
Ideal generative ai versus reality
Basic LLMs have read every byte of text they could find and their chatbot counterparts can be encouraged to have intelligent conversations and asked to perform specific tasks. Access to comprehensive information is democratized; you no longer need to figure out the right keywords to search for or choose sites to read. However, LLMs are prone to rambling and usually respond with the statistically most likely answer you want to hear (flattery) an inherent result of the transformation model. Extracting 100% accurate information from an LLM's knowledge base does not always produce reliable results.
Chat LLMs are notorious for inventing citations to scientific papers or court cases that don't exist. technology/2023/jun/23/two-us-lawyers-fined-submitting-fake-court-citations-chatgpt” target=”_blank” rel=”noopener”>Lawyers file suit against airline It included quotes from court cases that never actually happened. A 2023 study reportedthat when ChatGPT is asked to include citations, it only provided references that exist only 14% of the time. Fudging sources, rambling, and offering inaccuracies to appease the request is called hallucination, a major hurdle to overcome before ai is fully adopted and trusted by the masses.
One way to counter LLMs' fabrication of false sources or the appearance of inaccuracies is recovery-augmented generation (RAG). Not only can RAG reduce LLMs' tendency to hallucinate, but it also offers other advantages.
These advantages include access to an up-to-date knowledge base, specialization (e.g by providing private data sources), empowering models with information beyond that stored in parametric memory (enabling smaller models) and the potential to follow up with more legitimate reference data.
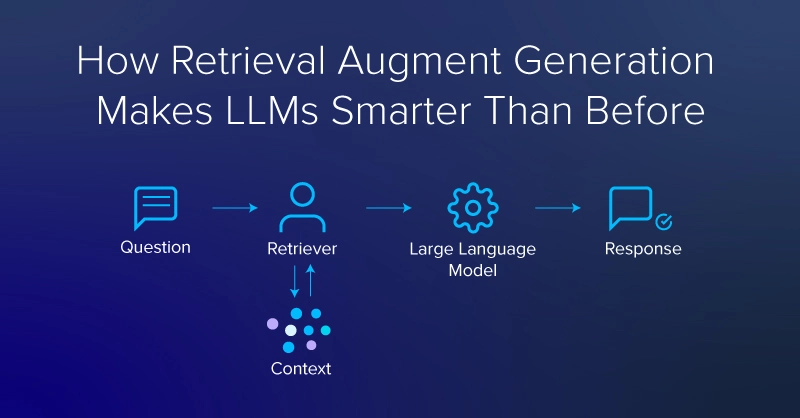
What is RAG (Recovery Augmented Generation)?
Retrieval-augmented generation (RAG) is a deep learning architecture implemented in LLMs and Transformer networks that retrieves relevant documents or other fragments and adds them to the context window to provide additional information, helping an LLM generate useful answers. A typical RAG system would have two main modules: retrieval and generation.
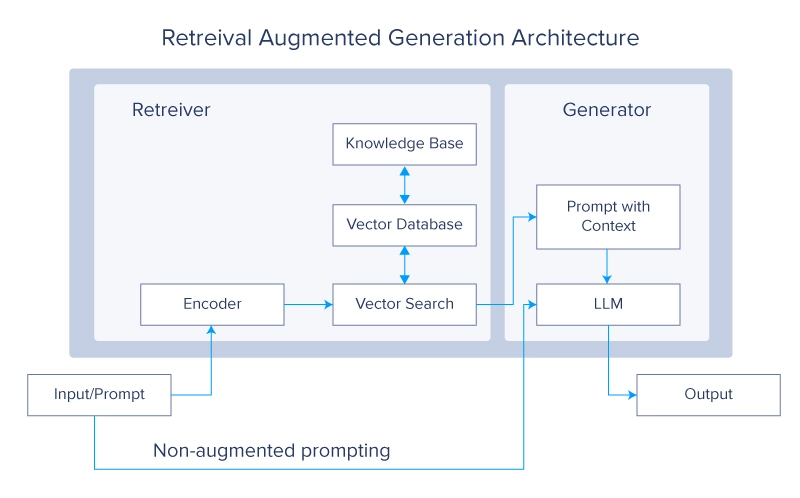
The main reference for RAG is a article by Lewis et al. from facebook. In the paper, the authors use a pair of BERT-based document encoders to transform queries and documents by embedding the text into a vector format. These embeddings are then used to identify topto (typically 5 or 10) documents via a maximum inner product search (MIPS). As the name suggests, MIPS is based on the inner (or dot) product of the encoded vector representations of the query and those of a precomputed vector database for the documents used as a nonparametric external store.
As described in Lewis's article et al.The RAG was designed to enhance LLMs on knowledge-intensive tasks that “humans could not reasonably be expected to perform without access to an external knowledge source.” Consider taking an open-book exam and a non-open-book exam and you’ll have a good indication of how the RAG might complement LLM-based systems.
RAG library with a hug face
Luis et al. The RAG models have been open-sourced on the Hugging Face Hub, so we can experiment with the same models used in the article. A new Python 3.8 virtual environment with virtualenv is recommended.
virtualenv my_env --python=python3.8
source my_env/bin/activateAfter activating the environment, we can install dependencies using pip: Hugging Face transformers and datasets, facebook's FAISS library that RAG uses for vector search, and PyTorch to use as a backend.
pip install transformers
pip install datasets
pip install faiss-cpu==1.8.0
#https://pytorch.org/get-started/locally/ to
#match the pytorch version to your system
pip install torchLuis et al. Two different versions of RAG were implemented: rag-sequence and rag-token. Rag-sequence uses the same retrieved document to augment the generation of a complete sequence, while rag-token can use different fragments for each token. Both versions use the same Hugging Face classes for tokenization and retrieval, and the API is very similar, but each version has a unique class for generation. These classes are imported from the transformers library.
from transformers import RagTokenizer, RagRetriever
from transformers import RagTokenForGeneration
from transformers import RagSequenceForGenerationThe first time you instantiate the RagRetriever model with the default dataset “wiki_dpr”, a substantial download (about 300 GB) will be initiated. If you have a large data drive and want Hugging Face to use that (instead of the default cache folder on your home drive), you can set a shell variable, HF_DATASETS_CACHE.
# in the shell:
export HF_DATASETS_CACHE="/path/to/data/drive"
# ^^ add to your ~/.bashrc file if you want to set the variableMake sure the code is working before downloading the entire wiki_dpr dataset. To avoid the big download until it's ready, you can pass use_dummy_dataset=True when instantiating the retriever. It will also instantiate a tokenizer to convert strings to integer indices (which correspond to tokens in a vocabulary) and vice versa. The sequence and token versions of RAG use the same tokenizer. The RAG sequence (rag-sequence) and the RAG token (rag-token) each have a fine-tuning (e.g rag-token-nq) and base versions (e.g rag token base).
tokenizer = RagTokenizer.from_pretrained(\
"facebook/rag-token-nq")
token_retriever = RagRetriever.from_pretrained(\
"facebook/rag-token-nq", \
index_name="compressed", \
use_dummy_dataset=False)
sequence_retriever = RagRetriever.from_pretrained(\
"facebook/rag-sequence-nq", \
index_name="compressed", \
use_dummy_dataset=False)
dummy_retriever = RagRetriever.from_pretrained(\
"facebook/rag-sequence-nq", \
index_name="exact", \
use_dummy_dataset=True)
token_model = RagTokenForGeneration.from_pretrained(\
"facebook/rag-token-nq", \
retriever=token_retriever)
seq_model = RagTokenForGeneration.from_pretrained(\
"facebook/rag-sequence-nq", \
retriever=seq_retriever)
dummy_model = RagTokenForGeneration.from_pretrained(\
"facebook/rag-sequence-nq", \
retriever=dummy_retriever)Once your models have been instantiated, you can provide a query, convert it into tokens, and pass it to the model's “generate” function. We will compare the results of rag-sequence, rag-token, and RAG using a fetcher against the dummy version of the wiki_dpr dataset. Note that these rag models are not case sensitive.
query = "what is the name of the oldest tree on Earth?"
input_dict = tokenizer.prepare_seq2seq_batch(\
query, return_tensors="pt")
token_generated = token_model.generate(**input_dict) token_decoded = token_tokenizer.batch_decode(\
token_generated, skip_special_tokens=True)
seq_generated = seq_model.generate(**input_dict)
seq_decoded = seq_tokenizer.batch_decode(\
seq_generated, skip_special_tokens=True)
dummy_generated = dummy_model.generate(**input_dict)
dummy_decoded = seq_tokenizer.batch_decode(\
dummy_generated, skip_special_tokens=True)
print(f"answers to query '{query}': ")
print(f"\t rag-sequence-nq: {seq_decoded(0)},"\
f" rag-token-nq: {token_decoded(0)},"\
f" rag (dummy): {dummy_decoded(0)}")>> answers to query 'What is the name of the oldest tree on Earth?': Prometheus was the oldest tree discovered until 2012, with its innermost, extant rings exceeding 4862 years of age.
>> rag-sequence-nq: prometheus, rag-token-nq: prometheus, rag (dummy): 4862In general, rag-token is correct more often than rag-sequence (although both are usually correct), and rag-sequence is correct more often than RAG when using a retriever with a dummy dataset.
“What kind of context does the retriever provide?” you might ask. To find out, we can deconstruct the generation process. Using seq_retriever and seq_model instantiated as above, we query “What is the name of the oldest tree on Earth?”
query = "what is the name of the oldest tree on Earth?"
inputs = tokenizer(query, return_tensors="pt")
input_ids = inputs("input_ids")
question_hidden_states = seq_model.question_encoder(input_ids)(0)
docs_dict = seq_retriever(input_ids.numpy(),\
question_hidden_states.detach().numpy(),\
return_tensors="pt")
doc_scores = torch.bmm(\
question_hidden_states.unsqueeze(1),\
docs_dict("retrieved_doc_embeds")\
.float().transpose(1, 2)).squeeze(1)
generated = model.generate(\
context_input_ids=docs_dict("context_input_ids"),\
context_attention_mask=\
docs_dict("context_attention_mask"),\
doc_scores=doc_scores)
generated_string = tokenizer.batch_decode(\
generated,\
skip_special_tokens=True)
contexts = tokenizer.batch_decode(\
docs_dict("context_input_ids"),\
attention_mask=docs_dict("context_attention_mask"),\
skip_special_tokens=True)
best_context = contexts(doc_scores.argmax())We can code our model to print the “best context” variable to see what was captured
print(f" based on the retrieved context"\
f":\n\n\t {best_context}: \n")based on the retrieved context:
Prometheus (tree) / In a clonal organism, however, the individual clonal stems are not nearly so old, and no part of the organism is particularly old at any given time. Until 2012, Prometheus was thus the oldest "non-clonal" organism yet discovered, with its innermost, extant rings exceeding 4862 years of age. In the 1950s dendrochronologists were making active efforts to find the oldest living tree species in order to use the analysis of the rings for various research purposes, such as the evaluation of former climates, the dating of archaeological ruins, and addressing the basic scientific question of maximum potential lifespan. Bristlecone pines // what is the name of the oldest tree on earth?print(f" rag-sequence-nq answers '{query}'"\
f" with '{generated_string(0)}'")We can also print the response by calling generated_string variable. The rag-nq sequence answers the question “what is the name of the oldest tree on Earth?” with “Prometheus”.
What can you do with RAG?
Over the past year and a half, there has been a veritable explosion of master's degrees and master's tools. The basic BART model used at Lewis et al. In the past, the RAG model had only 400 million parameters, a far cry from the current generation of PL models, which typically start in the billion-parameter range for “lite” variants. Furthermore, many models being trained, fused, and tuned today are multimodal, combining text inputs and outputs with images or other tokenized data sources. Combining RAG with other tools can yield complex capabilities, but the underlying models will not be immune to the common shortcomings of PL models. The flattery, hallucination, and reliability issues of PL models still exist and are at risk of growing as their use grows.
The most obvious applications of RAG are variations of conversational semantic search, but might also include incorporating multimodal input or generating images as part of the output. For example, RAG in domain-aware LLMs might generate software documentation that can be chatted with. Or RAG could be used to keep interactive notes on a literature review for a research project or thesis.
By incorporating a “chain of thought” reasoning capability, you could take a more active approach to empowering your models to query the RAG system and assemble more complex lines of inquiry or reasoning.
It's also very important to note that RAG doesn't solve the most common LLM problems (hallucination, flattery, etc.) and only serves as a means to alleviate or guide your LLM towards a more specific answer. The endpoints that ultimately matter are specific to your use case, the information you feed into your model, and how the model fits.
Kevin Vu manages Exxact Corp Blog and works with many of its talented authors who write about different aspects of deep learning.






{kind=link}