
Introducción
En la segunda parte de nuestra serie sobre la creación de una aplicación RAG en una Raspberry Pi, ampliaremos las bases que establecimos en la primera parte, donde creamos y probamos el flujo de trabajo principal. En la primera parte, creamos el flujo de trabajo principal y lo probamos para asegurarnos de que todo funcionara como se esperaba. Ahora, vamos a llevar las cosas un paso más allá creando una aplicación FastAPI para servir a nuestro flujo de trabajo RAG y creando una aplicación Reflex para brindarles a los usuarios una forma sencilla e interactiva de acceder a ella. Esta parte lo guiará a través de la configuración del back-end FastAPI, el diseño del front-end con Reflex y la puesta en funcionamiento de todo en su Raspberry Pi. Al final, tendrá una aplicación completa y funcional que está lista para su uso en el mundo real.
Objetivos de aprendizaje
- Configure un back-end FastAPI para integrarlo con el pipeline RAG existente y procesar consultas de manera eficiente.
- Diseñe una interfaz fácil de usar utilizando Reflex para interactuar con el back-end FastAPI y el pipeline RAG.
- Cree y pruebe puntos finales de API para realizar consultas e ingerir documentos, lo que garantiza un funcionamiento fluido con FastAPI.
- Implemente y pruebe la aplicación completa en una Raspberry Pi, garantizando que los componentes front-end y back-end funcionen sin problemas.
- Comprenda la integración entre FastAPI y Reflex para una experiencia de aplicación RAG cohesiva.
- Implementar y solucionar problemas de componentes FastAPI y Reflex para proporcionar una aplicación RAG completamente operativa en una Raspberry Pi.
Si te perdiste la edición anterior, asegúrate de verla aquí: Hospedaje automático de aplicaciones RAG en dispositivos Edge con Langchain y Ollama (parte I).
Este artículo fue publicado como parte de la Blogatón sobre ciencia de datos.
Creación de un entorno Python
Antes de comenzar a crear la aplicación, debemos configurar el entorno. Cree un entorno e instale las siguientes dependencias:
deeplake
boto3==1.34.144
botocore==1.34.144
fastapi==0.110.3
gunicorn==22.0.0
httpx==0.27.0
huggingface-hub==0.23.4
langchain==0.2.6
langchain-community==0.2.6
langchain-core==0.2.11
langchain-experimental==0.0.62
langchain-text-splitters==0.2.2
langsmith==0.1.83
marshmallow==3.21.3
numpy==1.26.4
pandas==2.2.2
pydantic==2.8.2
pydantic_core==2.20.1
PyMuPDF==1.24.7
PyMuPDFb==1.24.6
python-dotenv==1.0.1
pytz==2024.1
PyYAML==6.0.1
reflex==0.5.6
requests==2.32.3
reflex==0.5.6
reflex-hosting-cli==0.1.13Una vez instalados los paquetes necesarios, necesitamos tener los modelos necesarios presentes en el dispositivo. Para ello, utilizaremos Ollama. Siga los pasos de la Parte 1 de este artículo para descargar tanto el lenguaje como los modelos de incrustación. Por último, cree dos directorios para las aplicaciones de back-end y front-end.
Una vez que se extraen los modelos mediante Ollama, estamos listos para construir la aplicación final.
Desarrollo del back-end con FastAPI
En la Parte 1 de este artículo, hemos creado el pipeline de RAG con los módulos Ingestion y QnA. Hemos probado ambos pipelines usando algunos documentos y funcionaron perfectamente. Ahora necesitamos encapsular el pipeline con FastAPI para crear una API consumible. Esto nos ayudará a integrarlo con cualquier aplicación front-end como Streamlit, Chainlit, Gradio, Reflex, React, Angular, etc. Comencemos por crear una estructura para la aplicación. Seguir la estructura es completamente opcional, pero asegúrate de verificar las importaciones de dependencias si sigues una estructura diferente para crear la aplicación.
A continuación se muestra la estructura de árbol que seguiremos:
backend
├── app.py
├── requirements.txt
└── src
├── config.py
├── doc_loader
│ ├── base_loader.py
│ ├── __init__.py
│ └── pdf_loader.py
├── ingestion.py
├── __init__.py
└── qna.pyComencemos con config.py. Este archivo contendrá todas las opciones configurables para la aplicación, como la URL de Ollama, el nombre de LLM y el nombre del modelo de incrustaciones. A continuación, se muestra un ejemplo:
LANGUAGE_MODEL_NAME = "phi3"
EMBEDDINGS_MODEL_NAME = "nomic-embed-text"
OLLAMA_URL = "http://localhost:11434"El archivo base_loader.py contiene la clase de cargador de documentos principal que será heredada por el cargador de documentos secundario. En esta aplicación, solo trabajamos con archivos PDF, por lo que se creará una clase Child PDFLoader.
creado que heredará la clase BaseLoader.
A continuación se muestran los contenidos de base_loader.py y pdf_loader.py:
# base_loader.py
from abc import ABC, abstractmethod
class BaseLoader(ABC):
def __init__(self, file_path: str) -> None:
self.file_path = file_path
@abstractmethod
async def load_document(self):
pass
# pdf_loader.py
import os
from .base_loader import BaseLoader
from langchain.schema import Document
from langchain.document_loaders.pdf import PyMuPDFLoader
from langchain.text_splitter import CharacterTextSplitter
class PDFLoader(BaseLoader):
def __init__(self, file_path: str) -> None:
super().__init__(file_path)
async def load_document(self):
self.file_name = os.path.basename(self.file_path)
loader = PyMuPDFLoader(file_path=self.file_path)
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=200,
)
pages = await loader.aload()
total_pages = len(pages)
chunks = ()
for idx, page in enumerate(pages):
chunks.append(
Document(
page_content=page.page_content,
metadata=dict(
{
"file_name": self.file_name,
"page_no": str(idx + 1),
"total_pages": str(total_pages),
}
),
)
)
final_chunks = text_splitter.split_documents(chunks)
return final_chunksHemos discutido el funcionamiento de pdf_loader en la Parte 1 del artículo.
A continuación, construyamos la clase Ingestión. Es la misma que construimos en la Parte 1 de este artículo.
Código para la clase de ingestión
import os
import config as cfg
from pinecone import Pinecone
from langchain.vectorstores.deeplake import DeepLake
from langchain.embeddings.ollama import OllamaEmbeddings
from .doc_loader import PDFLoader
class Ingestion:
"""Document Ingestion pipeline."""
def __init__(self):
try:
self.embeddings = OllamaEmbeddings(
model=cfg.EMBEDDINGS_MODEL_NAME,
base_url=cfg.OLLAMA_URL,
show_progress=True,
)
self.vector_store = DeepLake(
dataset_path="data/text_vectorstore",
embedding=self.embeddings,
num_workers=4,
verbose=False,
)
except Exception as e:
raise RuntimeError(f"Failed to initialize Ingestion system. ERROR: {e}")
async def create_and_add_embeddings(
self,
file: str,
):
try:
loader = PDFLoader(
file_path=file,
)
chunks = await loader.load_document()
size = await self.vector_store.aadd_documents(documents=chunks)
return len(size)
except (ValueError, RuntimeError, KeyError, TypeError) as e:
raise Exception(f"ERROR: {e}")Ahora que hemos configurado la clase Ingestión, continuaremos con la creación de la clase QnA. Esta también es la misma que creamos en la Parte 1 de este artículo.
Código para la clase de preguntas y respuestas
import os
import config as cfg
from pinecone import Pinecone
from langchain.vectorstores.deeplake import DeepLake
from langchain.embeddings.ollama import OllamaEmbeddings
from langchain_community.llms.ollama import Ollama
from .doc_loader import PDFLoader
class QnA:
"""Document Ingestion pipeline."""
def __init__(self):
try:
self.embeddings = OllamaEmbeddings(
model=cfg.EMBEDDINGS_MODEL_NAME,
base_url=cfg.OLLAMA_URL,
show_progress=True,
)
self.model = Ollama(
model=cfg.LANGUAGE_MODEL_NAME,
base_url=cfg.OLLAMA_URL,
verbose=True,
temperature=0.2,
)
self.vector_store = DeepLake(
dataset_path="data/text_vectorstore",
embedding=self.embeddings,
num_workers=4,
verbose=False,
)
self.retriever = self.vector_store.as_retriever(
search_type="similarity",
search_kwargs={
"k": 10,
},
)
except Exception as e:
raise RuntimeError(f"Failed to initialize Ingestion system. ERROR: {e}")
def create_rag_chain(self):
try:
system_prompt = """\n\nContext: {context}"
"""
prompt = ChatPromptTemplate.from_messages(
(
("system", system_prompt),
("human", "{input}"),
)
)
question_answer_chain = create_stuff_documents_chain(self.model, prompt)
rag_chain = create_retrieval_chain(self.retriever, question_answer_chain)
return rag_chain
except Exception as e:
raise RuntimeError(f"Failed to create retrieval chain. ERROR: {e}")Con esto hemos terminado de crear las funcionalidades del código de la aplicación RAG. Ahora vamos a envolver la aplicación con FastAPI.
Código para la aplicación FastAPI
import sys
import os
import uvicorn
from src import QnA, Ingestion
from fastapi import FastAPI, Request, File, UploadFile
from fastapi.responses import StreamingResponse
app = FastAPI()
ingestion = Ingestion()
chatbot = QnA()
rag_chain = chatbot.create_rag_chain()
@app.get("https://www.analyticsvidhya.com/")
def hello():
return {"message": "API Running in server 8089"}
@app.post("/query")
async def ask_query(request: Request):
data = await request.json()
question = data.get("question")
async def event_generator():
for chunk in rag_chain.pick("answer").stream({"input": question}):
yield chunk
return StreamingResponse(event_generator(), media_type="text/plain")
@app.post("/ingest")
async def ingest_document(file: UploadFile = File(...)):
try:
os.makedirs("files", exist_ok=True)
file_location = f"files/{file.filename}"
with open(file_location, "wb+") as file_object:
file_object.write(file.file.read())
size = await ingestion.create_and_add_embeddings(file=file_location)
return {"message": f"File ingested! Document count: {size}"}
except Exception as e:
return {"message": f"An error occured: {e}"}
if __name__ == "__main__":
try:
uvicorn.run(app, host="0.0.0.0", port=8089)
except KeyboardInterrupt as e:
print("App stopped!")Analicemos la aplicación por cada punto final:
- Primero inicializamos la aplicación FastAPI, los objetos Ingestion y QnA. Luego creamos una cadena RAG usando el método create_rag_chain de la clase QnA.
- Nuestro primer punto final es un método GET simple. Esto nos ayudará a saber si la aplicación está en buen estado o no. Piense en ello como un punto final de “Hola mundo”.
- El segundo es el punto final de la consulta. Este es un método POST y se utilizará para ejecutar la cadena. Toma un parámetro de solicitud, del cual extraemos la consulta del usuario. Luego, creamos un método asincrónico que actúa como un contenedor asincrónico alrededor de la llamada a la función chain.stream. Necesitamos hacer esto para permitir que FastAPI maneje la llamada a la función de transmisión de LLM, para obtener una experiencia similar a ChatGPT en la interfaz de chat. Luego, envolvemos el método asincrónico con la clase StreamingResponse y lo devolvemos.
- El tercer punto final es el punto final de ingestión. También es un método POST que toma el archivo completo como bytes como entrada. Almacenamos este archivo en el directorio local y luego lo ingerimos utilizando el método create_and_add_embeddings de la clase Ingestión.
Por último, ejecutamos la aplicación con el paquete uvicorn, utilizando el host y el puerto. Para probar la aplicación, simplemente ejecute la aplicación con el siguiente comando:
python app.py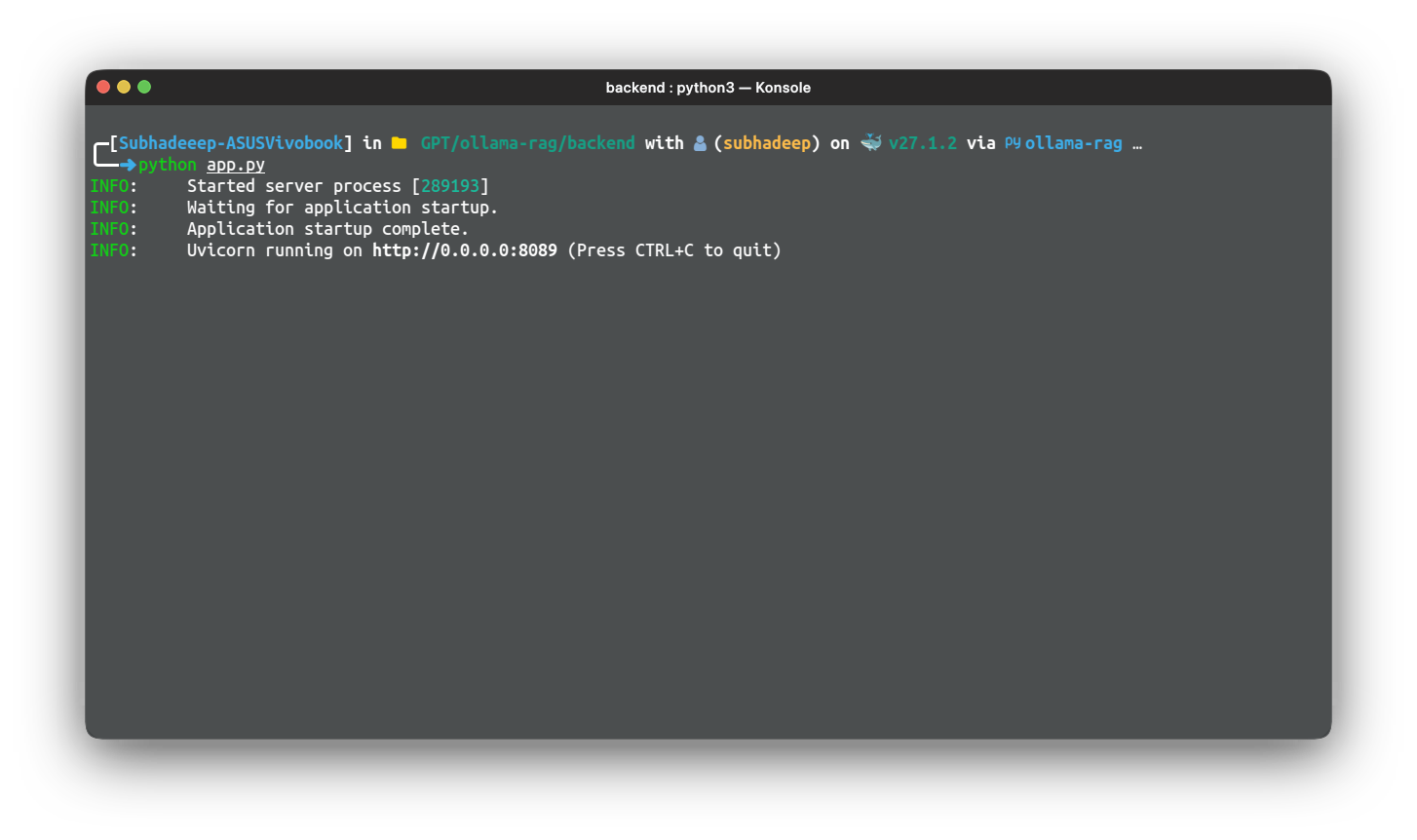
Utilice un IDE de prueba de API como Postman, Insomnia o Bruno para probar la aplicación. También puede utilizar la extensión Thunder Client para hacer lo mismo.
Prueba del punto final de ingestión:
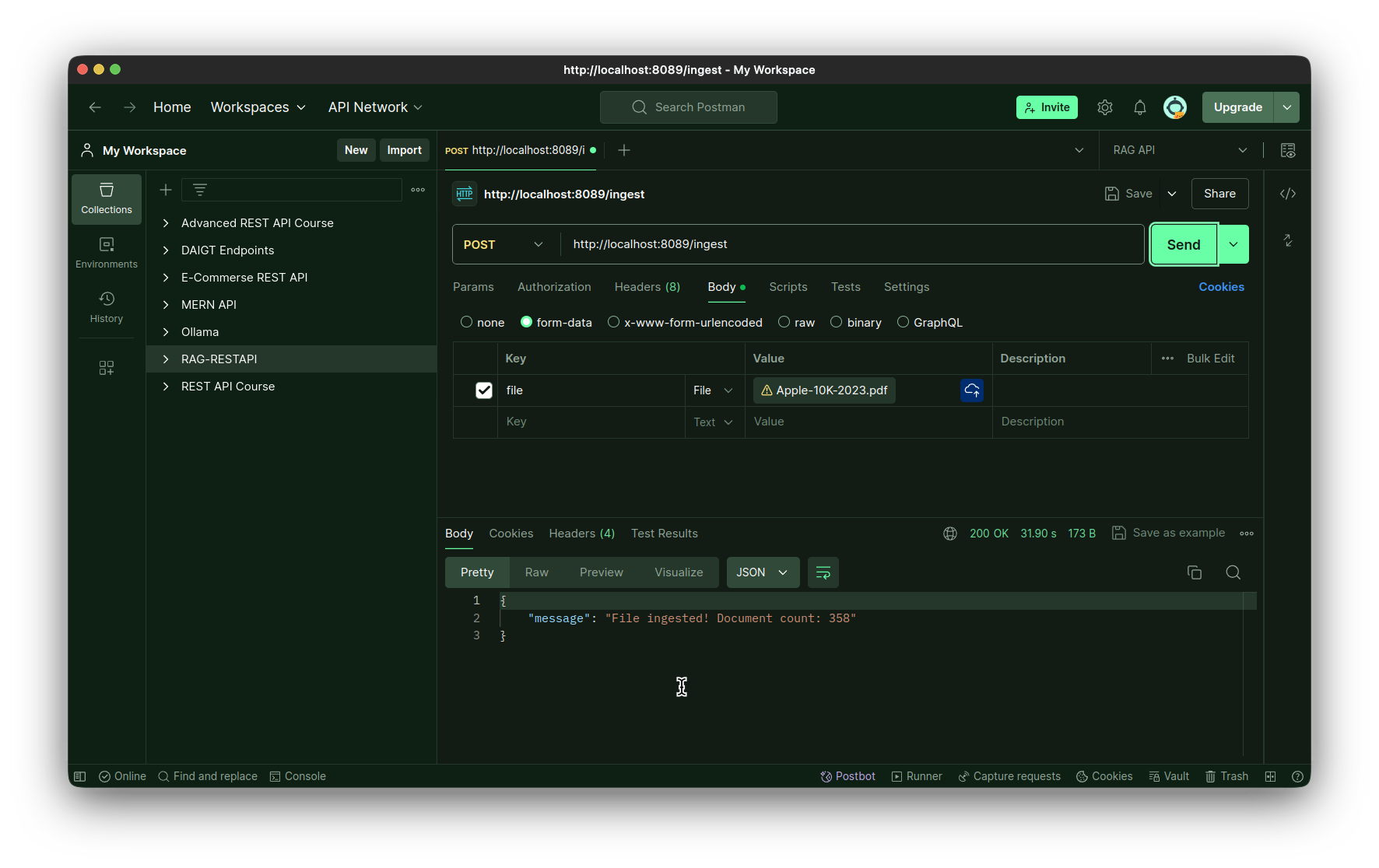
Probando el punto final de la consulta:
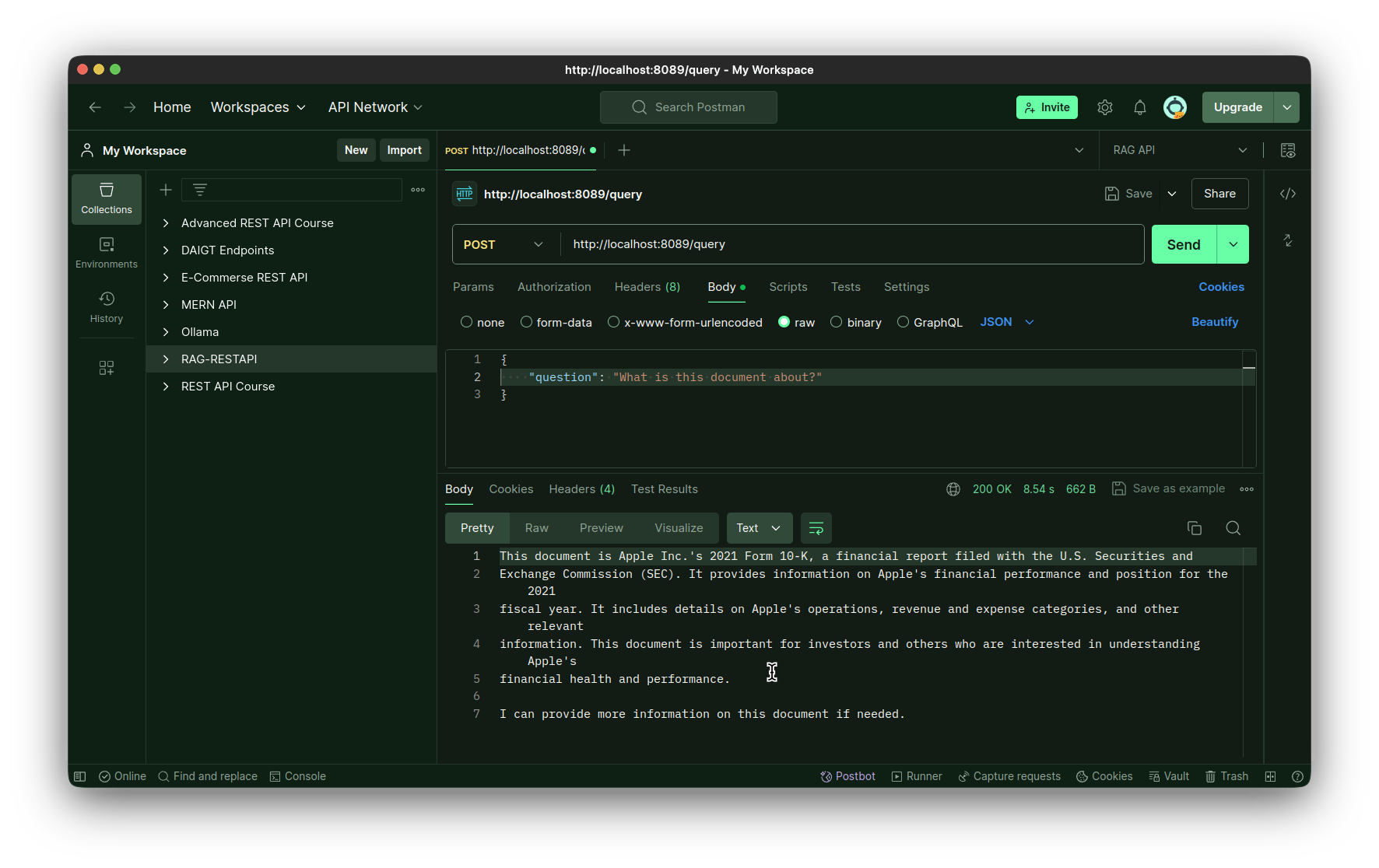
Diseño del front-end con Reflex
Hemos creado con éxito una aplicación FastAPI para el backend de nuestra aplicación RAG. Es hora de construir nuestro frontend. Puede elegir cualquier biblioteca de frontend para esto, pero para este artículo en particular construiremos el frontend usando Reflex. Reflex es una biblioteca de frontend solo para Python, creada para construir aplicaciones web, usando únicamente Python. Nos proporciona plantillas para aplicaciones comunes como calculadora, generación de imágenes y chatbot. Usaremos la plantilla de aplicación de chatbot como punto de partida para nuestra interfaz de usuario. Nuestra aplicación final tendrá la siguiente estructura, así que la dejaremos aquí como referencia.
Directorio de interfaz
Tendremos un directorio frontend para esto:
frontend
├── assets
│ └── favicon.ico
├── docs
│ └── demo.gif
├── chat
│ ├── components
│ │ ├── chat.py
│ │ ├── file_upload.py
│ │ ├── __init__.py
│ │ ├── loading_icon.py
│ │ ├── modal.py
│ │ └── navbar.py
│ ├── __init__.py
│ ├── chat.py
│ └── state.py
├── requirements.txt
├── rxconfig.py
└── uploaded_filesPasos para la aplicación final
Siga los pasos para preparar la conexión a tierra para la aplicación final.
Paso 1: Clonar el repositorio de plantillas de chat en el directorio del frontend
git clone https://github.com/reflex-dev/reflex-chat.git .Paso 2: Ejecute el siguiente comando para inicializar el directorio como una aplicación refleja
reflex init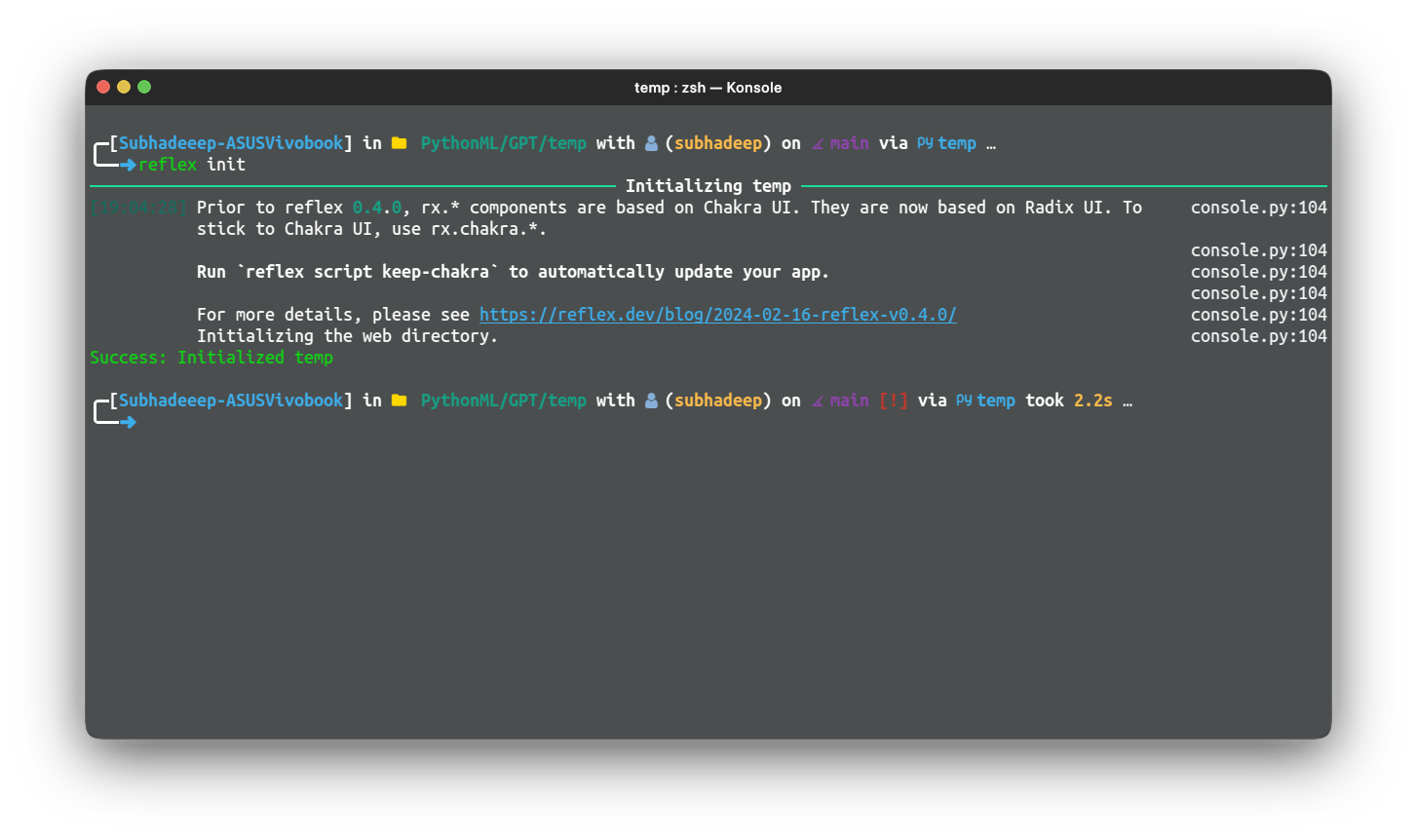
Esto configurará la aplicación Reflex y estará lista para ejecutarse y desarrollarse.
Paso 3: Pruebe la aplicación, use el siguiente comando desde dentro del directorio frontend
reflex run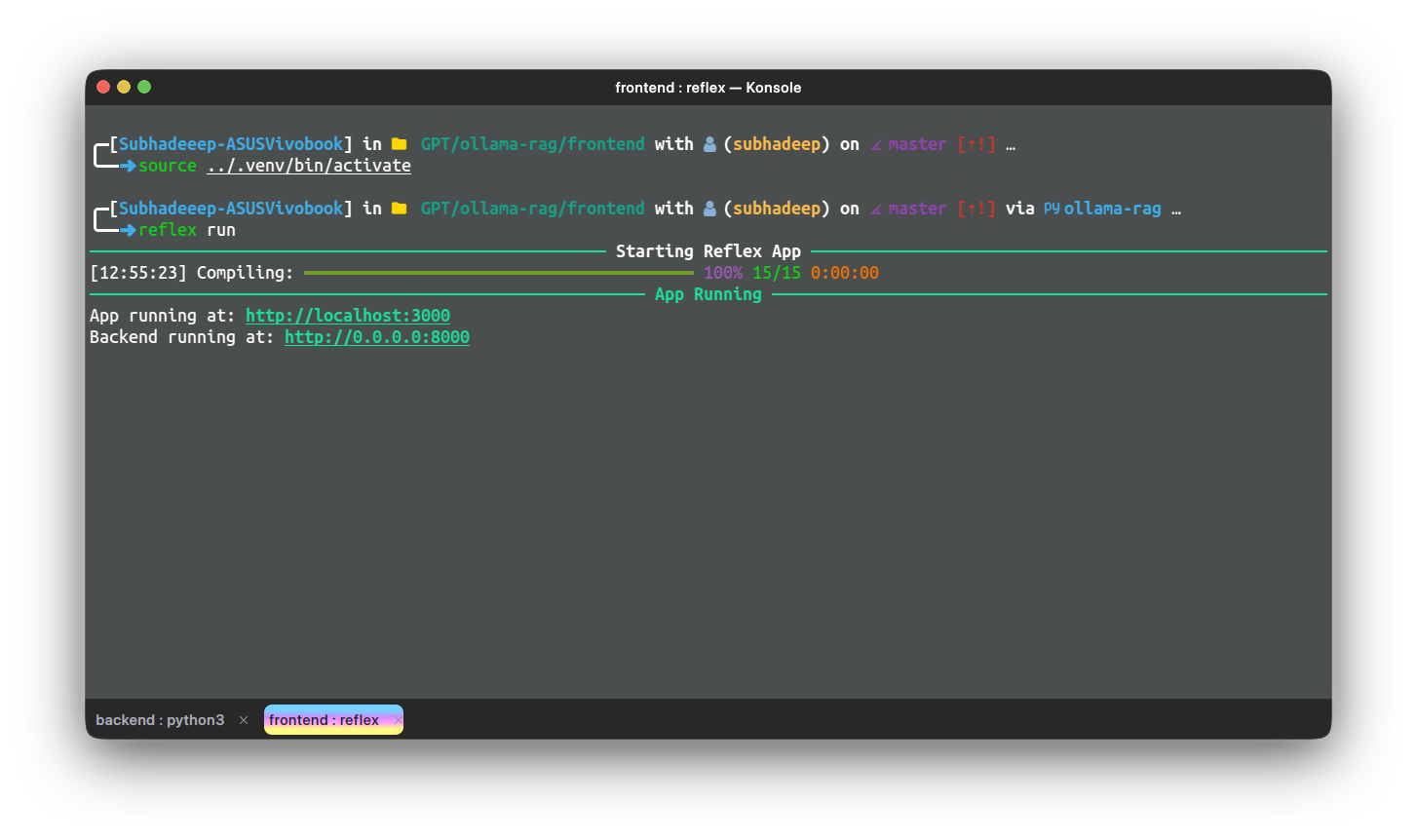
Comencemos a modificar los componentes. Primero, modifiquemos el archivo chat.py.
A continuación se muestra el código para el mismo:
import reflex as rx
from reflex_demo.components import loading_icon
from reflex_demo.state import QA, State
message_style = dict(
display="inline-block",
padding="0 10px",
border_radius="8px",
max_width=("30em", "30em", "50em", "50em", "50em", "50em"),
)
def message(qa: QA) -> rx.Component:
"""A single question/answer message.
Args:
qa: The question/answer pair.
Returns:
A component displaying the question/answer pair.
"""
return rx.box(
rx.box(
rx.markdown(
qa.question,
background_color=rx.color("mauve", 4),
color=rx.color("mauve", 12),
**message_style,
),
text_align="right",
margin_top="1em",
),
rx.box(
rx.markdown(
qa.answer,
background_color=rx.color("accent", 4),
color=rx.color("accent", 12),
**message_style,
),
text_align="left",
padding_top="1em",
),
width="100%",
)
def chat() -> rx.Component:
"""List all the messages in a single conversation."""
return rx.vstack(
rx.box(rx.foreach(State.chats(State.current_chat), message), width="100%"),
py="8",
flex="1",
width="100%",
max_width="50em",
padding_x="4px",
align_self="center",
overflow="hidden",
padding_bottom="5em",
)
def action_bar() -> rx.Component:
"""The action bar to send a new message."""
return rx.center(
rx.vstack(
rx.chakra.form(
rx.chakra.form_control(
rx.hstack(
rx.input(
rx.input.slot(
rx.tooltip(
rx.icon("info", size=18),
content="Enter a question to get a response.",
)
),
placeholder="Type something...",
id="question",
width=("15em", "20em", "45em", "50em", "50em", "50em"),
),
rx.button(
rx.cond(
State.processing,
loading_icon(height="1em"),
rx.text("Send", font_family="Ubuntu"),
),
type="submit",
),
align_items="center",
),
is_disabled=State.processing,
),
on_submit=State.process_question,
reset_on_submit=True,
),
rx.text(
"ReflexGPT may return factually incorrect or misleading responses. Use discretion.",
text_align="center",
font_size=".75em",
color=rx.color("mauve", 10),
font_family="Ubuntu",
),
rx.logo(margin_top="-1em", margin_bottom="-1em"),
align_items="center",
),
position="sticky",
bottom="0",
left="0",
padding_y="16px",
backdrop_filter="auto",
backdrop_blur="lg",
border_top=f"1px solid {rx.color('mauve', 3)}",
background_color=rx.color("mauve", 2),
align_items="stretch",
width="100%",
)Los cambios son mínimos respecto a los presentes de forma nativa en la plantilla.
A continuación, editaremos la aplicación chat.py. Este es el componente principal del chat.
Código para el componente de chat principal
A continuación se muestra el código:
import reflex as rx
from reflex_demo.components import chat, navbar, upload_form
from reflex_demo.state import State
@rx.page(route="/chat", title="RAG Chatbot")
def chat_interface() -> rx.Component:
return rx.chakra.vstack(
navbar(),
chat.chat(),
chat.action_bar(),
background_color=rx.color("mauve", 1),
color=rx.color("mauve", 12),
min_height="100vh",
align_items="stretch",
spacing="0",
)
@rx.page(route="https://www.analyticsvidhya.com/", title="RAG Chatbot")
def index() -> rx.Component:
return rx.chakra.vstack(
navbar(),
upload_form(),
background_color=rx.color("mauve", 1),
color=rx.color("mauve", 12),
min_height="100vh",
align_items="stretch",
spacing="0",
)
# Add state and page to the app.
app = rx.App(
theme=rx.theme(
appearance="dark",
accent_color="jade",
),
stylesheets=("https://fonts.googleapis.com/css2?family=Ubuntu&display=swap"),
style={
"font_family": "Ubuntu",
},
)
app.add_page(index)
app.add_page(chat_interface)Este es el código de la interfaz de chat. Solo hemos agregado la familia de fuentes a la configuración de la aplicación, el resto del código es el mismo.
A continuación, editemos el archivo state.py. Aquí es donde el frontend llamará a los puntos finales de la API para obtener una respuesta.
Edición del archivo state.py
import requests
import reflex as rx
class QA(rx.Base):
question: str
answer: str
DEFAULT_CHATS = {
"Intros": (),
}
class State(rx.State):
chats: dict(str, list(QA)) = DEFAULT_CHATS
current_chat = "Intros"
url: str = "http://localhost:8089/query"
question: str
processing: bool = False
new_chat_name: str = ""
def create_chat(self):
"""Create a new chat."""
# Add the new chat to the list of chats.
self.current_chat = self.new_chat_name
self.chats(self.new_chat_name) = ()
def delete_chat(self):
"""Delete the current chat."""
del self.chats(self.current_chat)
if len(self.chats) == 0:
self.chats = DEFAULT_CHATS
self.current_chat = list(self.chats.keys())(0)
def set_chat(self, chat_name: str):
"""Set the name of the current chat.
Args:
chat_name: The name of the chat.
"""
self.current_chat = chat_name
@rx.var
def chat_titles(self) -> list(str):
"""Get the list of chat titles.
Returns:
The list of chat names.
"""
return list(self.chats.keys())
async def process_question(self, form_data: dict(str, str)):
# Get the question from the form
question = form_data("question")
# Check if the question is empty
if question == "":
return
model = self.openai_process_question
async for value in model(question):
yield value
async def openai_process_question(self, question: str):
"""Get the response from the API.
Args:
form_data: A dict with the current question.
"""
# Add the question to the list of questions.
qa = QA(question=question, answer="")
self.chats(self.current_chat).append(qa)
payload = {"question": question}
# Clear the input and start the processing.
self.processing = True
yield
response = requests.post(self.url, json=payload, stream=True)
# Stream the results, yielding after every word.
for answer_text in response.iter_content(chunk_size=512):
# Ensure answer_text is not None before concatenation
answer_text = answer_text.decode()
if answer_text is not None:
self.chats(self.current_chat)(-1).answer += answer_text
else:
answer_text = ""
self.chats(self.current_chat)(-1).answer += answer_text
self.chats = self.chats
yield
# Toggle the processing flag.
self.processing = FalseEn este archivo, hemos definido la URL para el punto final de la consulta. También hemos modificado el método openai_process_question para enviar una solicitud POST al punto final de la consulta y obtener la transmisión
respuesta, que se mostrará en la interfaz de chat.
Escritura del contenido del archivo file_upload.py
Por último, escribamos el contenido del archivo file_upload.py. Este componente se mostrará al principio y nos permitirá cargar el archivo para su ingesta.
import reflex as rx
import os
import time
import requests
class UploadExample(rx.State):
uploading: bool = False
ingesting: bool = False
progress: int = 0
total_bytes: int = 0
ingestion_url = "http://127.0.0.1:8089/ingest"
async def handle_upload(self, files: list(rx.UploadFile)):
self.ingesting = True
yield
for file in files:
file_bytes = await file.read()
file_name = file.filename
files = {
"file": (os.path.basename(file_name), file_bytes, "multipart/form-data")
}
response = requests.post(self.ingestion_url, files=files)
self.ingesting = False
yield
if response.status_code == 200:
# yield rx.redirect("/chat")
self.show_redirect_popup()
def handle_upload_progress(self, progress: dict):
self.uploading = True
self.progress = round(progress("progress") * 100)
if self.progress >= 100:
self.uploading = False
def cancel_upload(self):
self.uploading = False
return rx.cancel_upload("upload3")
def upload_form():
return rx.vstack(
rx.upload(
rx.flex(
rx.text(
"Drag and drop file here or click to select file",
font_family="Ubuntu",
),
rx.icon("upload", size=30),
direction="column",
align="center",
),
id="upload3",
border="1px solid rgb(233, 233,233, 0.4)",
margin="5em 0 10px 0",
background_color="rgb(107,99,246)",
border_radius="8px",
padding="1em",
),
rx.vstack(rx.foreach(rx.selected_files("upload3"), rx.text)),
rx.cond(
~UploadExample.ingesting,
rx.button(
"Upload",
on_click=UploadExample.handle_upload(
rx.upload_files(
upload_id="upload3",
on_upload_progress=UploadExample.handle_upload_progress,
),
),
),
rx.flex(
rx.spinner(size="3", loading=UploadExample.ingesting),
rx.button(
"Cancel",
on_click=UploadExample.cancel_upload,
),
align="center",
spacing="3",
),
),
rx.alert_dialog.root(
rx.alert_dialog.trigger(
rx.button("Continue to Chat", color_scheme="green"),
),
rx.alert_dialog.content(
rx.alert_dialog.title("Redirect to Chat Interface?"),
rx.alert_dialog.description(
"You will be redirected to the Chat Interface.",
size="2",
),
rx.flex(
rx.alert_dialog.cancel(
rx.button(
"Cancel",
variant="soft",
color_scheme="gray",
),
),
rx.alert_dialog.action(
rx.button(
"Continue",
color_scheme="green",
variant="solid",
on_click=rx.redirect("/chat"),
),
),
spacing="3",
margin_top="16px",
justify="end",
),
style={"max_width": 450},
),
),
align="center",
)Este componente nos permitirá cargar un archivo e ingerirlo en la tienda de vectores. Utiliza el punto final de ingesta de nuestra aplicación FastAPI para cargar e ingerir el archivo. Después de la ingesta, el usuario puede simplemente mover
a la interfaz de chat para realizar consultas.
Con esto hemos terminado de construir el front-end de nuestra aplicación. Ahora tendremos que probar la aplicación usando algún documento.
Pruebas e implementación
Ahora, probemos la aplicación en algunos manuales o documentos. Para usar la aplicación, necesitamos ejecutar la aplicación back-end y la aplicación reflex por separado. Ejecute la aplicación back-end desde su directorio usando el comando
siguiente comando:
python app.pyEspere a que FastAPI comience a ejecutarse. Luego, en otra instancia de terminal, ejecute la aplicación front-end con el siguiente comando:
reflex runUna vez que las aplicaciones estén en funcionamiento, acceda a siguiente URL Para acceder a la aplicación Reflex, inicialmente nos encontraremos en la página de Carga de archivos. Subimos un archivo y pulsamos el botón de carga.
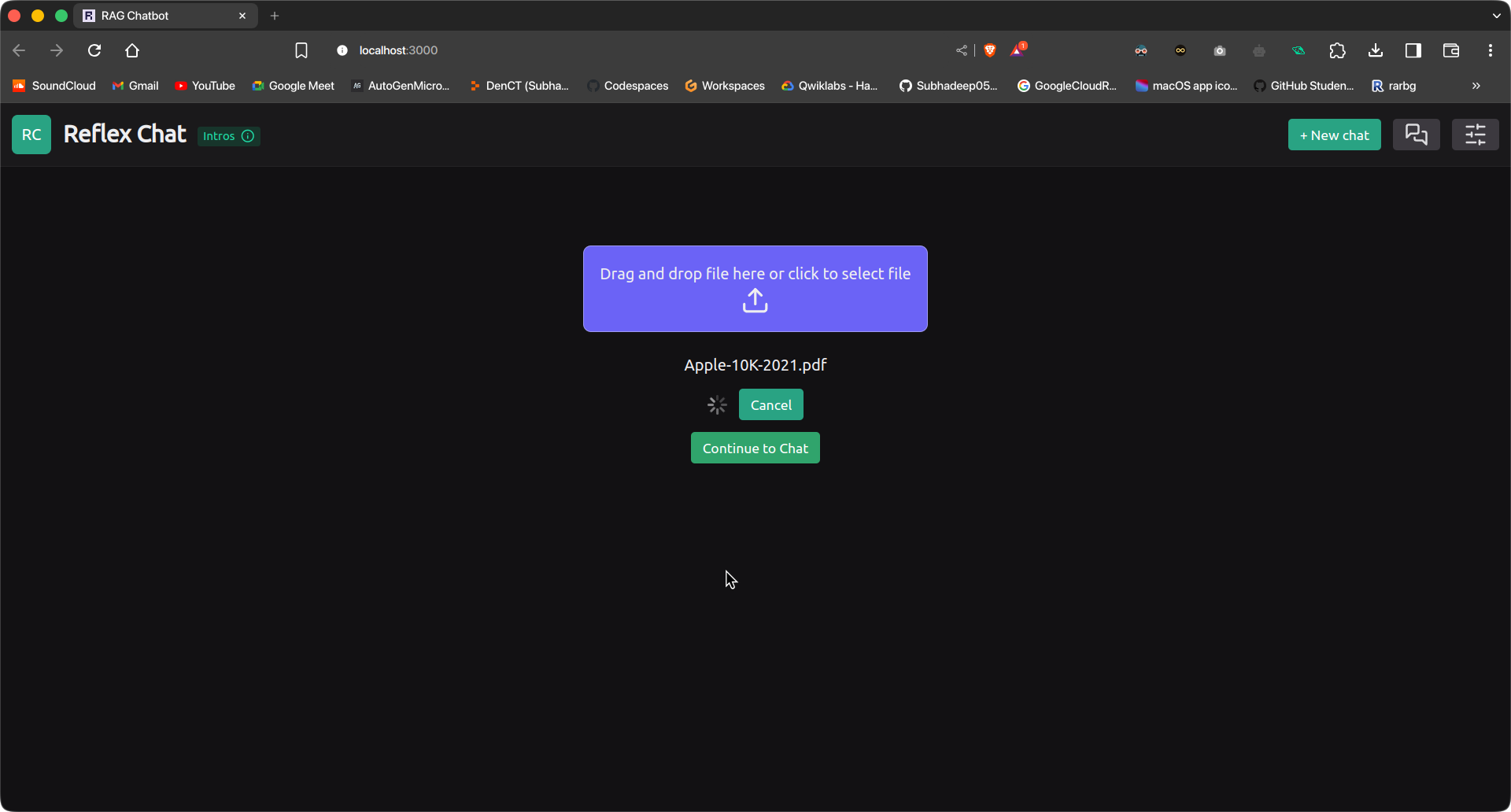
El archivo se cargará y se procesará. Esto tardará un tiempo dependiendo del tamaño del documento y
Las especificaciones del dispositivo. Una vez hecho esto, haz clic en el botón “Continuar con el chat” para pasar a la interfaz de chat. Escribe tu consulta y presiona Enviar.
Conclusión
En esta serie de dos partes, ya ha creado una aplicación RAG completa y funcional en una Raspberry Pi, desde la creación de la canalización principal hasta su integración con un back-end FastAPI y el desarrollo de un front-end basado en Reflex. Con estas herramientas, su canalización RAG es accesible e interactiva, y proporciona procesamiento de consultas en tiempo real a través de una interfaz web fácil de usar. Al dominar estos pasos, ha adquirido una valiosa experiencia en la creación e implementación de aplicaciones de extremo a extremo en una plataforma compacta y eficiente. Esta configuración abre la puerta a innumerables posibilidades para implementar aplicaciones impulsadas por IA en dispositivos con recursos limitados como Raspberry Pi, lo que hace que la tecnología de vanguardia sea más accesible y práctica para el uso diario.
Puntos clave
- Se proporciona una guía detallada sobre cómo configurar el entorno de desarrollo, incluida la instalación de las dependencias y modelos necesarios mediante Ollama, garantizando que la aplicación esté lista para la compilación final.
- El artículo explica cómo envolver el pipeline RAG en una aplicación FastAPI, incluida la configuración de puntos finales para consultar el modelo e ingerir documentos, haciendo que el pipeline sea accesible a través de una API web.
- El front-end de la aplicación RAG se creó con Reflex, una biblioteca front-end exclusiva de Python. El artículo demuestra cómo modificar la plantilla de la aplicación de chat para crear una interfaz fácil de usar para interactuar con el flujo de trabajo de RAG.
- El artículo guía sobre la integración del backend FastAPI con el frontend Reflex y la implementación de la aplicación completa en una Raspberry Pi, garantizando un funcionamiento perfecto y accesibilidad del usuario.
- Se proporcionan pasos prácticos para probar los puntos finales de ingesta y consulta utilizando herramientas como Postman o Thunder Client, junto con la ejecución y prueba del front-end de Reflex para garantizar que toda la aplicación funcione como se espera.
Preguntas frecuentes
A. Existe una plataforma llamada Tailscale que permite que sus dispositivos se conecten a una red segura y privada, a la que solo usted puede acceder. Puede agregar su Raspberry Pi y otros dispositivos a los dispositivos Tailscale y conectarse a la VPN para acceder a sus aplicaciones desde cualquier lugar del mundo.
A. Esa es la limitación que se debe a las bajas especificaciones de hardware de Raspberry Pi. El artículo es solo un tutorial preliminar sobre cómo comenzar a crear una aplicación RAG con Raspberry Pi y Ollama.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.





