 NEWSLETTER
NEWSLETTER
Multi-agent reinforcement learning (MARL) is a field focused on developing systems in which multiple agents cooperate to solve tasks that exceed the capabilities of individual agents. This area has gained significant attention due to its relevance in autonomous vehicles, robotics, and complex gaming environments. The goal is to enable agents to work together efficiently, adapt to dynamic environments, and solve complex tasks that require coordination and collaboration. To do so, researchers develop models that facilitate interaction between agents to ensure effective problem solving. This branch of artificial intelligence has grown rapidly due to its potential for real-world applications, requiring constant improvements in agent cooperation and decision-making algorithms.
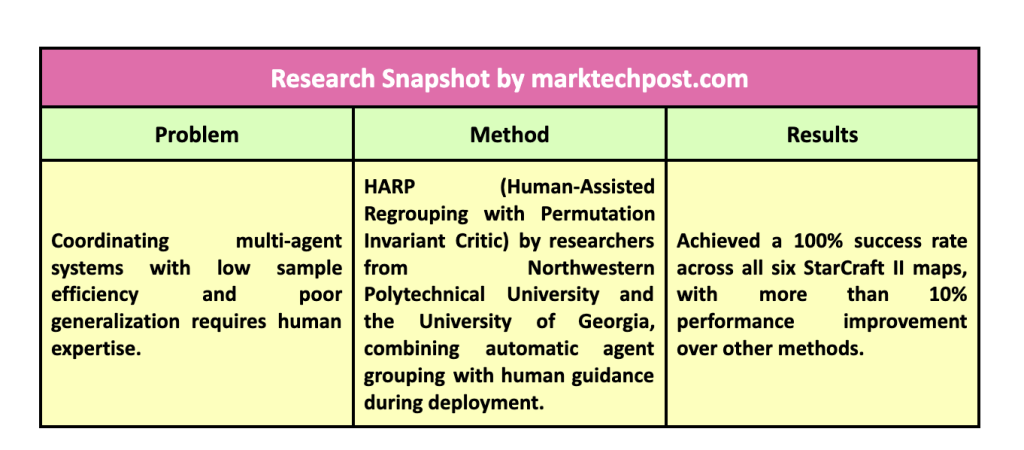
One of the main challenges of MARL is that it is notoriously difficult to coordinate multiple agents, particularly in environments that present dynamic and complex challenges. Agents often need help with two main problems: low sampling efficiency and poor generalization. Sampling efficiency refers to the agent’s ability to learn effectively from a limited number of experiences, while generalization is its ability to apply learned behaviors to new, unseen environments. Human expertise is often needed to guide agent decision-making in complex scenarios, but it is expensive, scarce, and time-consuming. The challenge is compounded by the fact that most reinforcement learning frameworks rely heavily on human intervention during the training phase, leading to significant scalability limitations.
Several existing methods attempt to improve agent collaboration and decision-making by introducing specific frameworks and algorithms. Some methods focus on role-based groupings, such as the RODE method, which decomposes the action space into roles to create more efficient policies. Others, such as GACG, use graph-based models to represent agent interactions and optimize their cooperation. These existing methods, while useful, still leave gaps in agent adaptability and do not address the limitations of human intervention. They either rely too heavily on predefined roles or require complex mathematical modeling that limits their flexibility in real-world applications. This inefficiency underscores the need for more adaptive frameworks that require less continuous human involvement during training.
Researchers at Northwestern Polytechnic University and the University of Georgia have introduced a new framework called HARP (Human Assisted Regrouping with Permutation Invariant Criterion)This innovative approach enables agents to dynamically retrain, even during deployment, with limited human intervention. HARP is unique in that it enables non-expert human users to provide useful feedback during deployment without the need for ongoing expert-level guidance. HARP’s primary goal is to reduce the reliance on human experts during training while simultaneously enabling strategic human involvement during deployment, effectively bridging the gap between automation and human-guided refinement.
The key innovation of HARP lies in its combination of automatic clustering during the training phase and human-assisted re-clustering during deployment. During training, agents learn to autonomously form clusters, optimizing collaborative task performance. When deployed, they actively seek human assistance when needed, using a Permutation Invariant Group Critic to evaluate and refine clusters based on human suggestions. This method enables agents to better adapt to complex environments, as human input is integrated to correct or improve group dynamics when agents encounter challenges. HARP’s unique feature is that it allows non-expert humans to provide meaningful contributions as the system refines its suggestions through re-evaluation. The method dynamically adjusts cluster compositions based on Q-value evaluations and agent performance.
HARP’s performance was tested in multiple cooperative environments using six maps in the StarCraft II Multi-Agent Challenge, spanning three difficulty levels: Easy (8m, MMM), Hard (8m vs. 9m, 5m vs. 6m), and Super Hard (MMM2, Corridor). In these tests, HARP-controlled agents outperformed those guided by traditional methods, achieving a 100% success rate on all six maps. On more difficult maps, such as 5m vs. 6m, where other methods achieved success rates of only 53.1% vs. 71.2%, HARP agents showed marked improvement, achieving a 100% success rate. The method also improved agent performance by over 10% compared to other techniques that do not incorporate human assistance. The introduction of human involvement during implementation and automatic clustering during training resulted in significant improvements across different difficulty levels, demonstrating the system’s ability to adapt and respond to complex situations efficiently.
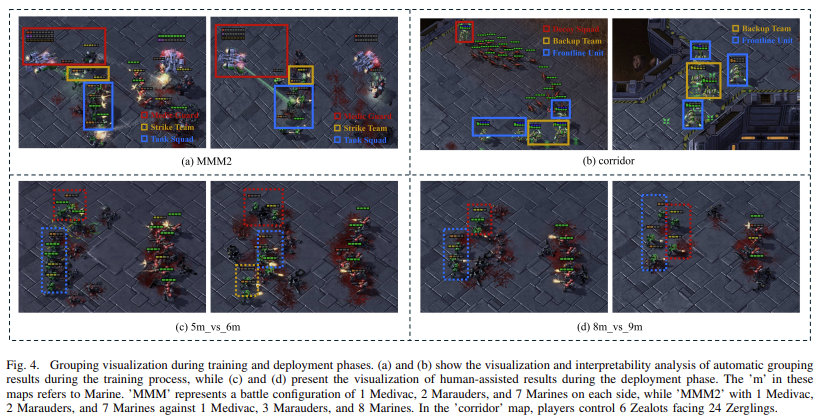
The results of HARP implementation highlight its significant impact on improving multi-agent systems. Its ability to actively seek and integrate human guidance during deployment, particularly in challenging environments, reduces the need for human expertise during training. HARP demonstrated a marked increase in success rates on challenging maps, such as MMM2 and the corridor map, where the performance of other methods faltered. On the corridor map, HARP-controlled agents achieved a 100% success rate, compared to 0% for different approaches. The flexibility of the framework allows it to dynamically adapt to environmental changes, making it a robust solution for complex multi-agent scenarios.
In conclusion, HARP offers a breakthrough in multi-agent reinforcement learning by reducing the need for continuous human involvement during training while still allowing for targeted human involvement during deployment. This system addresses the key challenges of low sample efficiency and poor generalization by allowing dynamic group adjustments based on human feedback. By significantly increasing agent performance at various difficulty levels, HARP presents a scalable and adaptable solution for multi-agent coordination. The successful application of this framework in the StarCraft II environment suggests its potential for broader use in real-world scenarios that require human-machine collaboration, such as robotics and autonomous systems.
Take a look at the PaperAll credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram Channel and LinkedIn GrAbove!. If you like our work, you will love our fact sheet..
Don't forget to join our SubReddit of over 50,000 ml
FREE ai WEBINAR: 'SAM 2 for Video: How to Optimize Your Data' (Wednesday, September 25, 4:00 am – 4:45 am EST)
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary engineer and entrepreneur, Asif is committed to harnessing the potential of ai for social good. His most recent initiative is the launch of an ai media platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easily understandable to a wide audience. The platform has over 2 million monthly views, illustrating its popularity among the public.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}