text_chunks, embeddings)- Turn the text pieces into ull-minly-l-v2 vector inlays
- Stores in a FAISS vector database for efficient recovery.
4. Function to load QWEN-2.5-32b
def load_llm(api_key):
return ChatGroq(groq_api_key=api_key, model_name="qwen-2.5-32b", streaming=True)- Load the QWEN-2.5-32B model of GROQ to generate answers.
- It allows transmission for a real -time response experience.
5. Aerodynamic User Interface Settings
st.title("Custom Website Chatbot(Analytics Vidhya)")6. Conversation history configuration
if "conversation" not in st.session_state:
st.session_state.conversation = ()- Chat stores in the story of Chat at St.Session_state for messages to persist in interactions.
Step 6: Obtain and process website data
urls = ("https://www.analyticsvidhya.com/")
docs = load_website_data(urls)
text_chunks = chunk_documents(docs)- Load Content of Analytics Vidhya.
- Divide the content into small pieces.
Step 7: Vector Store Faiss Building
vectorstore = build_vectorstore(text_chunks)
retriever = vectorstore.as_retriever()Storage stores processed texts in FAISS. Then converts the FAISS Vectorstore into a retriever that can obtain relevant fragments according to user consultations.
Step 8: Loading the Groq Llm
llm = load_llm(groq_api_key)Step 9: Recovery chain configuration
system_prompt = (
"Use the given context to answer the question. "
"If you don't know the answer, say you don't know. "
"Use detailed sentences maximum and keep the answer accurate. "
"Context: {context}"
)
prompt = ChatPromptTemplate.from_messages((
("system", system_prompt),
("human", "{input}"),
))
combine_docs_chain = create_stuff_documents_chain(llm, prompt)
qa_chain = create_retrieval_chain(
retriever=retriever,
combine_docs_chain=combine_docs_chain
)- Define a system application to guarantee precise answers based on the context.
- Uses Chatprompttemplate To format the interactions of the chatbot.
- Combine recovered documents (combine_docs_chain) to provide context to the LLM.
This step creates a Qa_chain When linking the retriever (FAISS) with the LLM, ensuring that the answers are based on the content recovered from the website.
Step 10: Show Chat's history
for msg in st.session_state.conversation:
if msg("role") == "user":
st.chat_message("user").write(msg("message"))
else:
st.chat_message("assistant").write(msg("message"))This shows previous conversation messages.
Step 11: Accept user entry
user_input = st.chat_input("Type your message here") if hasattr(st, "chat_input") else st.text_input("Your message:")- Use St.Chat_input (if available) for a better chat user interface.
- Return to St.text_input for compatibility.
Step 12: Process User Consultations
if user_input:
st.session_state.conversation.append({"role": "user", "message": user_input})
if hasattr(st, "chat_message"):
st.chat_message("user").write(user_input)
else:
st.markdown(f"**User:** {user_input}")
with st.spinner("Processing..."):
response = qa_chain.invoke({"input": user_input})
assistant_response = response.get("answer", "I'm not sure, please try again.")
st.session_state.conversation.append({"role": "assistant", "message": assistant_response})
if hasattr(st, "chat_message"):
st.chat_message("assistant").write(assistant_response)
else:
st.markdown(f"**Assistant:** {assistant_response}")This code manages the user entry, recovery and response generation in a chatbot. When a user enters a message, it is stored in St.Seion_state. Conversation and is shown in the chat interface. A load spinner appears while the chatbot processes the consultation using qa_chain.invoke ({“entry”: user_input})that recovers relevant information and generates an answer. The assistant response is extracted from the response dictionary, ensuring a message support if no answer is found. Finally, the assistant response is stored and shown, maintaining a soft and interactive chat experience.
Get the full code in Github here
Final output

Try the chatbot
Now let's try some indications in the chatbot that we have just built.
Immediate: “Can you list some ways to interact with the Analytics Vidhya community?”
Answer:

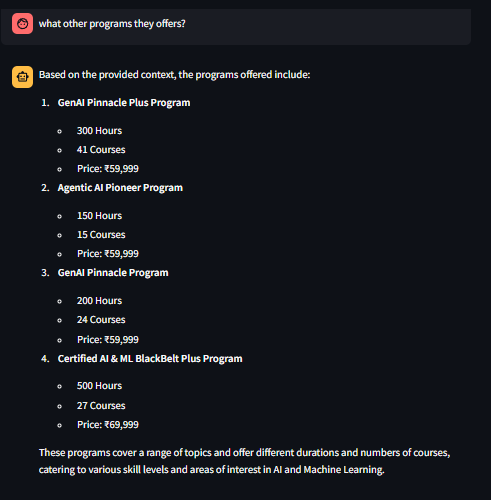
Immediate: “What other programs offer?”
Answer:
Conclusion
IA chatbots have transformed the way people communicate on the Internet. Using advanced models such as QWEN-2.5-32B, companies and people can make sure their chatbot responds well and properly. As technology continues to progress, the use of ia chatbots on websites will be the order of the day, and people can easily access information.
In the future, developments such as having long conversations, voice questioning and interacting with larger knowledge groups can further advance in chatbots.
Key control
- The chatbot obtains content of the Analytic Vidhya website, processes it and stores it in a Faiss Vector database for rapid recovery.
- Directs the content of the website in fragments of 500 characters with a 50 -characters overlap, which guarantees a better context retention by recovering the relevant information.
- The chatbot uses QWEN-2.5-32B to generate answers, taking advantage of the fragments of recovered documents to provide precise and aware responses of the context.
- Users can interact with chatbot using a chat interface in optimistic, and conversation history is stored for interactions without problems.
The means shown in this article are not owned by Analytics Vidhya and are used at the author's discretion.
Frequent questions
A. Use an unstructured Langchain to extract specified URL content.
A. FAISS (Search for similarity of facebook) helps to store and recover relevant text fragments efficiently depending on user consultations.
A. The chatbot uses the QWEN-2.5-32B of Groq, a powerful LLM, to generate responses based on the recovered website content.
TO. Yeah! Simply modify the URL list to include more websites, and the chatbot will obtain, process and recover information from them.
A. Follow a recovery generation approach (RAG), which means that it recovers the relevant data of the first website and then generates an answer using LLM.

Log in to continue reading and enjoying content cured by experts.
(Tagstotranslate) Blogathon





