
Exploring new frontiers in cybersecurity is essential as digital threats evolve. Traditional approaches, such as manual source code audits and reverse engineering, have been instrumental in identifying vulnerabilities. However, the increasing capabilities of large language models (LLM) present a unique opportunity to transcend these conventional methods, potentially uncovering and mitigating previously undetectable security vulnerabilities.
The challenge in cybersecurity is the persistent threat of “unidentifiable” vulnerabilities: flaws that evade detection by conventional automated systems. These vulnerabilities pose significant risks as they often go undetected until they are exploited. The advent of sophisticated LLM offers a promising solution by potentially replicating the analytical prowess of human experts to identify these elusive threats.
Over the years, the Google Project Zero research team has synthesized insights from its extensive experience researching human-driven vulnerabilities to refine the application of LLMs in this field. They identified key principles that leverage the strengths of LLMs while addressing their limitations. Crucial to their findings is the importance of extensive reasoning processes, which have been shown to be effective in various tasks. An interactive environment is essential, allowing models to adjust and correct errors dynamically, improving their effectiveness. Additionally, equipping LLMs with specialized tools such as Python debuggers and interpreters is vital to mimic the operating environment of human researchers and perform accurate calculations and state inspections. The team also emphasizes the need for a sampling strategy that allows for the exploration of multiple hypotheses across different trajectories, facilitating more comprehensive and effective vulnerability research. These principles take advantage of the capabilities of LLMs to obtain more accurate and reliable results in security tasks.
The research team has developed “Nap time”, a pioneering architecture for LLM-assisted vulnerability research. Naptime incorporates a specialized architecture that equips LLMs with specific tools to improve their ability to perform security analysis effectively. A key aspect of this architecture is its focus on grounding through tooling, ensuring that LLMs' interactions with the target codebase closely mimic the workflows of life security researchers. This approach allows for automatic verification of agent outputs, a vital feature considering the autonomous nature of the system.
The Naptime architecture focuses on the interaction between an ai agent and a target codebase, equipped with tools such as Code Browser, Python, Debugger and Reporter. The code browser allows the agent to navigate and analyze the code base in depth, similar to how engineers use tools like Chromium Code Search. The Python tool and debugger allow the agent to perform intermediate calculations and dynamic analysis, improving the accuracy and depth of security testing. These tools work together within a structured environment to autonomously detect and verify security vulnerabilities, ensuring the integrity and reproducibility of research results.
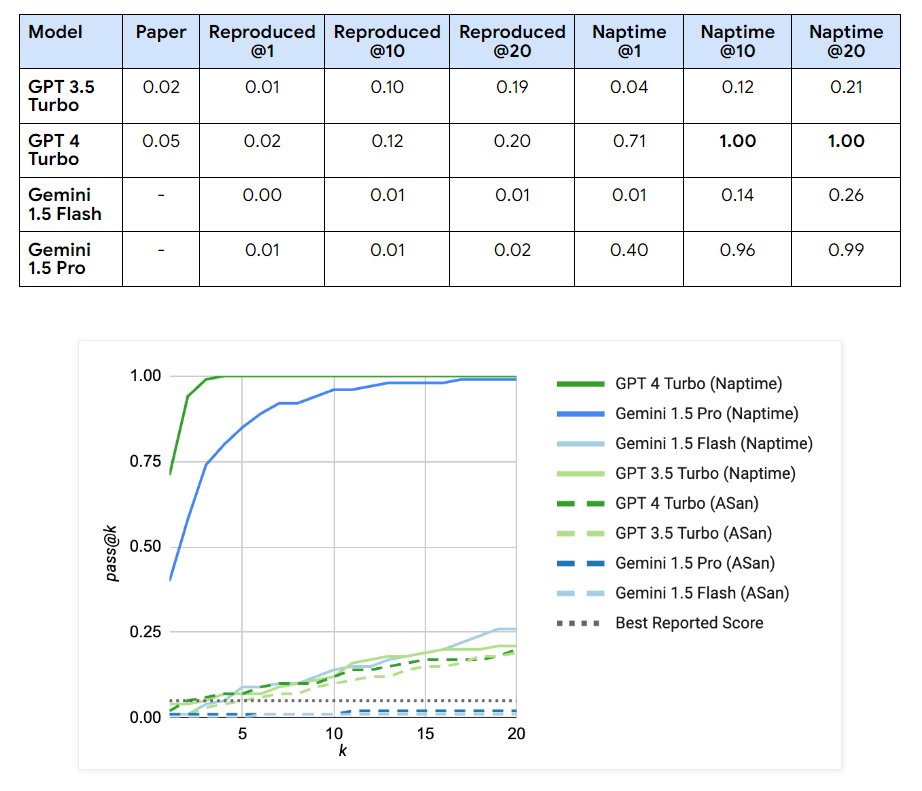
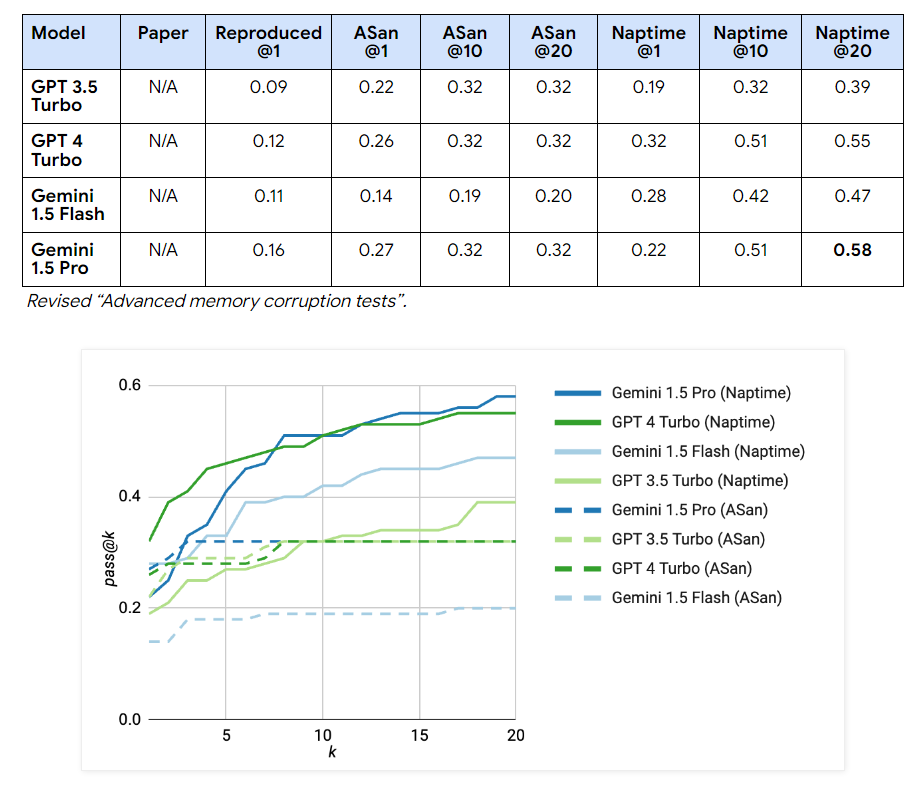
Researchers have integrated the Naptime architecture with the CyberSecEval 2 evaluation, substantially improving the performance of LLM security tests. For “buffer overflow” scenarios, GPT 4 Turbo scores increased to perfect passes using the Naptime architecture, achieving 1.00 across multiple tests, compared to its initial scores of 0.05. Similarly, improvements were evident in the “Advanced Memory Corruption” category, with GPT 4 Turbo performance increasing from 0.16 to 0.76 in more complex test scenarios. The Gemini models also showed marked improvements; For example, Gemini 1.5 Pro scores on Naptime configurations increased to 0.58, demonstrating significant gains in handling complex tasks compared to the initial testing phases. These results underscore the effectiveness of the Naptime framework in improving the accuracy and ability of LLMs to perform detailed and accurate vulnerability assessments.
To conclude, the Naptime project demonstrates that LLMs can significantly improve their performance in vulnerability research with the right tools, particularly in controlled test environments such as CTF-style challenges. However, the real challenge lies in translating this capability to the complexities of autonomous offensive security research, where understanding system states and attacker control is crucial. The study highlights the need to provide LLMs with flexible and iterative processes similar to those employed by expert human researchers to truly reflect their potential. As the Google Project Zero team, in collaboration with Google DeepMind, continues to develop this technology, they remain committed to pushing the boundaries of what LLMs can achieve in cybersecurity, promising more sophisticated advances in the future.
Nikhil is an internal consultant at Marktechpost. He is pursuing an integrated double degree in Materials at the Indian Institute of technology Kharagpur. Nikhil is an ai/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in materials science, he is exploring new advances and creating opportunities to contribute.






{kind=link}