
Introducción
Todo el mundo necesita tener inferencias más rápidas y fiables a partir de los modelos de lenguaje grande. vLLM, un marco de código abierto de vanguardia diseñado para simplificar la implementación y la gestión de modelos de lenguaje grandes con un rendimiento muy reducido. vLLM facilita su trabajo al ofrecer herramientas eficientes y escalables para trabajar con LLM. Con vLLM, puede gestionar todo, desde la carga y la inferencia del modelo hasta el ajuste y el servicio, todo centrándose en el rendimiento y la simplicidad. En este artículo implementaremos vLLM utilizando el modelo Gemma-7b-it de HuggingFace. Vamos a sumergirnos.
Objetivos de aprendizaje
- Descubra de qué se trata vLLM, incluida una descripción general de su arquitectura y por qué está generando tanta expectación en la comunidad de IA.
- Comprenda la importancia de KV Cache y PagedAttention, que forman la arquitectura central que permite una gestión eficiente de la memoria y una rápida inferencia y servicio de LLM.
- Aprenda y explore en detalle la guía de vLLM usando Gemma-7b-it
- Además, explore cómo implementar modelos HuggingFace, como Gemini, utilizando vLLM.
- Comprenda la importancia de utilizar parámetros de muestreo en vLLM, lo que ayuda a modificar el rendimiento del modelo.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Descripción general de la arquitectura vLLM
vLLM, abreviatura de “Modelo de lenguaje grande virtual”, es un marco de código abierto diseñado para agilizar y optimizar el uso de modelos de lenguaje grande (LLM) en diversas aplicaciones. vLLM cambia las reglas del juego en el espacio de la IA y ofrece un enfoque simplificado para manejar grandes modelos de lenguaje. Su enfoque único en el rendimiento y la escalabilidad lo convierte en una herramienta esencial para los desarrolladores que buscan implementar y administrar modelos de lenguaje de manera efectiva.
El revuelo en torno a vLLM se debe a su capacidad para manejar las complejidades asociadas con los modelos de lenguaje a gran escala, como la gestión eficiente de la memoria, la inferencia rápida y la integración perfecta con los flujos de trabajo de IA existentes. Los métodos tradicionales a menudo tienen problemas con la gestión eficiente de la memoria y la inferencia rápida, dos desafíos críticos cuando se trabaja con conjuntos de datos masivos y modelos complejos. vLLM aborda estos problemas de frente, ofreciendo una integración perfecta con los flujos de trabajo de IA existentes y reduciendo significativamente la carga técnica de los desarrolladores.
Para entender cómo, comprendamos el concepto de KV Cache y PagedAttention.
Entendiendo la caché KV
KV Cache (Key-Value Cache) es una técnica utilizada en modelos de transformadores, específicamente en el contexto de mecanismos de atención, para almacenar y reutilizar los resultados intermedios de los cálculos de claves y valores durante la fase de inferencia. Este almacenamiento en caché reduce significativamente la sobrecarga computacional al evitar la necesidad de volver a calcular estos valores para cada nuevo token en una secuencia, lo que acelera el tiempo de procesamiento.
¿Cómo funciona la caché KV?
- En los modelos de transformador, el mecanismo de Atención se basa en claves (K) y valores (V) derivados de los datos de entrada. Cada token en la secuencia de entrada genera una clave y un valor.
- Durante la inferencia, una vez que se calculan las claves y los valores de los tokens iniciales, se almacenan en una memoria caché.
- Para los tokens posteriores, el modelo recupera las claves y los valores almacenados en caché en lugar de volver a calcularlos. Esto permite que el modelo procese de manera eficiente secuencias largas aprovechando la información previamente calculada.
Representación matemática
- Sean K_i y V_i los vectores clave y de valor del token i.
- El caché los almacena como K_cache = {K_1, K_2,…, K_n} y V_cache = {V_1, V_2,…, V_n}.
- Para un nuevo token t, el mecanismo de atención calcula las puntuaciones de atención utilizando la consulta Q_t con todas las claves almacenadas en caché K_cache.
A pesar de ser tan eficiente, en la mayoría de los casos, la caché KV es grande. Por ejemplo, en el modelo LLaMA-13B, una sola secuencia puede ocupar hasta 1,7 GB. El tamaño de la caché KV depende de la longitud de la secuencia, que es variable e impredecible, lo que genera un uso ineficiente de la memoria.
Los métodos tradicionales suelen desperdiciar entre el 60% y el 80% de la memoria debido a la fragmentación y la reserva excesiva. Para mitigar esto, vLLM presenta PagedAttention.
¿Qué es la atención paginada?
PagedAttention aborda el desafío de gestionar eficientemente el consumo de memoria cuando se manejan secuencias de entrada muy grandes, lo que puede ser un problema importante en los modelos de transformadores. A diferencia de KV Cache, que optimiza el cálculo reutilizando pares clave-valor previamente calculados, PagedAttention mejora aún más la eficiencia al dividir la secuencia de entrada en páginas más pequeñas y manejables. El concepto opera utiliza estas páginas manejables y realiza cálculos de atención dentro de estas páginas.
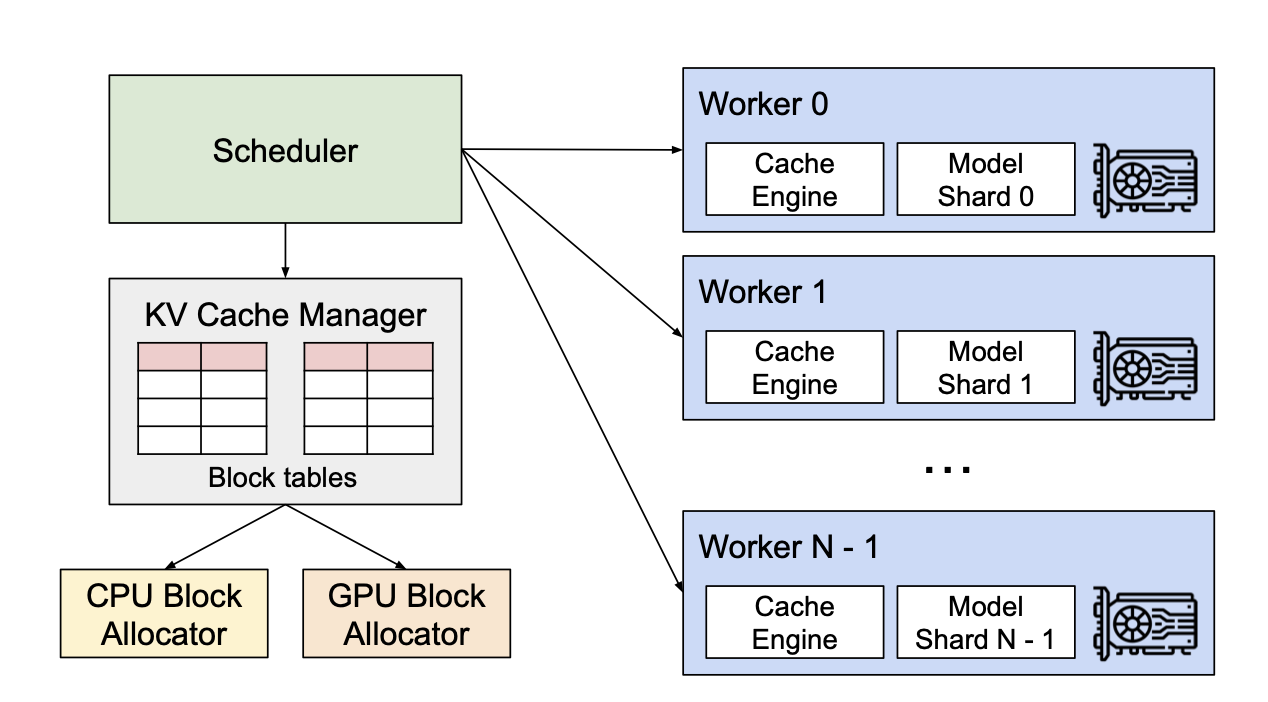
¿Cómo funciona?
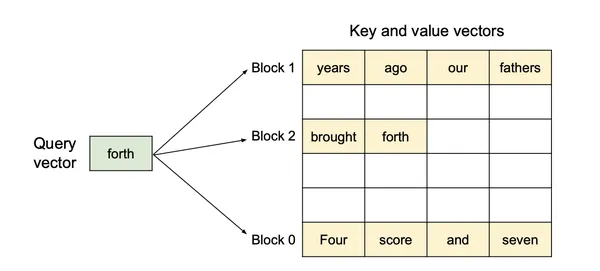
A diferencia de los algoritmos de atención tradicionales, PagedAttention permite el almacenamiento de claves y valores continuos en un espacio de memoria fragmentado. Específicamente, PagedAttention divide la caché KV de cada secuencia en bloques KV distintos.
- En los modelos de transformadores, el mecanismo de atención se basa en claves (K) y valores (V) derivados de los datos de entrada. Cada token en la secuencia de entrada genera una clave y un valor.
- Durante la inferencia, una vez que se calculan las claves y los valores de los tokens iniciales, se almacenan en una memoria caché.
- Para los tokens posteriores, el modelo recupera las claves y los valores almacenados en caché en lugar de volver a calcularlos. Esto permite que el modelo procese de manera eficiente secuencias largas aprovechando la información previamente calculada.
Representación matemática
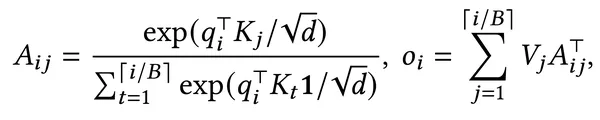
- B sea el tamaño del bloque KV (número de tokens por bloque)
- K_j sea el bloque de claves que contiene tokens desde la posición (j-1)B + 1 hasta j_B
- V_j sea el bloque de valor que contiene tokens desde la posición (j-1)B + 1 hasta j_B
- q_i sea el vector de consulta para el token i
- A_ij sea la matriz de puntuación de atención entre q_i y K_j
- o_i sea el vector de salida para el token i
- El vector de consulta `q_i` se multiplica por cada bloque KV (`K_j`) para calcular las puntuaciones de atención de todos los tokens dentro de ese bloque (`A_ij`).
- Luego, las puntuaciones de atención se utilizan para calcular el promedio ponderado de los vectores de valores correspondientes (`V_j`) dentro de cada bloque, lo que contribuye al resultado final `o_i`.
Esto a cambio permite una gestión flexible de la memoria:
- Eliminando la necesidad de asignación de memoria contigua al eliminar la fragmentación interna y externa.
- Los bloques KV se pueden asignar según demanda a medida que se expande la caché KV.
- Los bloques físicos se pueden compartir entre múltiples solicitudes y secuencias, lo que reduce la sobrecarga de memoria.
Inferencia del modelo Gemma usando vLLM
Implementemos el marco vLLM utilizando el modelo Gemma-7b-it de HuggingFace Hub.
Paso 1: Instalación del módulo
Para comenzar, comencemos instalando el módulo.
!pip install vllmPaso 2: definir LLM
Primero, importamos las bibliotecas necesarias y configuramos nuestro token API Hugging Face. Solo necesitamos configurar el token API de HuggingFace para algunos modelos que requieren permiso. Luego, inicializamos el modelo google/gemma-7b-it con una longitud máxima de 2048 tokens, lo que garantiza un uso eficiente de la memoria con torch.cuda.empty_cache() para un rendimiento óptimo.
import torch,os
from vllm import LLM
os.environ('HF_TOKEN') = ""
model_name = "google/gemma-7b-it"
llm = LLM(model=model_name,max_model_len=2048)
torch.cuda.empty_cache()Paso 3: Guía de parámetros de muestreo en vLLM
SamplingParams es similar a los argumentos de palabras clave del modelo en la canalización de Transformers. Este muestreo de parámetros es esencial para lograr la calidad y el comportamiento de salida deseados.
- temperatura: Este parámetro controla la aleatoriedad de las predicciones del modelo. Los valores más bajos hacen que el resultado del modelo sea más determinista, mientras que los valores más altos aumentan la aleatoriedad.
- arriba_p: Este parámetro limita la selección de tokens a un subconjunto cuya probabilidad acumulada está por encima de un cierto umbral (p). Para simplemente considerar top_p como 0,95, entonces el modelo considera solo el 95% de las siguientes palabras probables, lo que ayuda a mantener un equilibrio entre creatividad y coherencia, evitando que el modelo genere tokens de baja probabilidad y, a menudo, irrelevantes.
- penalización_repetición: Este parámetro penaliza los tokens repetidos, lo que anima al modelo a generar resultados más variados y menos repetitivos.
- tokens_max: Los tokens máximos determinan el número máximo de tokens en la salida generada.
from vllm import SamplingParams
sampling_params = SamplingParams(temperature=0.1,
top_p=0.95,
repetition_penalty = 1.2,
max_tokens=1000
)Paso 4: Plantilla de solicitud para el modelo Gemma
Cada modelo de código abierto tiene su propia plantilla de aviso única con tokens especiales específicos. Por ejemplo, Gemma utiliza y como marcadores de fichas especiales. Estos tokens indican el comienzo y el final de una plantilla de chat, respectivamente, tanto para los roles de usuario como de modelo.
def get_prompt(user_question):
template = f"""
user
{user_question}
model
"""
return template
prompt1 = get_prompt("best time to eat your 3 meals")
prompt2 = get_prompt("generate a python list with 5 football players")
prompts = (prompt1,prompt2)Paso 5: inferencia vLLM
Ahora que todo está configurado, deje que el LLM genere la respuesta al mensaje del usuario.
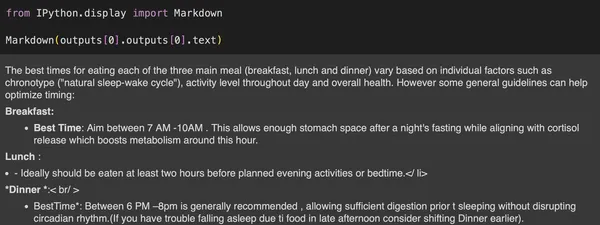
from IPython.display import Markdown
outputs = llm.generate(prompts, sampling_params)
display(Markdown(outputs(0).outputs(0).text))
display(Markdown(outputs(1).outputs(0).text))Una vez que se ejecutan las salidas, devuelve el resultado de las solicitudes procesadas que contiene velocidad y salida, es decir, token por segundo. Esta evaluación comparativa de velocidad es beneficiosa para mostrar la diferencia entre la inferencia vllm y otras. Como puede observar en solo 6,69 segundos, generamos dos mensajes de usuario.
Paso 6: evaluación comparativa de velocidad
Mensajes procesados: 100%|██████████| 2/2 (00:13<00:00, 6,69 s/it, velocidad est. de entrada: 3,66 toks/s, salida: 20,70 toks/s)
Salida: Mensaje-1
Salida: Mensaje-2

Conclusión
Ejecutamos exitosamente el LLM con latencia reducida y utilización eficiente de la memoria. vLLM es un marco de código abierto innovador en IA, que proporciona no solo un servicio de LLM rápido y rentable, sino que también facilita la implementación perfecta de LLM en varios puntos finales. En este artículo exploramos la guía para vLLM usando Gemma-7b-it.
ai/en/latest/” target=”_blank” rel=”noreferrer noopener nofollow”>Haga clic aquí para acceder a la documentación.
Conclusiones clave
- La optimización del LLM en la memoria es muy crítica y con vLLM se puede lograr fácilmente una inferencia y un servicio más rápidos.
- Comprender en profundidad los conceptos básicos del mecanismo de atención puede llevar a comprender cuán beneficiosos son los mecanismos de PagedAttention y el caché KV.
- La implementación de la inferencia vLLM en cualquier modelo de HuggingFace es bastante sencilla y requiere muy pocas líneas de código para lograrla.
- Es muy importante definir los parámetros de muestreo en vLLM, si se necesita la respuesta correcta de vLLM.
Preguntas frecuentes
R. HuggingFace hub es la plataforma donde se alojan la mayoría de los modelos de lenguajes grandes. vLLM proporciona la compatibilidad para realizar la inferencia en cualquier modelo de lenguaje grande de código abierto de HuggingFace. Además, vLLM también ayuda en el servicio y la implementación del modelo en los puntos finales.
R. Groq es un servicio con hardware de alto rendimiento diseñado específicamente para tareas de inferencia de IA más rápidas, particularmente a través de sus Unidades de Procesamiento del Lenguaje (LPU). Estas LPU ofrecen latencia ultrabaja y alto rendimiento, optimizadas para manejar secuencias en LLM. mientras que vLLM es un marco de código abierto destinado a simplificar la implementación y la gestión de la memoria de LLM para una inferencia y un servicio más rápidos.
R. Sí, puede implementar LLM utilizando vLLM, que ofrece inferencia eficiente a través de técnicas avanzadas como PagedAttention y KV Caching. Además, vLLM proporciona una integración perfecta con los flujos de trabajo de IA existentes, lo que facilita la configuración e implementación de modelos de bibliotecas populares como Hugging Face.
Referencia
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.






{kind=link}