 NEWSLETTER
NEWSLETTER
Large language models (LLMs) are essential for solving complex problems in the domains of language processing, mathematics, and reasoning. Improvements in computational techniques focus on allowing LLMs to process data more effectively, generating more accurate and contextually relevant responses. As these models become complex, researchers strive to develop methods to operate within fixed computational budgets without sacrificing performance.
A major challenge in optimizing LLMs is their inability to reason effectively across multiple tasks or perform computations beyond their pretrained architecture. Current methods to improve model performance involve generating intermediate steps during task processing, often at the cost of increased latency and computational inefficiency. This limitation hinders their ability to perform complex reasoning tasks, particularly those that require longer dependencies or greater accuracy in predictions.
Researchers have explored methods such as chain-of-thought (CoT) prompts, which guide LLMs to reason step by step. While effective in some cases, CoT relies on sequential processing of intermediate reasoning steps, leading to slower calculation times. KV cache compression has also been proposed to reduce memory usage, but does little to improve reasoning capabilities. These approaches, while valuable, underscore the need for a method that combines efficiency with greater reasoning ability.
Google DeepMind researchers have introduced a method called differentiable cache augmentation. This technique uses a trained coprocessor to augment the LLM's key-value (kv) cache with latent embeddings, enriching the model's internal memory. The key innovation lies in keeping the base LLM frozen while the coprocessor, which operates asynchronously, is trained. The researchers designed this method to improve reasoning abilities without increasing the computational load during task execution.
The methodology revolves around a three-stage process. First, the frozen LLM generates a kv-cache from an input sequence, encapsulating its internal representation. This kv-cache is passed to the coprocessor, which processes it with additional trainable software tokens. These tokens, which are not linked to specific words, act as abstract cues to generate latent embeddings. Once processed, the augmented kv-cache is returned to the LLM, allowing it to generate contextually rich results. This asynchronous operation ensures that coprocessor enhancements are applied efficiently without delaying core LLM functions. Training the coprocessor is carried out using language loss modeling, focusing solely on its parameters while preserving the integrity of the frozen LLM. This specific approach allows for scalable and efficient optimization.
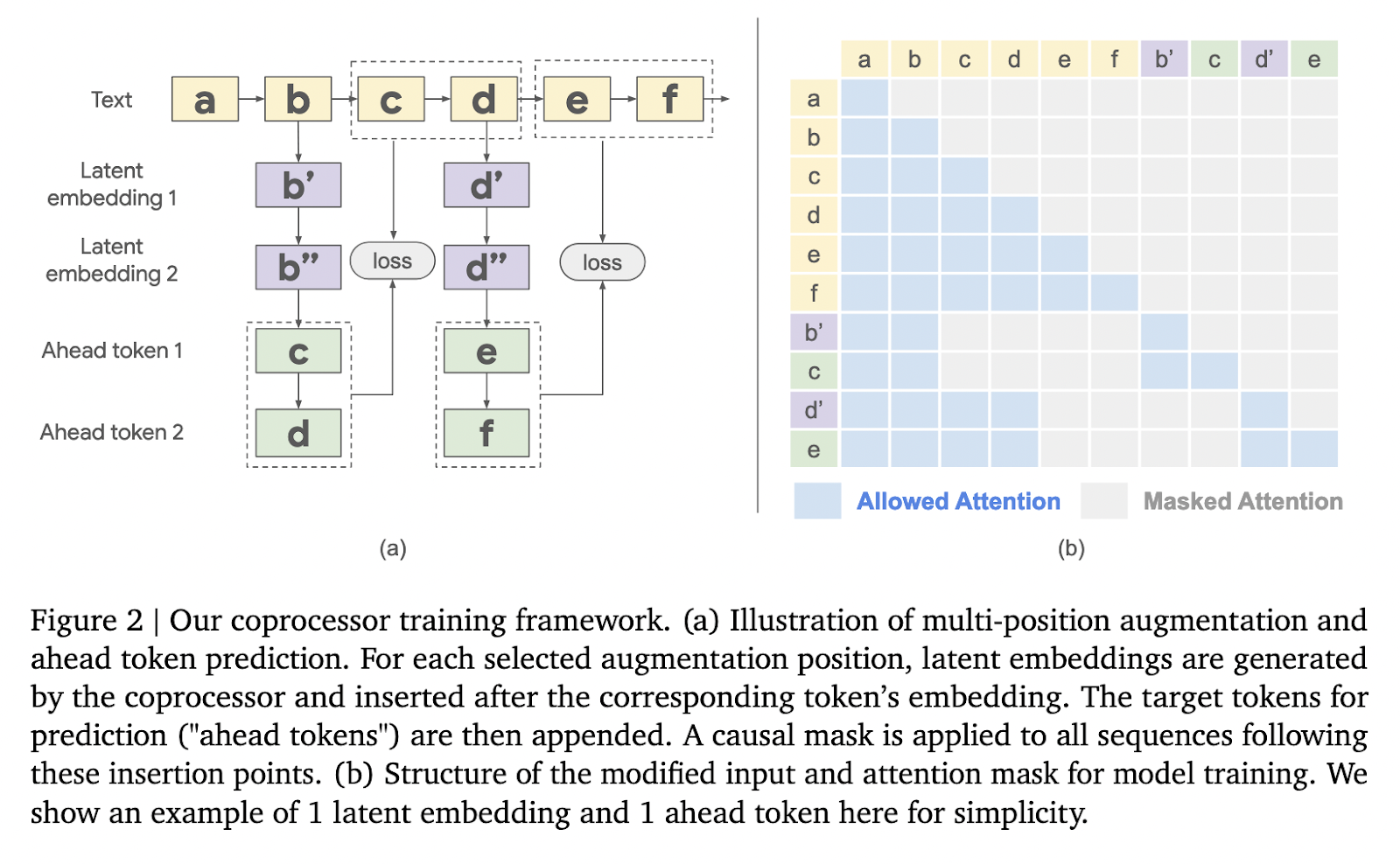
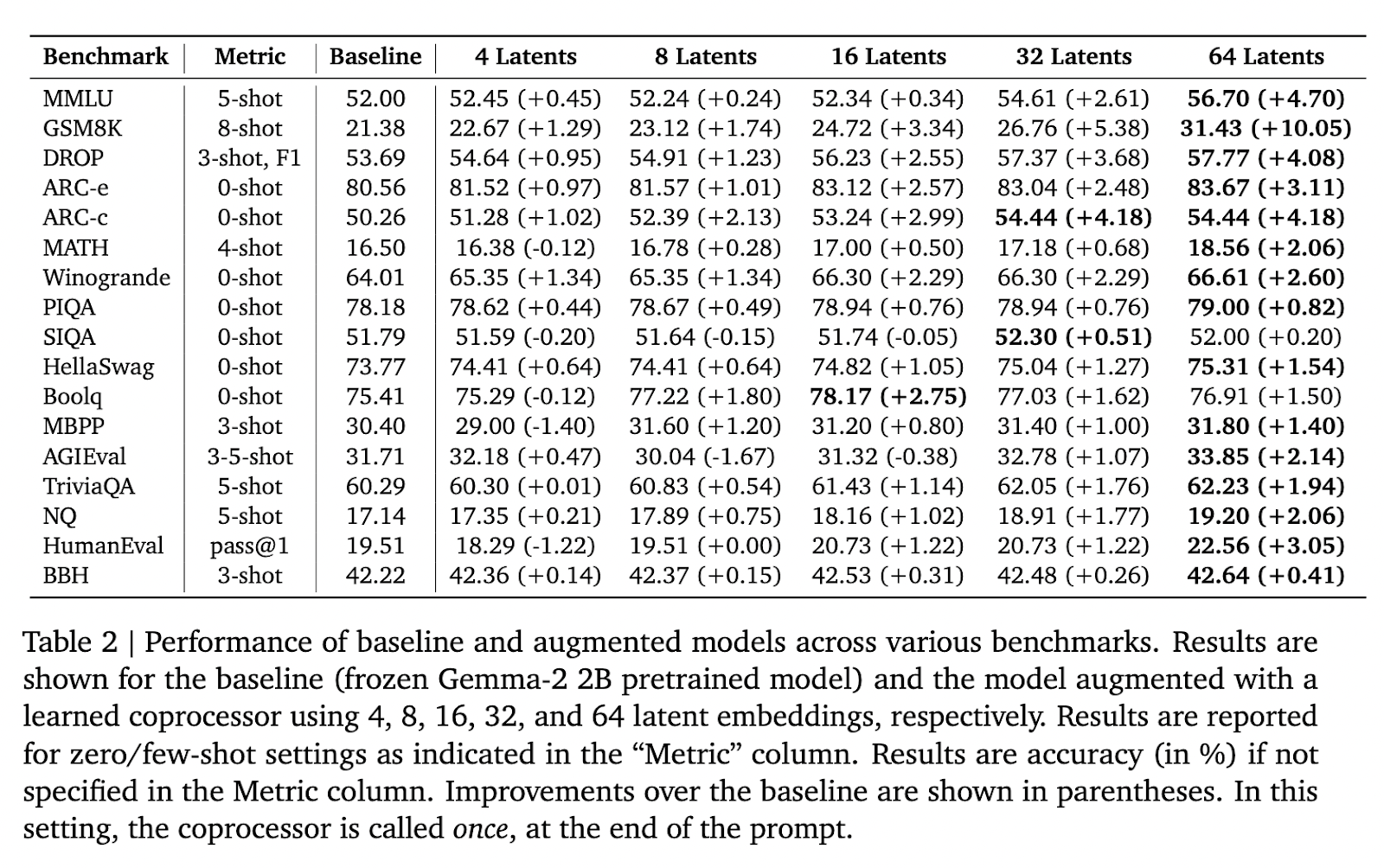
Performance evaluations demonstrated significant improvements. The method was tested on the Gemma-2 2B model and achieved considerable results on several benchmarks. For example, on the intensive reasoning GSM8K dataset, accuracy improved by 10.05% when using 64 latent embeddings. Similarly, the performance of MMLU increased by 4.70% with the same configuration. These improvements underscore the model's ability to perform better on complex reasoning tasks. Furthermore, reductions in perplexity were observed in multiple symbolic positions. For example, perplexity decreased by 3.94% at position one and 1.20% at position 32 when 64 latent embeddings were applied, showing the improved prediction capabilities of the model on longer sequences.
Further analysis showed that the effectiveness of augmentation increases with the number of latent embeddings. For GSM8K, the accuracy gradually increased with additional embeddings, from 1.29% with four embeddings to the maximum improvement of 10.05% with 64 embeddings. Similar trends were observed in other benchmarks such as ARC and MATH, indicating the broader applicability of this method. The researchers confirmed that their approach consistently outperformed baseline models without task-specific adjustments, demonstrating its robustness and adaptability.
This work represents an important step forward in improving the reasoning capabilities of LLMs. By introducing an external coprocessor to augment the kv cache, Google DeepMind researchers have created a method that improves performance while maintaining computational efficiency. The results highlight the potential of LLMs to address more complex tasks, paving the way for further exploration of modular improvements and scalable reasoning systems. This advancement underscores the importance of continued innovation in ai to meet the growing demands for reasoning-intensive applications.
Verify he Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 60,000 ml.
Trending: LG ai Research launches EXAONE 3.5 – three frontier-level bilingual open-source ai models that deliver unmatched instruction following and broad context understanding for global leadership in generative ai excellence….
Nikhil is an internal consultant at Marktechpost. He is pursuing an integrated double degree in Materials at the Indian Institute of technology Kharagpur. Nikhil is an ai/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in materials science, he is exploring new advances and creating opportunities to contribute.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}