
In Transformer architectures, computational costs and activation memory grow linearly with increasing feedforward layers’ hidden layer width (FFW). This scaling issue poses a significant challenge, especially as models become larger and more complex. Overcoming this challenge is essential to advancing ai research, as it directly impacts the feasibility of deploying large-scale models in real-world applications such as language modeling and natural language processing tasks.
Current methods addressing this challenge use mixture-of-experts (MoE) architectures, which implement sparsely activated expert modules instead of a single dense FFW layer. This approach allows decoupling model size from computational cost. Despite the promise of MoEs, as demonstrated by researchers such as Shazeer et al. (2017) and Lepikhin et al. (2020), these models face computational and optimization challenges when scaling beyond a small number of experts. Efficiency gains often stagnate with increasing model size due to a fixed number of training tokens. These limitations prevent the full potential of MoEs from being realized, especially in tasks that require extensive and continuous learning.
Google DeepMind researchers propose a new approach called Parameter Efficient Expert Retrieval (PEER), which specifically addresses the limitations of existing MoE models. PEER leverages the product key technique for sparse retrieval from a vast pool of small experts, numbering over a million. This approach improves the granularity of MoE models, resulting in a better balance between performance and computation. The innovation lies in the use of a learned index structure for routing, enabling efficient and scalable expert retrieval. This method decouples the computational cost from parameter counting, which represents a significant advancement over previous architectures. PEER layers demonstrate substantial improvements in efficiency and performance for language modeling tasks.
The PEER layer operates by mapping an input vector to a query vector, which is then compared to a set of product keys to retrieve the top k experts. These experts are single-neuron multilayer perceptrons (MLPs) that contribute to the final result through a weighted combination based on router scores. The product key retrieval technique reduces the complexity of expert retrieval, making it possible to handle over a million experts efficiently. The dataset used for the experiments is the C4 dataset, with isoFLOP analysis performed to compare PEER with dense FFW, coarse-grained MoE, and product key memory (PKM) layers. The experiments involved varying the model size and the number of training tokens to identify optimal computation configurations.
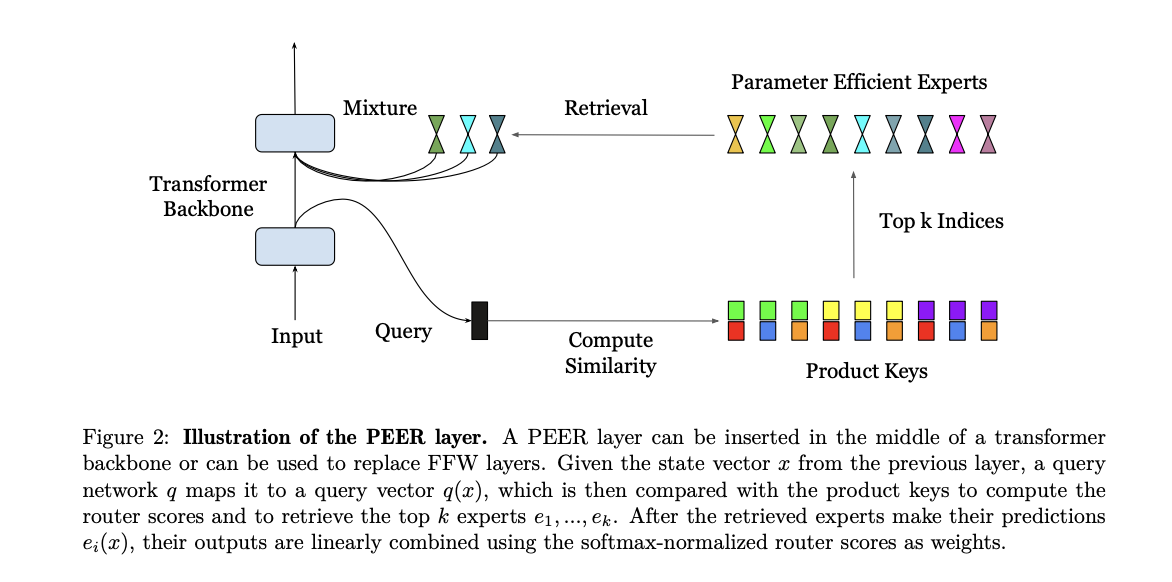
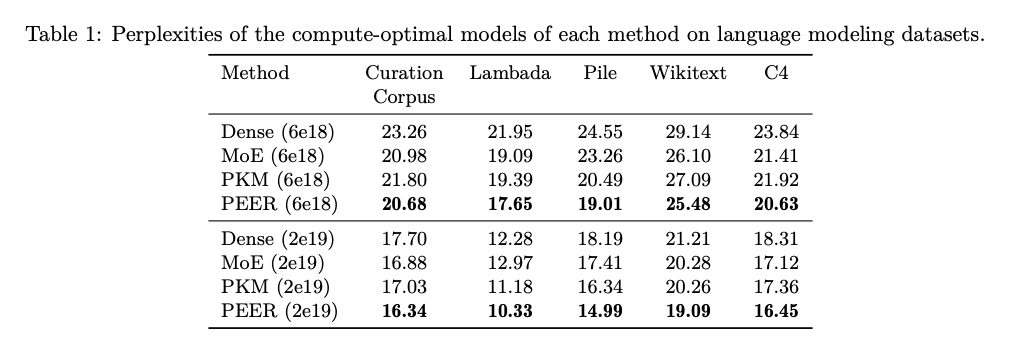
The results show that PEER layers significantly outperform dense FFWs and coarse-grained MoEs in terms of performance-computation trade-off. When applied to several language modeling datasets including Curation Corpus, Lambada, Pile, Wikitext, and C4, PEER models achieved noticeably lower perplexity scores. For example, with a FLOP budget of 2e19, PEER models achieved a perplexity of 16.34 on the C4 dataset, which is lower compared to 17.70 for dense models and 16.88 for MoE models. These findings highlight the efficiency and effectiveness of the PEER architecture in improving the scalability and performance of Transformer models.
In conclusion, this proposed method represents a significant contribution to ai research by introducing the PEER architecture. This novel approach addresses the computational challenges associated with scaling transformer models by leveraging a large number of small experts and efficient routing techniques. The superior performance-to-computation ratio of the PEER model, demonstrated through extensive experiments, highlights its potential to advance ai research by enabling more efficient and powerful language models. The findings suggest that PEER can effectively scale to handle large and continuous data streams, making it a promising solution for lifelong learning and other demanding ai applications.
Review the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter.
Join our Telegram Channel and LinkedIn GrAbove!.
If you like our work, you will love our Newsletter..
Don't forget to join our Subreddit with over 46 billion users
Aswin AK is a Consulting Intern at MarkTechPost. He is pursuing his dual degree from Indian Institute of technology, Kharagpur. He is passionate about Data Science and Machine Learning and has a strong academic background and hands-on experience in solving real-world interdisciplinary challenges.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}