 NEWSLETTER
NEWSLETTER
Large language models (LLMs) are increasingly used in domains that require complex reasoning, such as mathematical problem solving and coding. These models can generate accurate results in a number of domains. However, a crucial aspect of their development is their ability to self-correct errors without external intervention – intrinsic self-correction. Many LLMs, despite knowing what is needed to solve complex problems, fail to accurately retrieve or apply it when needed, resulting in incomplete or incorrect answers. The increasing importance of self-correction has led researchers to explore new methods to improve the performance and reliability of LLMs in real-world applications.
One of the main challenges to improving LLMs is their inability to consistently correct their errors. While LLMs can generate partly correct answers, they need assistance in revising incorrect answers when faced with errors. Current models either rely too heavily on prompt-based instructions or fail to dynamically adjust their responses when errors arise. This problem is especially pronounced in tasks requiring multi-step reasoning, where the model’s inability to review and revise previous steps leads to cumulative inaccuracies. To address this problem, researchers are exploring techniques that improve the model’s ability to independently detect and correct its errors, thereby significantly improving performance on tasks involving reasoning and problem solving.
Several methods have been developed to address this problem, but most have significant limitations. Many rely on supervised fine-tuning, where LLMs are trained to follow correction patterns from previous answers. However, this approach often amplifies biases in the original training data, causing the model to make minimal or ineffective corrections. Other techniques, such as using multiple models, employ separate verification models to guide corrections. These methods are computationally expensive and may not be feasible for widespread deployment. Furthermore, they suffer from a mismatch between the training data and the real-world query distribution, leading to suboptimal results when applied in practice. The need for a method that allows LLMs to self-correct without external supervision is becoming increasingly apparent.
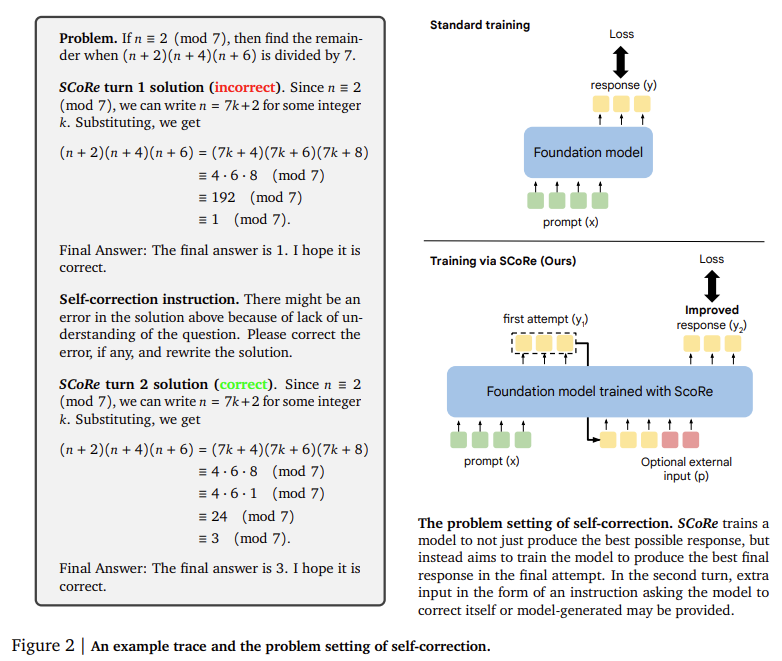
Google DeepMind researchers introduced a new approach called Self-correction through reinforcement learning (SCoRe)This method aims to teach LLMs to improve their responses using self-generated data, eliminating the need for external supervision or model verifiers. By employing multi-turn reinforcement learning (RL), SCoRe allows the model to learn from its responses and fine-tune them in subsequent iterations. This method reduces the reliance on external data and trains the model to handle real-world tasks more effectively by improving self-correction capability. Using this approach, the researchers addressed the common problem of distribution mismatch in training data, making model corrections more robust and effective.
The SCoRe methodology consists of two key stages. In the first stage, the model undergoes initialization training and is optimized to generate an initial correction strategy. This step helps the model develop the ability to make substantial corrections without indulging in minor edits. In the second stage, reinforcement learning is employed to amplify the model’s self-correction capability. This stage focuses on improving the model’s performance in a multi-round environment, where it is rewarded for generating better corrections in subsequent attempts. Including reward modeling in the reinforcement learning process ensures that the model focuses on improving accuracy rather than making minimal changes. The combination of these two stages significantly improves the model’s ability to identify and correct errors, even when faced with complex queries.
The results of the SCoRe method demonstrate a significant improvement in the self-correction performance of LLMs. When applied to the Gemini 1.0 Pro and 1.5 Flash models, SCoRe achieved a 15.6% improvement in self-correction accuracy for mathematical reasoning tasks on the MATH dataset and a 9.1% improvement for coding tasks on the HumanEval dataset. These improvements highlight the effectiveness of the method compared to traditional supervised fine-tuning methods. The model’s accuracy increased to 60.0% on the first attempt and 64.4% on the second attempt, demonstrating its ability to effectively revise its initial response. These results are a significant advancement as existing models typically fail to achieve positive self-correction rates.
Performance metrics also underscore SCoRe’s success in reducing the number of correct answers that were changed to incorrect answers on the second attempt, a common problem in other autocorrect methods. The model improved its correction rate from 4.6% to 5.8% on mathematical reasoning tasks, while also reducing changes from incorrect to correct answers. SCoRe showed similar improvements on encoding tasks, achieving an autocorrect delta of 12.2% on the HumanEval benchmark, underscoring its generalizability across different domains.
In conclusion, the development of SCoRe addresses a long-standing problem in the field of large language models. Researchers have made substantial progress in enabling large language models to effectively self-correct by using reinforcement learning on self-generated data. SCoRe improves accuracy and enhances the model’s ability to handle complex multi-step reasoning tasks. This approach marks a significant shift from previous methods, which relied on external supervision and suffered from data mismatches. The two-stage training process and reward shaping provide a robust framework for improving the self-correction capabilities of large language models, making them more reliable for practical applications.
Take a look at the PaperAll credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram Channel and LinkedIn GrAbove!. If you like our work, you will love our fact sheet..
Don't forget to join our SubReddit of over 50,000 ml
FREE ai WEBINAR: 'SAM 2 for Video: How to Optimize Your Data' (Wednesday, September 25, 4:00 am – 4:45 am EST)
Nikhil is a Consultant Intern at Marktechpost. He is pursuing an integrated dual degree in Materials from Indian Institute of technology, Kharagpur. Nikhil is an ai and Machine Learning enthusiast who is always researching applications in fields like Biomaterials and Biomedical Science. With a strong background in Materials Science, he is exploring new advancements and creating opportunities to contribute.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}