 NEWSLETTER
NEWSLETTER
Introducción
En el mundo de la IA en rápida evolución, es crucial realizar un seguimiento de los costos de API, especialmente cuando se crean aplicaciones basadas en LLM, como canalizaciones de generación aumentada de recuperación (RAG) en producción. Experimentar con diferentes LLM para obtener los mejores resultados a menudo implica realizar numerosas solicitudes de API al servidor, y cada solicitud genera un costo. Comprender y realizar un seguimiento de dónde se gasta cada dólar es vital para gestionar estos gastos de forma eficaz.
En este artículo, implementaremos la observabilidad de LLM con RAG usando solo entre 10 y 12 líneas de código. La observabilidad nos ayuda a monitorear métricas clave como la latencia, la cantidad de tokens, las indicaciones y el costo por solicitud.
Objetivos de aprendizaje
- Comprender el concepto de observabilidad de LLM y cómo ayuda a monitorear y optimizar el rendimiento y el costo de los LLM en aplicaciones.
- Explore diferentes métricas clave para rastrear y monitorear, como la utilización de tokens, la latencia, el costo por solicitud y las experimentaciones rápidas.
- Cómo construir un canal de generación aumentada de recuperación junto con observabilidad.
- Cómo utilizar BeyondLLM para evaluar más a fondo el proceso de RAG utilizando métricas de la tríada RAG, es decir, relevancia del contexto, relevancia de la respuesta y conexión a tierra.
- Ajustar sabiamente el tamaño de los fragmentos y los valores top-K para reducir costos, utilizar una cantidad eficiente de tokens y mejorar la latencia.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
¿Qué es la observabilidad del LLM?
Piense en LLM Observability tal como monitorea el rendimiento de su automóvil o realiza un seguimiento de sus gastos diarios. LLM Observability implica observar y comprender cada detalle de cómo funcionan estos modelos de IA. Le ayuda a realizar un seguimiento del uso contando el número de “tokens”, unidades de procesamiento que utiliza cada solicitud al modelo. Esto le ayuda a mantenerse dentro del presupuesto y evitar gastos inesperados.
Además, monitorea el rendimiento registrando cuánto tiempo lleva cada solicitud, asegurando que ninguna parte del proceso sea innecesariamente lenta. Proporciona información valiosa al mostrar patrones y tendencias, lo que le ayuda a identificar ineficiencias y áreas en las que podría estar gastando demasiado. LLM Observability es una de las mejores prácticas a seguir al crear aplicaciones en producción, ya que esto puede automatizar el proceso de acción para enviar alertas si algo sale mal.
¿Qué es la recuperación de generación aumentada?
La generación aumentada de recuperación (RAG) es un concepto en el que fragmentos de documentos relevantes se devuelven a un modelo de lenguaje grande (LLM) como aprendizaje en contexto (es decir, indicaciones de pocas tomas) basado en la consulta de un usuario. En pocas palabras, RAG consta de dos partes: el recuperador y el generador.
Cuando un usuario ingresa una consulta, primero se convierte en incrustaciones. Luego, el recuperador busca estas incorporaciones de consultas en una base de datos vectorial para devolver los documentos más relevantes o semánticamente similares. Estos documentos se pasan como aprendizaje en contexto al modelo generador, lo que permite al LLM generar una respuesta razonable. RAG reduce la probabilidad de sufrir alucinaciones y proporciona respuestas de dominio específico basadas en la base de conocimientos proporcionada.
La creación de una canalización RAG implica varios componentes clave: fuente de datos, divisores de texto, base de datos vectorial, modelos de incrustación y modelos de lenguaje grandes. RAG se implementa ampliamente cuando necesita conectar un modelo de lenguaje grande a una fuente de datos personalizada. Por ejemplo, si deseas crear tu propio ChatGPT para tus apuntes de clase, RAG sería la solución ideal. Este enfoque garantiza que el modelo pueda proporcionar respuestas precisas y relevantes basadas en sus datos específicos, lo que lo hace muy útil para aplicaciones personalizadas.
¿Por qué utilizar la observabilidad con RAG?
La creación de una aplicación RAG depende de diferentes casos de uso. Cada caso de uso depende de sus propias indicaciones personalizadas para el aprendizaje en contexto. Los avisos personalizados incluyen una combinación de avisos del sistema y avisos del usuario, los avisos del sistema son las reglas o instrucciones basadas en las cuales LLM debe comportarse y los avisos del usuario son los avisos aumentados para la consulta del usuario. Escribir un buen mensaje en el primer intento es un caso muy raro.
El uso de la observabilidad con la generación aumentada de recuperación (RAG) es crucial para garantizar operaciones eficientes y rentables. La observabilidad lo ayuda a monitorear y comprender cada detalle de su proceso RAG, desde el seguimiento del uso de tokens hasta la medición de la latencia, las indicaciones y los tiempos de respuesta. Al vigilar de cerca estas métricas, puede identificar y abordar ineficiencias, evitar gastos inesperados y optimizar el rendimiento de su sistema. Básicamente, la observabilidad proporciona la información necesaria para ajustar la configuración de RAG, garantizando que funcione sin problemas, se mantenga dentro del presupuesto y proporcione constantemente respuestas precisas y específicas del dominio.
Tomemos un ejemplo práctico y comprendamos por qué necesitamos utilizar la observabilidad mientras usamos RAG. Supongamos que creó la aplicación y ahora está en producción.
Chat con YouTube: observabilidad con la implementación de RAG
Veamos ahora los pasos de la observabilidad con la implementación de RAG.
Paso 1: instalación
Antes de continuar con la implementación del código, es necesario instalar algunas bibliotecas. Estas bibliotecas incluyen Más allá del LLM, AbiertoAI, ai/phoenix” target=”_blank” rel=”noreferrer noopener nofollow”>Fénixy API de transcripción de YouTube. Beyond LLM es una biblioteca que le ayuda a crear aplicaciones RAG avanzadas de manera eficiente, incorporando observabilidad, ajuste, incorporaciones y evaluación de modelos.
pip install beyondllm
pip install openai
pip install arize-phoenix(evals)
pip install youtube_transcript_api llama-index-readers-youtube-transcriptPaso 2: configurar la clave API de OpenAI
Configure la variable de entorno para la clave API de OpenAI, que es necesaria para autenticar y acceder a los servicios de OpenAI, como LLM e incrustación.
import os, getpass
os.environ('OPENAI_API_KEY') = getpass.getpass("API:")
# import required libraries
from beyondllm import source,retrieve,generator, llms, embeddings
from beyondllm.observe import ObserverPaso 3: Configurar la observabilidad
Habilitar la observabilidad debe ser el primer paso en su código para garantizar que se realice un seguimiento de todas las operaciones posteriores.
Observe = Observer()
Observe.run()Paso 4: definir LLM e incrustar
Dado que la clave API de OpenAI ya está almacenada en la variable de entorno, ahora puede definir el LLM y el modelo de incrustación para recuperar el documento y generar la respuesta en consecuencia.
llm=llms.ChatOpenAIModel()
embed_model = embeddings.OpenAIEmbeddings()Paso 5: RAG Parte 1-Retriever
BeyondLLM es un marco nativo para científicos de datos. Para ingerir datos, puede definir la fuente de datos dentro de la función “fit”. Según la fuente de datos, puede especificar el “tipo d”, en nuestro caso, es YouTube. Además, podemos fragmentar nuestros datos para evitar los problemas de longitud del contexto del modelo y devolver solo el fragmento específico. La superposición de fragmentos define la cantidad de tokens que deben repetirse en el fragmento consecutivo.
El recuperador automático en BeyondLLM ayuda a recuperar el número k relevante de documentos según el tipo. Hay varios tipos de recuperadores, como híbridos, reclasificadores, reclasificadores con incrustación de banderas y más. En este caso de uso, usaremos un recuperador normal, es decir, un recuperador en memoria.
data = source.fit("https://www.youtube.com/watch?v=IhawEdplzkI",
dtype="youtube",
chunk_size=512,
chunk_overlap=50)
retriever = retrieve.auto_retriever(data,
embed_model,
type="normal",
top_k=4)
Paso 6: Generador RAG Parte 2
El modelo generador combina la consulta del usuario y los documentos relevantes de la clase recuperador y los pasa al modelo de lenguaje grande. Para facilitar esto, BeyondLLM admite un módulo generador que encadena esta tubería, lo que permite una evaluación adicional de la tubería en la tríada RAG.
user_query = "summarize simple task execution worflow?"
pipeline = generator.Generate(question=user_query,retriever=retriever,llm=llm)
print(pipeline.call())Producción
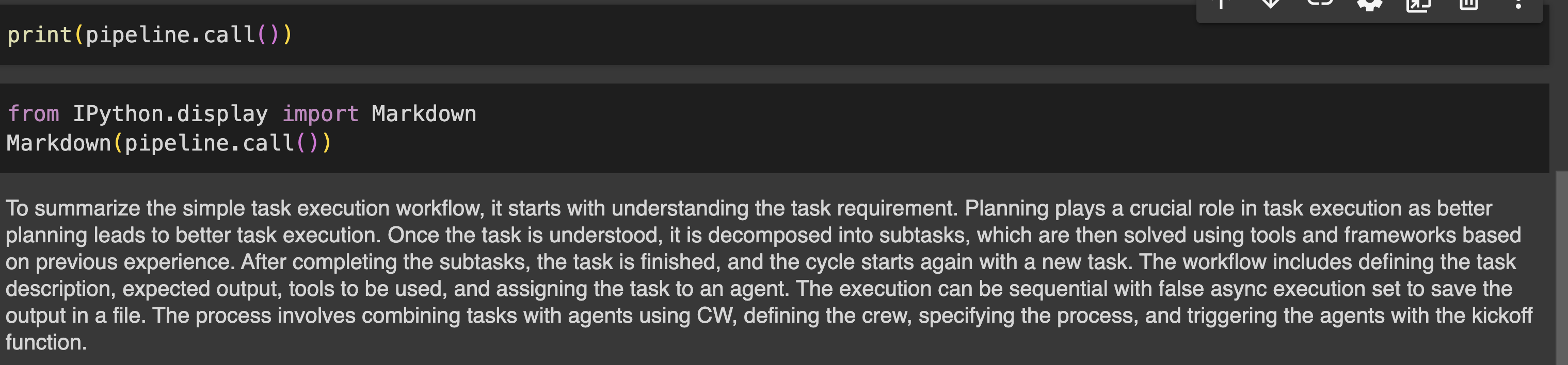
Paso 7: evaluar la tubería
La evaluación de la canalización RAG se puede realizar utilizando métricas de la tríada RAG que incluyen relevancia del contexto, relevancia de la respuesta y solidez.
- Relevancia del contexto : Mide la relevancia de los fragmentos recuperados por el auto_retriever en relación con la consulta del usuario. Determina la eficiencia del auto_retriever en la obtención de información contextualmente relevante, asegurando que la base para generar respuestas sea sólida.
- Relevancia de la respuesta : Evalúa la relevancia de la respuesta del LLM a la consulta del usuario.
- Conexión a tierra : Determina qué tan bien las respuestas del modelo de lenguaje se basan en la información recuperada por el auto_retriever, con el objetivo de identificar y eliminar cualquier contenido alucinado. Esto garantiza que los resultados se basen en información precisa y objetiva.
print(pipeline.get_rag_triad_evals())
#or
# run it individually
print(pipeline.get_context_relevancy()) # context relevancy
print(pipeline.get_answer_relevancy()) # answer relevancy
print(pipeline.get_groundedness()) # groundednessProducción:

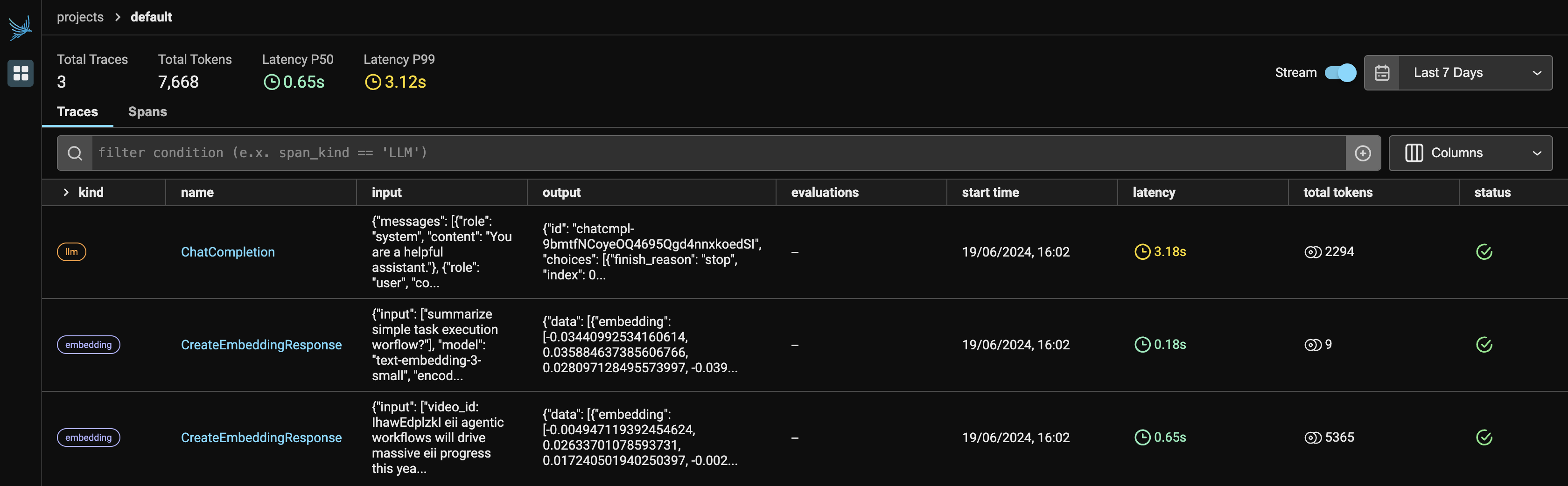
Panel de Phoenix: Análisis de observabilidad de LLM
La Figura 1 muestra el panel principal de Phoenix. Una vez que ejecuta Observer.run(), devuelve dos enlaces:
- Anfitrión local: http://127.0.0.1:6006/
- Si localhost no se está ejecutando, puede elegir un enlace alternativo para ver la aplicación Phoenix en su navegador.
Dado que estamos utilizando dos servicios de OpenAI, mostrará tanto LLM como incrustaciones bajo el proveedor. Mostrará la cantidad de tokens que utilizó cada proveedor, junto con la latencia, la hora de inicio, la entrada proporcionada a la solicitud de API y la salida generada por el LLM.
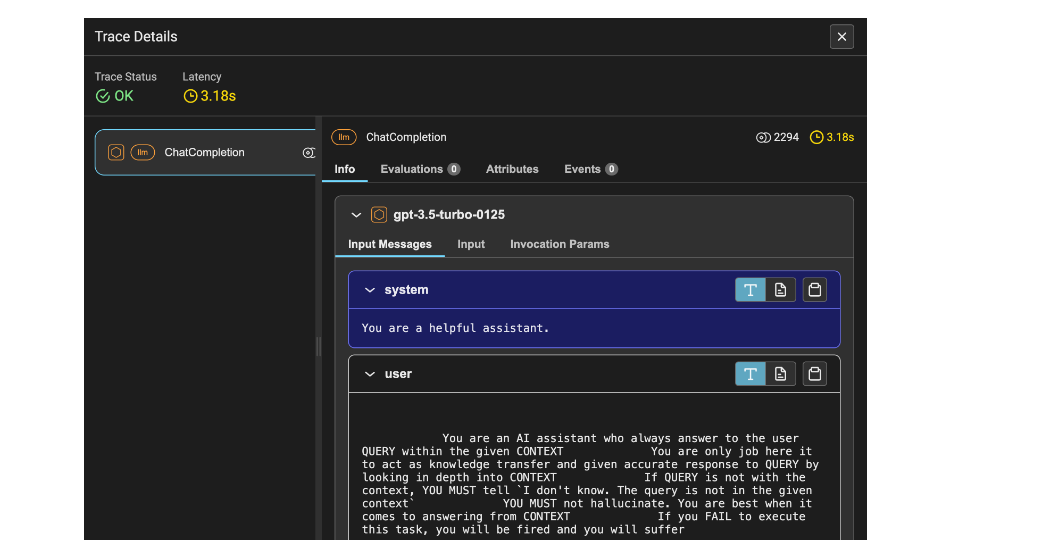
La Figura 2 muestra los detalles del seguimiento del LLM. Incluye la latencia, que es de 1,53 segundos, la cantidad de tokens, que es 2212, e información como el aviso del sistema, el aviso del usuario y la respuesta.
La Figura 3 muestra los detalles de seguimiento de las incrustaciones para la consulta del usuario realizada, junto con otras métricas similares a la Figura 2. En lugar de preguntar, verá la consulta de entrada convertida en incrustaciones.
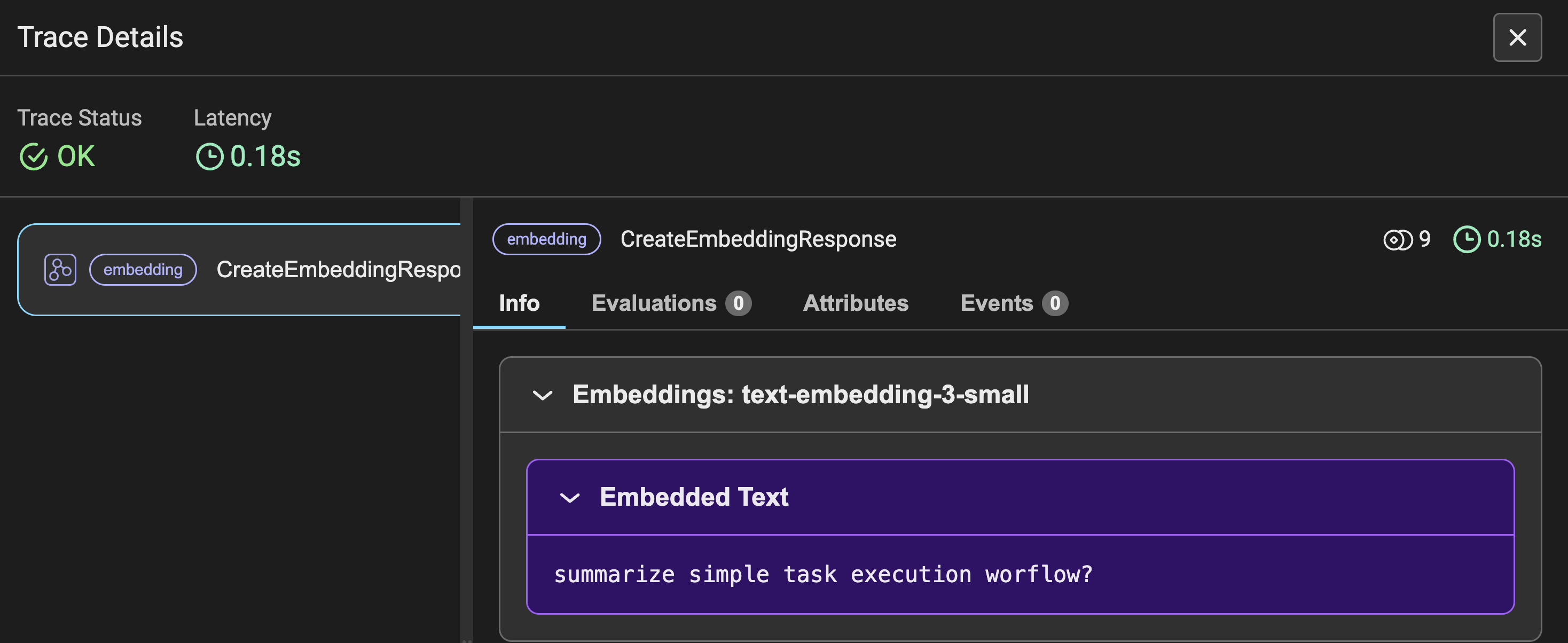
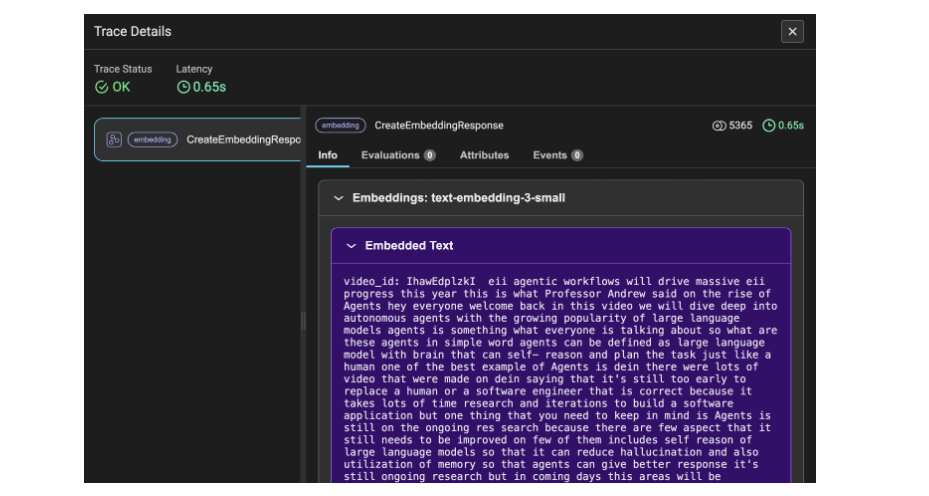
La Figura 4 muestra los detalles del seguimiento de las incrustaciones de los datos de la transcripción de YouTube. Aquí, los datos se convierten en fragmentos y luego en incrustaciones, razón por la cual los tokens utilizados ascienden a 5365. Este detalle de seguimiento indica los datos del video de la transcripción como información.
Conclusión
En resumen, ha creado con éxito una canalización de generación aumentada de recuperación (RAG) junto con conceptos avanzados como evaluación y observabilidad. Con este enfoque, puede utilizar aún más este aprendizaje para automatizar y escribir scripts para alertas si algo sale mal, o utilizar las solicitudes para rastrear los detalles del registro para obtener mejores conocimientos sobre el rendimiento de la aplicación y, por supuesto, mantener el costo. dentro del presupuesto. Además, incorporar observabilidad le ayuda a optimizar el uso del modelo y garantiza un rendimiento eficiente y rentable para sus necesidades específicas.
Conclusiones clave
- Comprender la necesidad de observabilidad mientras se crean aplicaciones basadas en LLM, como la generación aumentada de recuperación.
- Métricas clave para rastrear, como la cantidad de tokens, la latencia, las indicaciones y los costos de cada solicitud de API realizada.
- Implementación de RAG y evaluaciones de tríadas usando BeyondLLM con mínimas líneas de código.
- Monitoreo y seguimiento de la observabilidad de LLM utilizando BeyondLLM y Phoenix.
- Pocas ideas instantáneas sobre detalles de seguimiento de LLM e incorporaciones que deben automatizarse para mejorar el rendimiento de la aplicación.
Preguntas frecuentes
R. Cuando se trata de observabilidad, resulta útil realizar un seguimiento de modelos de código cerrado como GPT, Gemini, Claude y otros. Phoenix admite integraciones directas con Langchain, LLamaIndex y el marco DSPY, así como con proveedores independientes de LLM como OpenAI, Bedrock y otros.
R. BeyondLLM admite la evaluación del proceso de generación aumentada de recuperación (RAG) utilizando los LLM que admite. Puede evaluar fácilmente RAG en BeyondLLM con los modelos Ollama y HuggingFace. Las métricas de evaluación incluyen relevancia del contexto, relevancia de la respuesta, fundamento y verdad fundamental.
R. El costo de la API de OpenAI se gasta en la cantidad de tokens que utiliza. Aquí es donde la observabilidad puede ayudarle a seguir monitoreando y rastreando los tokens por solicitud, los tokens generales, los costos por solicitud y la latencia. Estas métricas realmente ayudan a activar una función para alertar el costo al usuario.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.





{kind=link}