 NEWSLETTER
NEWSLETTER
Imagine tener un asistente de investigación personal que no solo comprende su pregunta, sino que decide de manera inteligente cómo encontrar respuestas. Sumérgete en su biblioteca de documentos para algunas consultas mientras se genera respuestas creativas para otras. Esto es lo que es posible con un trapo de agente usando el sistema TypeScript de Llamaindex.
Ya sea que esté buscando crear un sistema de análisis de literatura, un asistente de documentación técnica o cualquier aplicación intensiva en conocimiento, los enfoques descritos en esta publicación de blog proporcionan una base práctica que puede construir. Esta publicación de blog lo llevará a un viaje práctico a través de la construcción de dicho sistema utilizando Llamado TypeScript, desde la configuración de modelos locales hasta la implementación de herramientas especializadas que trabajan juntas para ofrecer respuestas notablemente útiles.
Objetivos de aprendizaje
- Comprenda los fundamentos del trapo de agente utilizando el mecanografiado de Llamaindex para construir agentes inteligentes.
- Aprenda a configurar el entorno de desarrollo e instalar las dependencias necesarias.
- Explore la creación de herramientas en Llamaindex, incluidas las operaciones de adición y división.
- Implementar un agente de matemáticas usando Llamaindex TypeScript para ejecutar consultas.
- Ejecutar y probar el agente para procesar las operaciones matemáticas de manera eficiente.
Este artículo fue publicado como parte del Blogathon de ciencias de datos.
¿Por qué usar TypeScript?
TypeScript ofrece ventajas significativas para la aplicación de IA basada en Building LLM
- Tipo de seguridad: La tipificación estática de TypeScript capta errores durante el desarrollo en lugar de en tiempo de ejecución.
- Mejor soporte IDE: Las sugerencias de autocompleto y inteligentes hacen que el desarrollo sea más rápido
- Mejorar la mantenibilidad: La definición de tipo hace que el código sea más legible y autocompletador
- Integración de JavaScript perfecta: TypeScript funciona con las bibliotecas de JavaScript existentes
- Escalabilidad: La estructura de TypeScript ayuda a administrar la complejidad a medida que su aplicación de trapo crece.
- Marcos: VITE, NEXTJS, etc. Los marcos web robustos bien diseñados que se conectan perfectamente con TypeScript, lo que hace que la creación de aplicaciones web basadas en IA sea fácil y escalable.
Beneficios de llameindex
Llamaindex proporciona un poderoso marco para construir aplicaciones de IA basadas en LLM.
- Ingestión de datos simplificada: Métodos fáciles para cargar y procesar documentos en el dispositivo o en la nube utilizando llameAparse
- Almacenamiento de vector: Soporte incorporado para integrar y recuperar información semántica con diversas integraciones con bases de datos estándar de la industria como ChromAdB, Milvus, Weaviet y PGVector.
- Integración de herramientas: Marco para crear y administrar múltiples herramientas especializadas
- Enchufe de agente: Puede construir o conectar a los agentes de terceros fácilmente con Llamaindex.
- Consulta flexibilidad del motor: Procesamiento de consultas personalizable para diferentes casos de uso
- Soporte de persistencia: capacidad para guardar y cargar índices para una reutilización eficiente
¿Por qué Llamaindex TypeScript?
Llamaindex es un marco de IA popular para conectar fuentes de datos personalizadas con modelos de idiomas grandes. Mientras que los implementadores originales en Python, Llamaindex ahora ofrece una versión mecanografiada que aporta sus poderosas capacidades al ecosistema JavaScript. Esto es particularmente valioso para:
- Aplicaciones web y servicios node.js.
- JavaScript/TypeScript desarrolladores que desean mantenerse dentro de su lenguaje preferido.
- Proyectos que necesitan ejecutarse en entornos de navegador.
¿Qué es el trapo de agente?
Antes de sumergirnos en la implementación, aclaremos lo que significa para el trapo Agetntic.
- RAG (generación de recuperación de recuperación) es una técnica que mejora los resultados del modelo de lenguaje al recuperar primero la información relevante de una base de conocimiento, y luego usar esa información para generar respuestas más precisas y objetivas.
- Los sistemas de agente involucran IA que pueden decidir qué acciones tomar en función de las consultas de los usuarios, funcionando efectivamente como un asistente inteligente que elige las herramientas apropiadas para satisfacer las solicitudes.
Un sistema de RAG de agente combina estos enfoques, creando un asistente de IA que puede recuperar información de una base de conocimiento y usar otras herramientas cuando sea apropiado. Según la naturaleza de la pregunta del usuario, decide si utilizar su conocimiento incorporado, consultar la base de datos de vectores o llamar a herramientas externas.
Configuración de entorno de desarrollo
Instalar nodo en Windows
Para instalar el nodo en Windows, siga estos pasos.
# Download and install fnm:
winget install Schniz.fnm
# Download and install Node.js:
fnm install 22
# Verify the Node.js version:
node -v # Should print "v22.14.0".
# Verify npm version:
npm -v # Should print "10.9.2".Para otros sistemas, debe seguir este.
Un agente matemático simple
Creemos un agente matemático simple para comprender la API TypeScript de Llamaindex.
Paso 1: Configurar el entorno laboral
Cree un nuevo directorio y navegue por él e inicialice un proyecto Node.js e instale dependencias.
$ md simple-agent
$ cd simple-agent
$ npm init
$ npm install llamaindex @llamaindex/ollama Crearemos dos herramientas para el agente de matemáticas.
- Una herramienta de adición que agrega dos números
- Una herramienta de división que divide los números
Paso 2: Importar módulos requeridos
Agregue las siguientes importaciones a su script:
import { agent, Settings, tool } from "llamaindex";
import { z } from "zod";
import { Ollama, OllamaEmbedding } from "@llamaindex/ollama";Paso 3: crear una instancia de modelo Ollama
Instanciar el modelo de llama:
const llama3 = new Ollama({
model: "llama3.2:1b",
});Ahora, utilizando la configuración, establece directamente el modelo Ollama para el modelo principal del sistema o usa un modelo diferente directamente en el agente.
Settings.llm = llama3;Paso 4: Crear herramientas para el agente de matemáticas
Agregar y dividir herramientas
const addNumbers = tool({
name: "SumNubers",
description: "use this function to sun two numbers",
parameters: z.object({
a: z.number().describe("The first number"),
b: z.number().describe("The second number"),
}),
execute: ({ a, b }: { a: number; b: number }) => `${a + b}`,
});Aquí crearemos una herramienta llamada AddNumber usando la API de herramienta Llamaindex, el objeto de parámetros de herramienta contiene cuatro parámetros principales.
- Nombre: El nombre de la herramienta
- Descripción: La descripción de la herramienta que será utilizada por el LLM para comprender la capacidad de la herramienta.
- Parámetro: los parámetros de la herramienta, donde he utilizado bibliotecas Zod para la validación de datos.
- Ejecutar: la función que será ejecutada por la herramienta.
De la misma manera, crearemos la herramienta DividEnumber.
const divideNumbers = tool({
name: "divideNUmber",
description: "use this function to divide two numbers",
parameters: z.object({
a: z.number().describe("The dividend a to divide"),
b: z.number().describe("The divisor b to divide by"),
}),
execute: ({ a, b }: { a: number; b: number }) => `${a / b}`,
});Paso 5: crea el agente de matemáticas
Ahora en la función principal, crearemos un agente matemático que usará las herramientas para el cálculo.
async function main(query: string) {
const mathAgent = agent({
tools: (addNumbers, divideNumbers),
llm: llama3,
verbose: false,
});
const response = await mathAgent.run(query);
console.log(response.data);
}
// driver code for running the application
const query = "Add two number 5 and 7 and divide by 2"
void main(query).then(() => {
console.log("Done");
});Si establece su LLM directamente a través de la configuración, entonces no tiene que colocar los parámetros LLM del agente. Si desea usar diferentes modelos para diferentes agentes, debe poner explícitamente los parámetros LLM.
Después de esa respuesta es la función de espera del Mathagent que ejecutará la consulta a través del LLM y devolverá los datos.
Producción
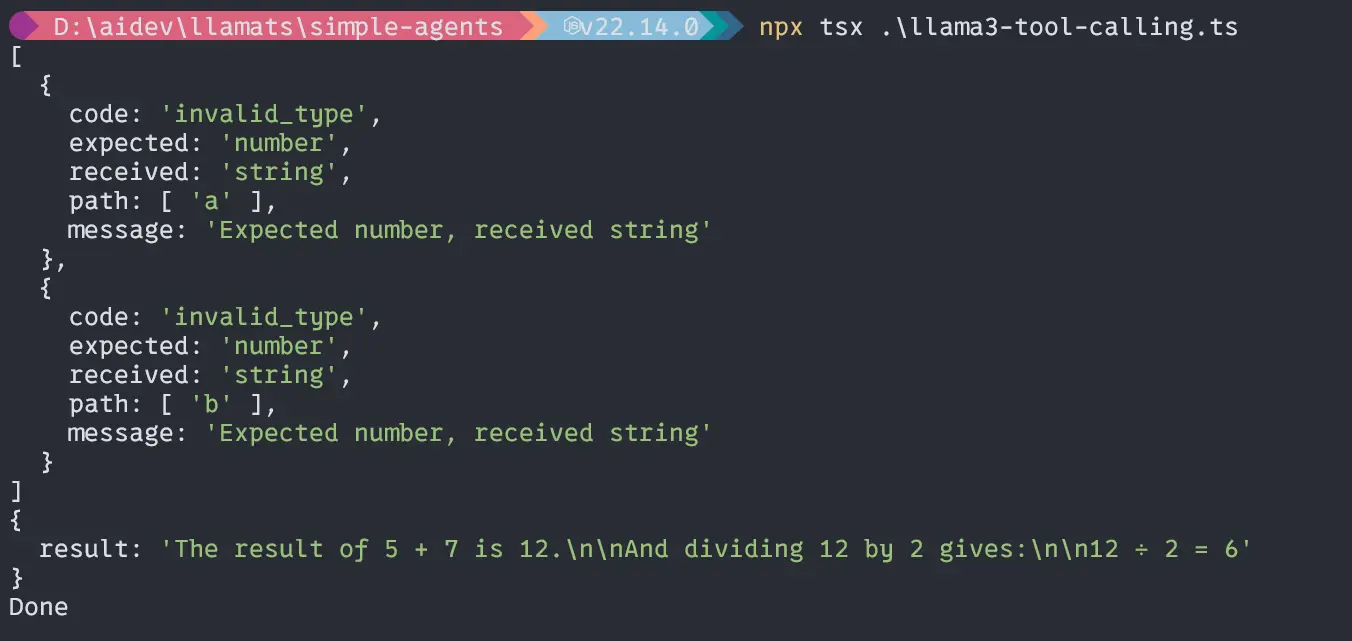
Segunda consulta “Si el número total de niños en una clase es de 50 y niñas es 30, ¿cuál es el número total de estudiantes en la clase?”;
const query =
"If the total number of boys in a class is 50 and girls is 30, what is the total number of students in the class?";
void main(query).then(() => {
console.log("Done");
});Producción
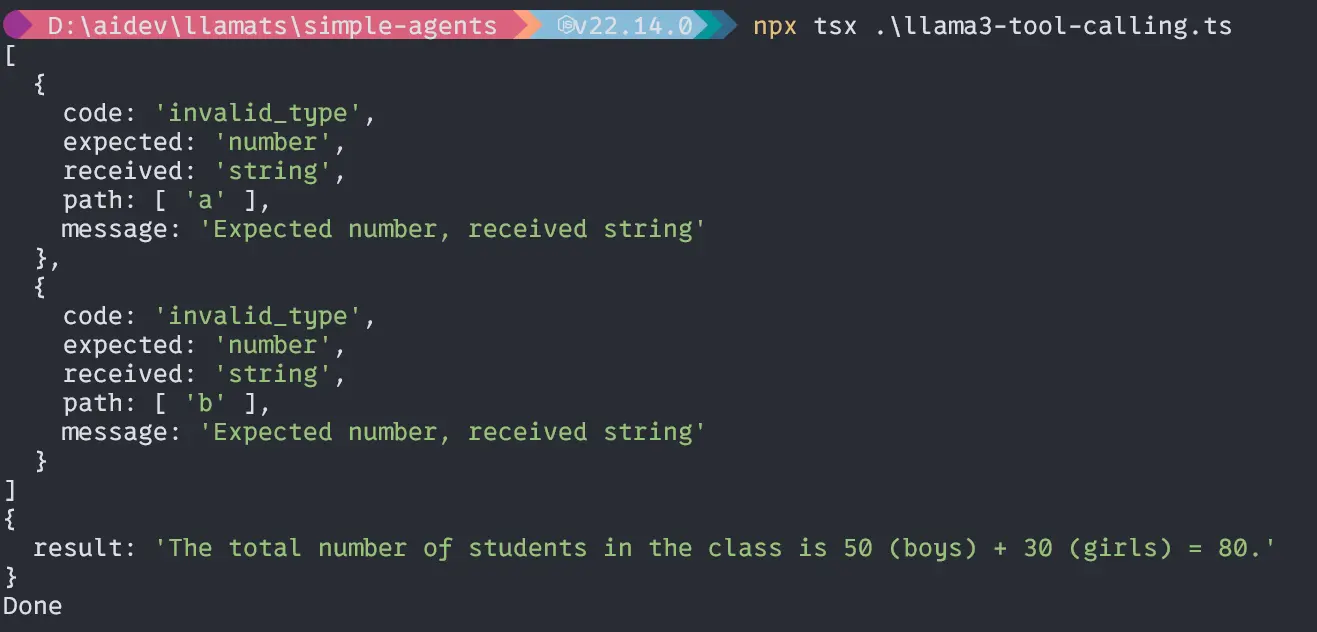
Wow, nuestro pequeño modelo LLAMA3.2 1B puede manejar bien a los agentes y calcular con precisión. Ahora, profundicemos en la parte principal del proyecto.
Comience a construir la aplicación RAG
Para configurar el entorno de desarrollo, siga las siguientes instrucciones
Crear nombre de carpeta Agentic-Rag-app:
$ md agentic-rag-app
$ cd agentic-rag-app
$ npm init
$ npm install llamaindex @llamaindex/ollama También extrae los modelos necesarios de Ollama aquí, LLAMA3.2: 1B y text-embebido.
En nuestra aplicación, tendremos cuatro módulos:
- Módulo de índice de carga para perder e indexar el archivo de texto
- Módulo de consulta para consultar el ensayo de Paul Graham
- módulo constante para almacenar constante reutilizable
- Módulo de aplicación para ejecutar la aplicación
Primero, cree el archivo de constantes y la carpeta de datos
Cree un archivo constant.ts en la raíz del proyecto.
const constant = {
STORAGE_DIR: "./storage",
DATA_FILE: "data/pual-essay.txt",
};
export default constant;Es un objeto que contiene las constantes necesarias que se utilizarán a lo largo de la aplicación varias veces. Es una mejor práctica poner algo así en un lugar separado. Después de eso, cree una carpeta de datos y coloque el archivo de texto en él.
Fuente de datos Enlace.
Implementación del módulo de carga e indexación
Veamos el siguiente diagrama para comprender la implementación del código.
Ahora, cree un nombre de archivo load-index.ts en la raíz del proyecto:
Importación de paquetes
import { Settings, storageContextFromDefaults } from "llamaindex";
import { Ollama, OllamaEmbedding } from "@llamaindex/ollama";
import { Document, VectorStoreIndex } from "llamaindex";
import fs from "fs/promises";
import constant from "./constant";Creación de instancias de modelo Ollama
const llama3 = new Ollama({
model: "llama3.2:1b",
});
const nomic = new OllamaEmbedding({
model: "nomic-embed-text",
});Configuración de los modelos del sistema
Settings.llm = llama3;
Settings.embedModel = nomic;Implementación de la función IndexandStorage
async function indexAndStorage() {
try {
// set up persistance storage
const storageContext = await storageContextFromDefaults({
persistDir: constant.STORAGE_DIR,
});
// load docs
const essay = await fs.readFile(constant.DATA_FILE, "utf-8");
const document = new Document({
text: essay,
id_: "essay",
});
// create and persist index
await VectorStoreIndex.fromDocuments((document), {
storageContext,
});
console.log("index and embeddings stored successfully!");
} catch (error) {
console.log("Error during indexing: ", error);
}
}El código anterior creará un espacio de almacenamiento persistente para indexar e integrar archivos. Luego obtendrá los datos de texto del directorio de datos del proyecto y creará un documento de ese archivo de texto utilizando el método de documento de Llamaindex y al final, comenzará a crear un índice vectorial a partir de ese documento utilizando el método VectorStoreIndex.
Exportar la función para su uso en el otro archivo:
export default indexAndStorage;Implementación del módulo de consulta
Un diagrama para la comprensión visual
Ahora, cree un nombre de archivo Query-Paul.ts en la raíz del proyecto.
Importación de paquetes
import {
Settings,
storageContextFromDefaults,
VectorStoreIndex,
} from "llamaindex";
import constant from "./constant";
import { Ollama, OllamaEmbedding } from "@llamaindex/ollama";
import { agent } from "llamaindex";La creación y la configuración de los modelos son los mismos que anteriores.
Implementación de carga y consulta
Ahora implementando la función LoadAnderkery
async function loadAndQuery(query: string) {
try {
// load the stored index from persistent storage
const storageContext = await storageContextFromDefaults({
persistDir: constant.STORAGE_DIR,
});
/// load the existing index
const index = await VectorStoreIndex.init({ storageContext });
// create a retriever and query engine
const retriever = index.asRetriever();
const queryEngine = index.asQueryEngine({ retriever });
const tools = (
index.queryTool({
metadata: {
name: "paul_graham_essay_tool",
description: `This tool can answer detailed questions about the essay by Paul Graham.`,
},
}),
);
const ragAgent = agent({ tools });
// query the stored embeddings
const response = await queryEngine.query({ query });
let toolResponse = await ragAgent.run(query);
console.log("Response: ", response.message);
console.log("Tool Response: ", toolResponse);
} catch (error) {
console.log("Error during retrieval: ", error);
}
}En el código anterior, configurando el contexto de almacenamiento desde el método stroage_dir, luego utilizando vectorstoreindex.init () cargaremos los archivos ya indexados de stroage_dir.
Después de cargar, crearemos un motor Retriever y consulta a partir de ese retriever. Y ahora, como hemos aprendido anteriormente, crearemos una herramienta que responderá la pregunta de los archivos indexados. Ahora, agregue esa herramienta al agente llamado Ragagent.
Luego consultaremos el ensayo indexado utilizando dos métodos uno del motor de consulta y el otro del agente y registrará la respuesta al terminal.
Exportar la función:
export default loadAndQuery;Es hora de juntar todos los módulos en un solo archivo de la aplicación para una fácil ejecución.
Implementación de App.ts
Crear un archivo app.ts
import indexAndStorage from "./load-index";
import loadAndQuery from "./query-paul";
function main(query: string) {
console.log("======================================");
console.log("Data Indexing....");
indexAndStorage();
console.log("Data Indexing Completed!");
console.log("Please, Wait to get your response or SUBSCRIBE!");
loadAndQuery(query);
}
const query = "What is Life?";
main(query);Aquí, importaremos todos los módulos, los ejecutaremos en serie y ejecutaremos.
Ejecutando la aplicación
$ npx tsx ./app.tsCuando se ejecute la primera vez que ocurrirán tres cosas.
- Pedirá instalar TSX, instálelo.
- Tomará tiempo incrustar el documento según sus sistemas (una vez).
- Luego devolverá la respuesta.
Primera vez ejecutando (similar a él)
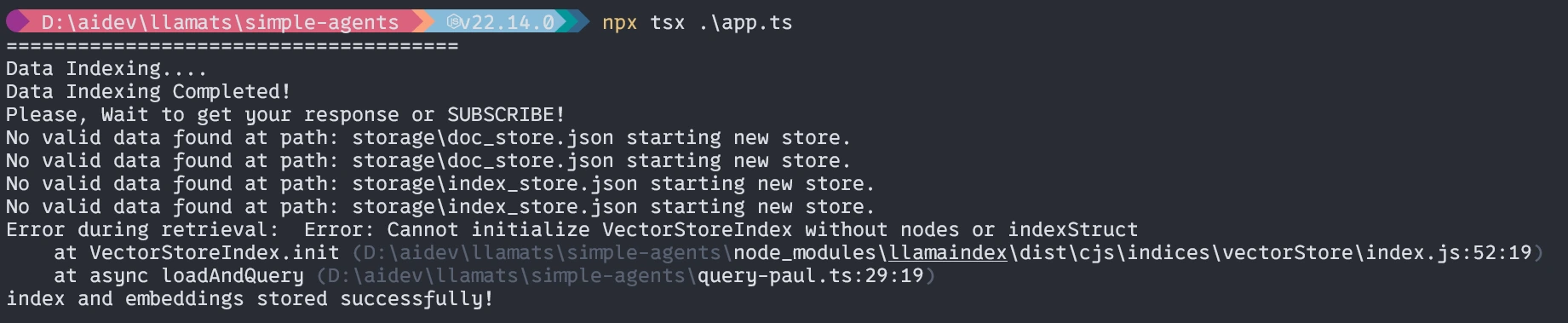
Sin el agente, la respuesta será similar a la que no es exacta.
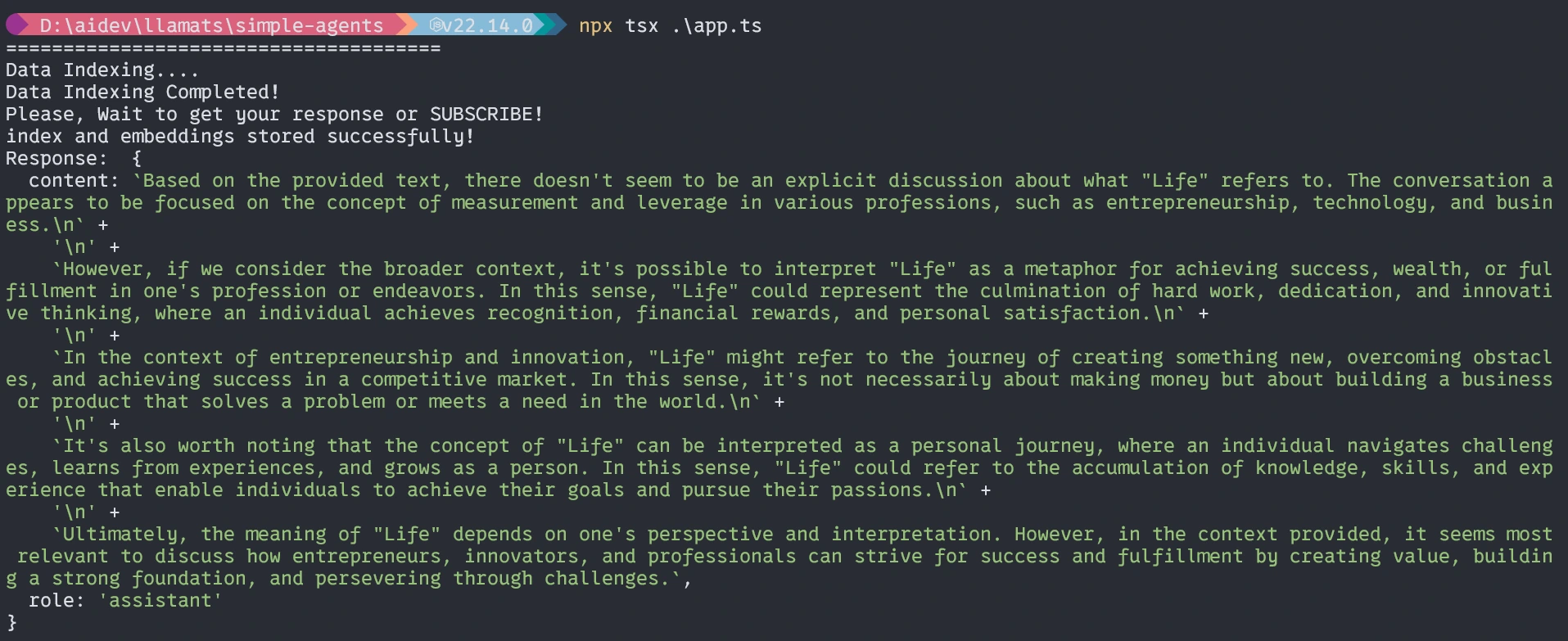
Con agentes
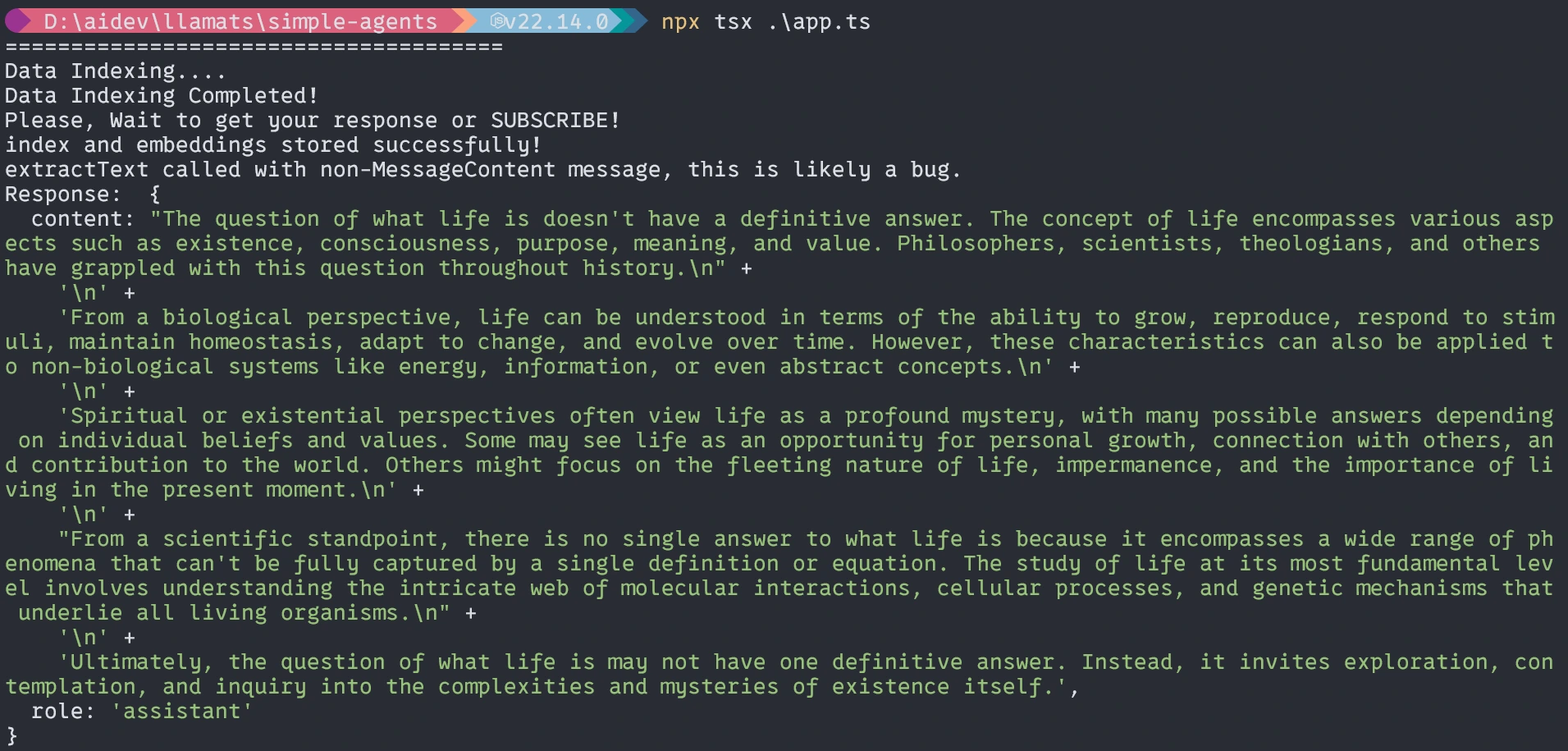

Eso es todo por hoy. Espero que este artículo lo ayude a aprender y comprender el flujo de trabajo con TypeScript.
Repositorio de código de proyecto aquí.
Conclusión
Este es un trapo de agente simple pero funcional que usa el sistema TypeScript Llamaindex. Con este artículo, quiero darle una idea de otro idioma además de Python para construir un trapo de agente usando Llamaindex TypeScript o cualquier otra aplicación basada en LLM ai. El sistema de RAG de Agentic representa una poderosa evolución más allá de la implementación básica del trapo, lo que permite respuestas más inteligentes y flexibles a las consultas de los usuarios. Utilizando Llamaindex con TypeScript, puede construir dicho sistema de una manera mantenible y segura que se integre bien con el ecosistema de aplicaciones web.
Control de llave
- TypeScript + Llamaindex proporciona una base robusta para la construcción de sistemas de trapo.
- El almacenamiento persistente de incrustaciones mejora la eficiencia de las consultas repetidas.
- Los enfoques de agente permiten una selección de herramientas más inteligente basada en el contenido de consulta.
- La ejecución del modelo local con Ollama ofrece privacidad y ventajas de costos.
- Las herramientas especializadas pueden abordar diferentes aspectos del conocimiento del dominio.
- El trapo de agente que usa Llamaindex TypeScript mejora la generación de recuperación y la generación de recuperación al permitir respuestas inteligentes y dinámicas.
Preguntas frecuentes
R. Puede modificar la función de indexación para cargar documentos de varios archivos o fuentes de datos y pasar una matriz de objetos de documento al método VectorStoreIndex.
¡A. Sí! Llamaindex apoya a varios proveedores de LLM, incluidos OpenAi, Antrópico y otros. Puede reemplazar la configuración de Ollama con cualquier proveedor compatible.
R. Considere ajustar su modelo de incrustación en datos específicos de dominio o implementar estrategias de recuperación personalizadas que prioricen ciertas secciones de documentos en función de su caso de uso específico.
R. La consulta directa simplemente recupera el contenido relevante y genera una respuesta, mientras que el agente abordado primero decide qué herramienta es más apropiada para la consulta, potencialmente combinando información de múltiples fuentes o utilizando un procesamiento especializado para diferentes tipos de consultas.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se usan a discreción del autor.

Un aprendizaje autodidacta y basado en proyectos, le encanta trabajar en proyectos complejos sobre aprendizaje profundo, visión por computadora y PNL. Siempre trato de comprender profundamente el tema que puede estar en cualquier campo, como el aprendizaje profundo, el aprendizaje automático o la física. Me encanta crear contenido en mi aprendizaje. Intenta compartir mi comprensión con los mundos.
Inicie sesión para continuar leyendo y disfrutando de contenido curado por expertos.
(Tagstotranslate) Blogathon





