 NEWSLETTER
NEWSLETTER

Image by author
Gemini is a new model developed by Google and Bard is usable again. With Gemini, it is now possible to get almost perfect answers to your queries by providing them with images, audio and text.
In this tutorial, we will learn about the Gemini API and how to configure it on your machine. We'll also explore various Python API features, including text generation and image understanding.
technology/ai/google-gemini-ai/%23introducing-gemini&sa=D&source=editors&ust=1702928279671913&usg=AOvVaw3sXLHGX0QJRUSslBADx8XB” target=”_blank” rel=”noopener”>Gemini is a new ai model developed through collaboration between Google teams, including Google Research and Google DeepMind. It was specifically created to be multimodal, meaning it can understand and work with different types of data such as text, code, audio, images, and video.
Gemini is the largest and most advanced ai model developed by Google to date. It has been designed to be highly flexible and able to operate efficiently on a wide range of systems, from data centers to mobile devices. This means it has the potential to revolutionize the way businesses and developers can build and scale ai applications.
Here are three versions of the Gemini model designed for different use cases:
- Gemini Ultra: The largest and most advanced ai capable of performing complex tasks.
- Professional Gemini: A balanced model that has good performance and scalability.
- Gemini Nano: More efficient for mobile devices.
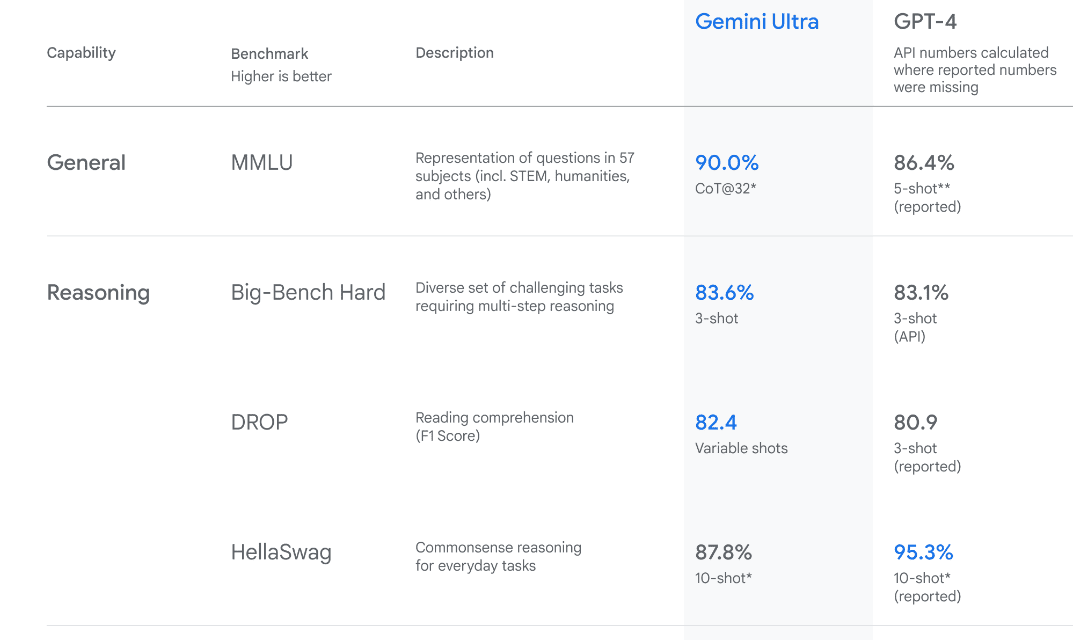
Picture of technology/ai/google-gemini-ai/%23performance&sa=D&source=editors&ust=1702928279673520&usg=AOvVaw0ubnWtpo19mhdYvbLKd1Jm” target=”_blank” rel=”noopener”>Introducing Gemini
Gemini Ultra has next-generation performance, outperforming GPT-4 in several metrics. It is the first model to outperform human experts on the Massive Multitask Language Understanding benchmark, which assesses global knowledge and problem solving across 57 diverse topics. This shows your advanced understanding and problem-solving capabilities.
To use the API, we first need to get an API key which you can get from here: https://ai.google.dev/tutorials/setup
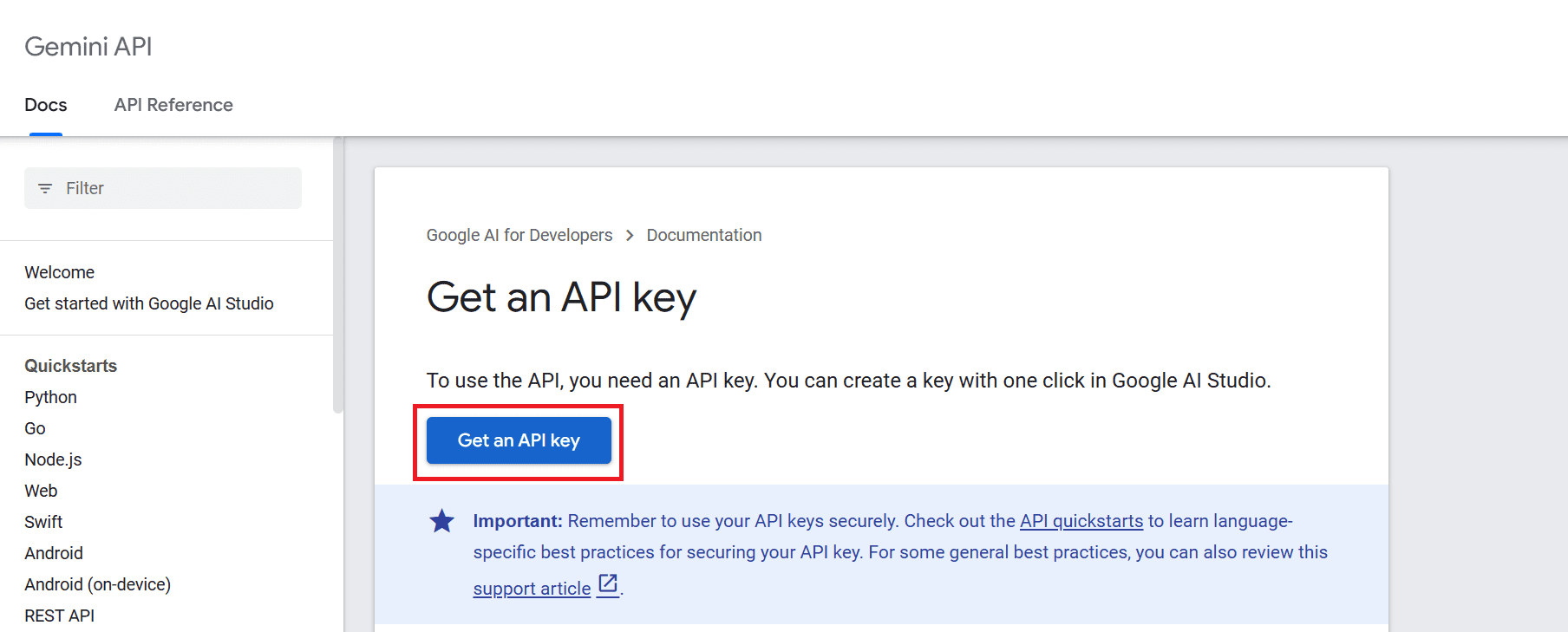
After that, click on the “Get an API key” button and then click on “Create API key in a new project”.
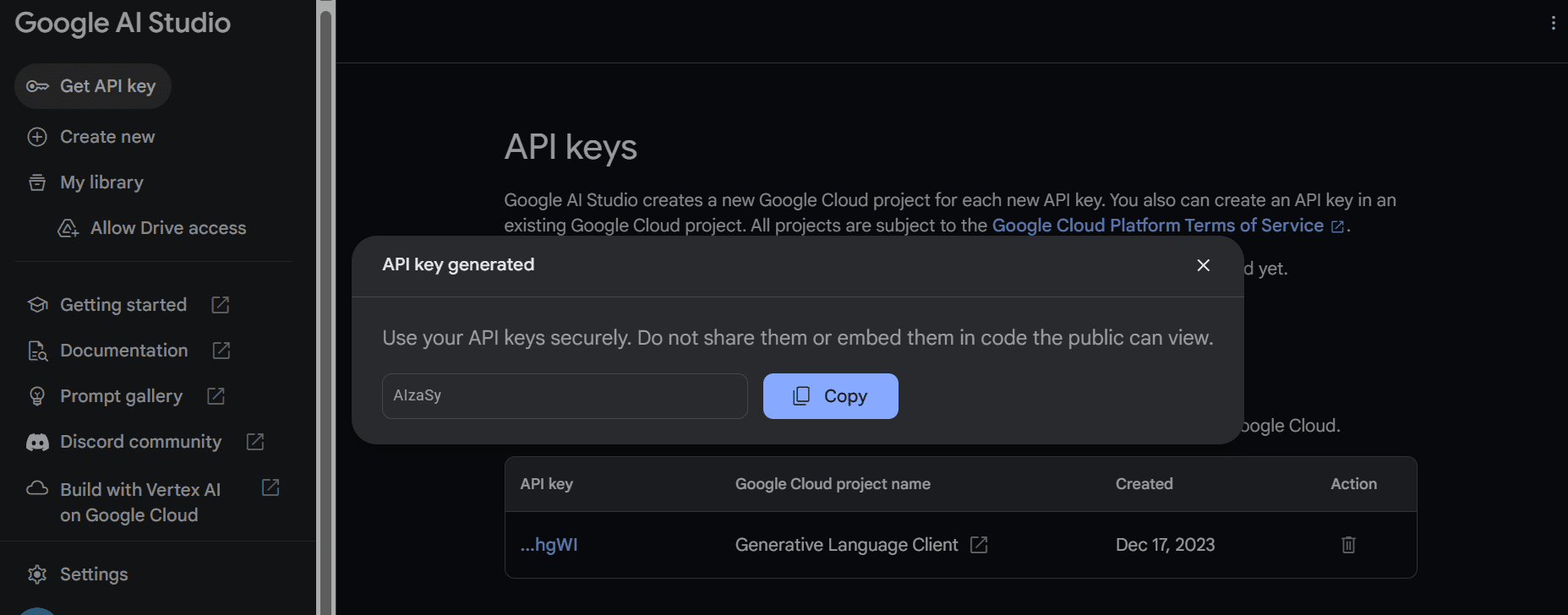
Copy the API key and set it as an environment variable. We are using Deepnote and we find it quite easy to set the key with the name “GEMINI_API_KEY”. Simply go to the integration, scroll down and select environment variables.
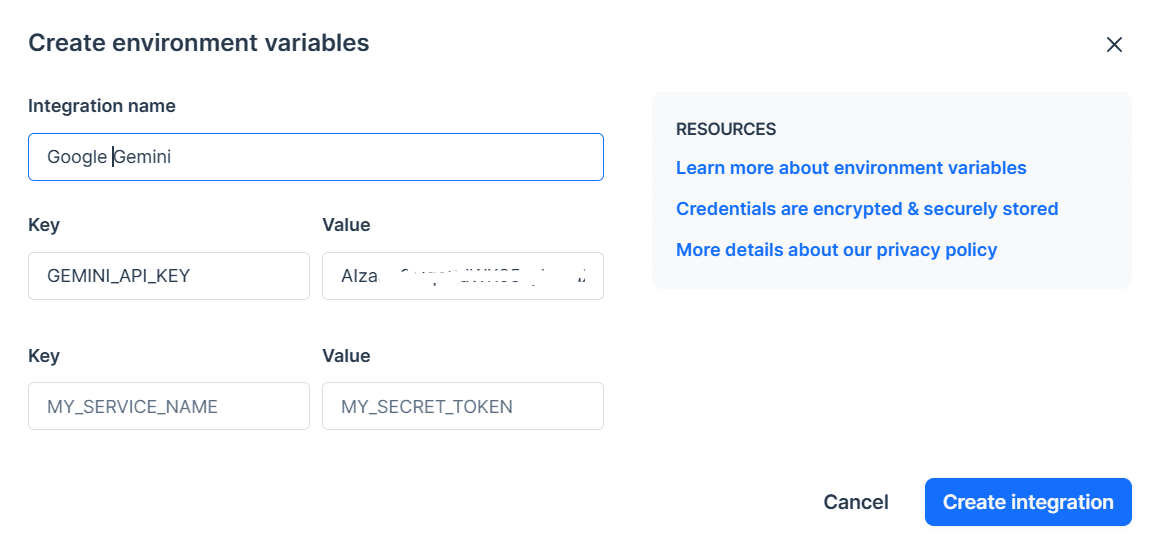
In the next step, we will install the Python API using PIP:
pip install -q -U google-generativeaiAfter that, we will set the API key to Google's GenAI and start the instance.
import google.generativeai as genai
import os
gemini_api_key = os.environ("GEMINI_API_KEY")
genai.configure(api_key = gemini_api_key)After setting up the API key, using the Gemini Pro model to generate content is simple. Provide a message to the `generate_content` function and display the result as Markdown.
from IPython.display import Markdown
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("Who is the GOAT in the NBA?")
Markdown(response.text)This is awesome, but I don't agree with the list. However, I understand that it comes down to personal preference.

Gemini can generate multiple responses, called candidates, for a single message. You can select the most suitable one. In our case, we only had one response.

Let's ask you to write a simple game in Python.
response = model.generate_content("Build a simple game in Python")
Markdown(response.text)The result is simple and to the point. Most LLMs start by explaining Python code rather than writing it.

You can customize your response using the `generation_config` argument. We are limiting the candidate count to 1, adding the stopword “space” and setting maximum tokens and temperature.
response = model.generate_content(
'Write a short story about aliens.',
generation_config=genai.types.GenerationConfig(
candidate_count=1,
stop_sequences=('space'),
max_output_tokens=200,
temperature=0.7)
)
Markdown(response.text)As you can see, the response stopped before the word “space.” Amazing.

You can also use the `stream` argument to stream the response. It is similar to the Anthropic and OpenAI APIs but faster.
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("Write a Julia function for cleaning the data.", stream=True)
for chunk in response:
print(chunk.text)
In this section we will load Masood Aslami's photo and use it to test the multimodality of Gemini Pro Vision.
Load the images into the `PIL` and display them.
import PIL.Image
img = PIL.Image.open('images/photo-1.jpg')
imgWe have a high quality photo of the Rua Augusta Arch.

Let's load the Gemini Pro Vision model and provide the image.
model = genai.GenerativeModel('gemini-pro-vision')
response = model.generate_content(img)
Markdown(response.text)The model accurately identified the palace and provided additional information about its history and architecture.

Let's provide the same image to GPT-4 and ask it about the image. Both models have provided almost similar answers. But I like GPT-4's answer better.

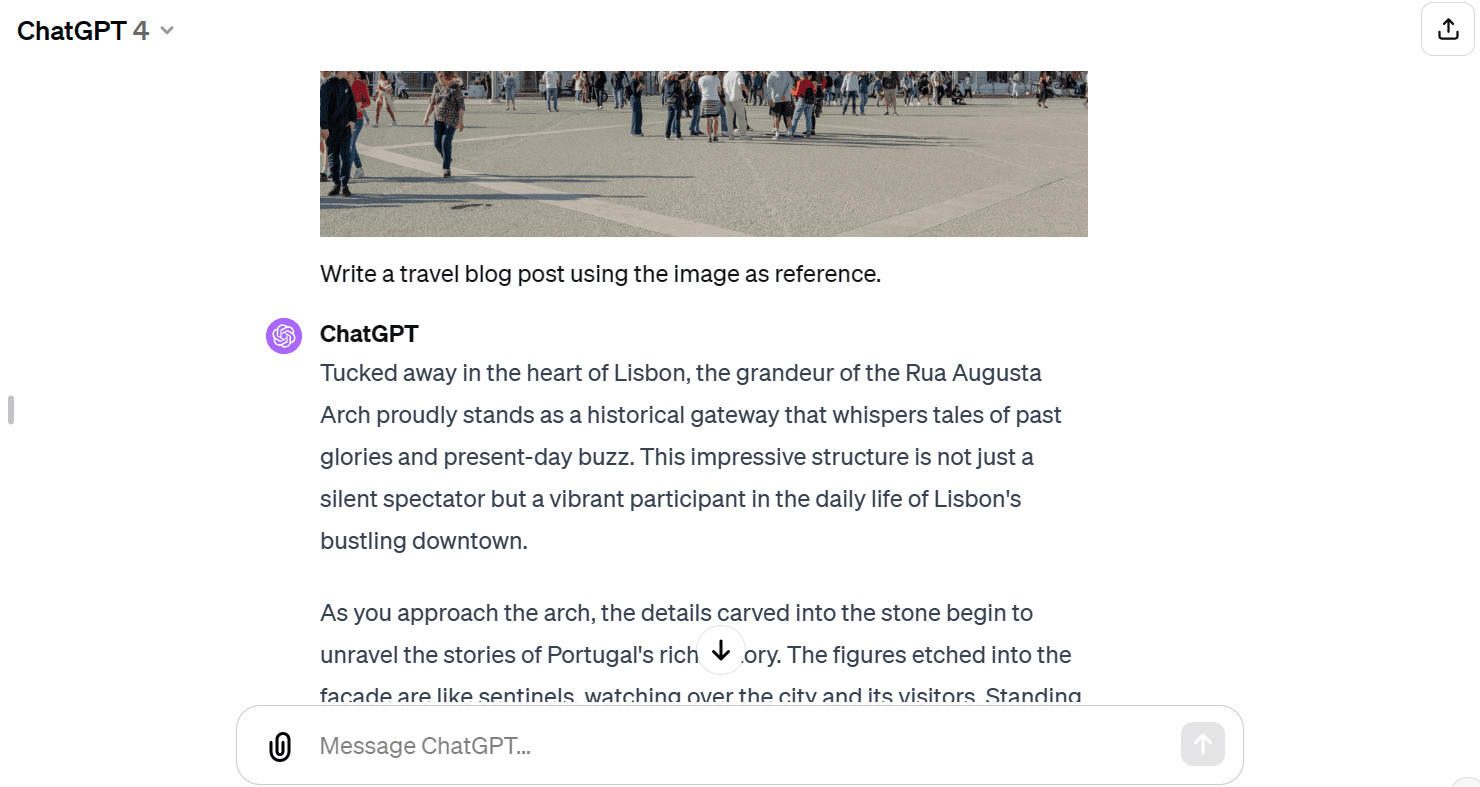
Now we will provide the text and image to the API. We have asked the vision model to write a travel blog using the image as a reference.
response = model.generate_content(("Write a travel blog post using the image as reference.", img))
Markdown(response.text)You have provided me with a short blog. I was expecting a longer format.

Compared to GPT-4, the Gemini Pro Vision model has struggled to generate a long-form blog.
We can configure the model to have a two-way chat session. In this way, the model remembers the context and the response using previous conversations.
In our case, we started the chat session and asked the model to help me get started with the Dota 2 game.
model = genai.GenerativeModel('gemini-pro')
chat = model.start_chat(history=())
chat.send_message("Can you please guide me on how to start playing Dota 2?")
chat.historyAs you can see, the `chat` object saves the user's history and chat mode.

We can also display them in Markdown style.
for message in chat.history:
display(Markdown(f'**{message.role}**: {message.parts(0).text}'))
Let's ask the follow-up question.
chat.send_message("Which Dota 2 heroes should I start with?")
for message in chat.history:
display(Markdown(f'**{message.role}**: {message.parts(0).text}'))We can scroll down and see the full session with the model.

Embedding models are becoming increasingly popular for context-sensitive applications. The Gemini embedding-001 model allows words, sentences or entire documents to be represented as dense vectors that encode semantic meaning. This vector representation makes it possible to easily compare the similarity between different text fragments by comparing their corresponding embedding vectors.
We can provide the content to `embed_content` and convert the text to embeds. It's that easy.
output = genai.embed_content(
model="models/embedding-001",
content="Can you please guide me on how to start playing Dota 2?",
task_type="retrieval_document",
title="Embedding of Dota 2 question")
print(output('embedding')(0:10))(0.060604308, -0.023885584, -0.007826327, -0.070592545, 0.021225851, 0.043229062, 0.06876691, 0.049298503, 0.039964676, 0.08291664)We can convert multiple pieces of text into embeds by passing a list of strings to the 'content' argument.
output = genai.embed_content(
model="models/embedding-001",
content=(
"Can you please guide me on how to start playing Dota 2?",
"Which Dota 2 heroes should I start with?",
),
task_type="retrieval_document",
title="Embedding of Dota 2 question")
for emb in output('embedding'):
print(emb(:10))(0.060604308, -0.023885584, -0.007826327, -0.070592545, 0.021225851, 0.043229062, 0.06876691, 0.049298503, 0.039964676, 0.08291664)
(0.04775657, -0.044990525, -0.014886052, -0.08473655, 0.04060122, 0.035374347, 0.031866882, 0.071754575, 0.042207796, 0.04577447)If you're having trouble reproducing the same result, check out my Deep Notes Workspace.
There are so many advanced features that we didn't cover in this introductory tutorial. You can learn more about the Gemini API by going to ai.google.dev/tutorials/python_quickstart%23generate_text_from_text_inputs&sa=D&source=editors&ust=1702928279692923&usg=AOvVaw3qwfMggQe6PvEDm5hWt7as” target=”_blank” rel=”noopener”>Gemini API: Quick Start with Python.
In this tutorial, we learned about Gemini and how to access the Python API to generate responses. In particular, we have learned about text generation, visual understanding, streaming, conversation history, custom output, and embedding. However, this only scratches the surface of what Gemini can do.
Feel free to share with me what you've created using the free Gemini API. The possibilities are unlimited.
Abid Ali Awan (@1abidaliawan) is a certified professional data scientist who loves building machine learning models. Currently, he focuses on content creation and writing technical blogs on data science and machine learning technologies. Abid has a Master's degree in technology Management and a Bachelor's degree in Telecommunications Engineering. His vision is to build an artificial intelligence product using a graph neural network for students struggling with mental illness.






{kind=link}