
Large language models (LLMs) have gained significant traction across various domains, revolutionizing applications from conversational agents to content generation. These models demonstrate exceptional capabilities to understand and produce human-like text, enabling sophisticated applications in diverse fields. However, implementing LLMs requires robust mechanisms to ensure safe and responsible user interactions. Current practices often employ content moderation solutions such as LlamaGuard, WildGuard, and AEGIS to filter LLM inputs and outputs for potential security risks. Despite providing initial safeguards, these tools face limitations. They often lack granular predictions of harm types or offer only binary outcomes instead of probabilities, restricting custom harm filtering or threshold adjustments. Furthermore, most solutions provide fixed-size models, which may not align with specific implementation needs. With that, the absence of detailed instructions for building training data hinders the development of models that are robust against adversarial indications and fair across identity groups.
Researchers have made significant progress in content moderation, particularly for human-generated content on online platforms. Tools such as the Perspective API have been instrumental in detecting toxic language. However, these resources are often insufficient when applied to the unique context of human prompts and LLM-generated responses. Recent advances in LLM content moderation have emerged through fine-tuning approaches, as seen in models such as Llama-Guard, Aegis, MD-Judge, and WildGuard.
The development of robust security models depends on high-quality data. While human-computer interaction data is abundant, its direct use presents challenges due to limited positive examples, lack of adversarial and diverse data, and privacy concerns. LLMs, using their vast prior knowledge, have demonstrated exceptional capabilities in generating synthetic data aligned with human requirements. In the security domain, this approach enables the creation of diverse and highly adversarial indications that can effectively test and improve LLMs’ security mechanisms.
Safety policies play a crucial role in deploying ai systems in real-world scenarios. These policies provide guidelines on acceptable content in both user inputs and model outputs. They serve a dual purpose: to ensure consistency between human annotators and to facilitate the development of zero-shot/low-shot classifiers as out-of-the-box solutions. While the categories of disallowed content are largely consistent for both inputs and outputs, the emphasis differs. Input policies focus on prohibiting harmful requests or attempts to obtain harmful content, while output policies primarily aim to prevent the generation of any harmful content.
Google researchers present Gemma Shielda spectrum of content moderation models ranging from 2B to 27B parameters, built on top of Gemma2. These models filter both user input and model output for key harm types, adapting to varying application needs. The innovation lies in a novel methodology for generating high-quality, adversarial, diverse, and fair datasets using synthetic data generation techniques. This approach reduces human annotation effort and has broad applicability beyond security-related challenges. By combining scalable architectures with advanced data generation, ShieldGemma addresses the limitations of existing solutions, offering more nuanced and adaptable content filtering across different deployment scenarios.
ShieldGemma presents a comprehensive approach to content moderation based on the Gemma2 framework. The method defines a detailed content safety taxonomy for six types of harms: sexually explicit information, hate speech, dangerous content, harassment, violence, and obscenity and profanity. This taxonomy guides the model's decision-making process for both user input scenarios and model output scenarios.
The core innovation lies in the synthetic data curation process. This process starts with generating raw data using AART (Automated Adversarial Red Teaming) to create diverse and adversarial cues. The data is then augmented by a generation and self-criticization framework, which improves semantic and syntactic diversity. The dataset is further augmented with Anthropic HH-RLHF examples to increase variety.
To optimize the training process, ShieldGemma employs a cluster margin algorithm for data subsampling, balancing uncertainty and diversity. The selected data undergoes human annotation, with fairness expansion applied to improve representation across multiple identity categories. Finally, the model is fine-tuned using supervised learning on Gemma2 Instruction-Tuned models of varying sizes (parameters 2B, 9B, and 27B).
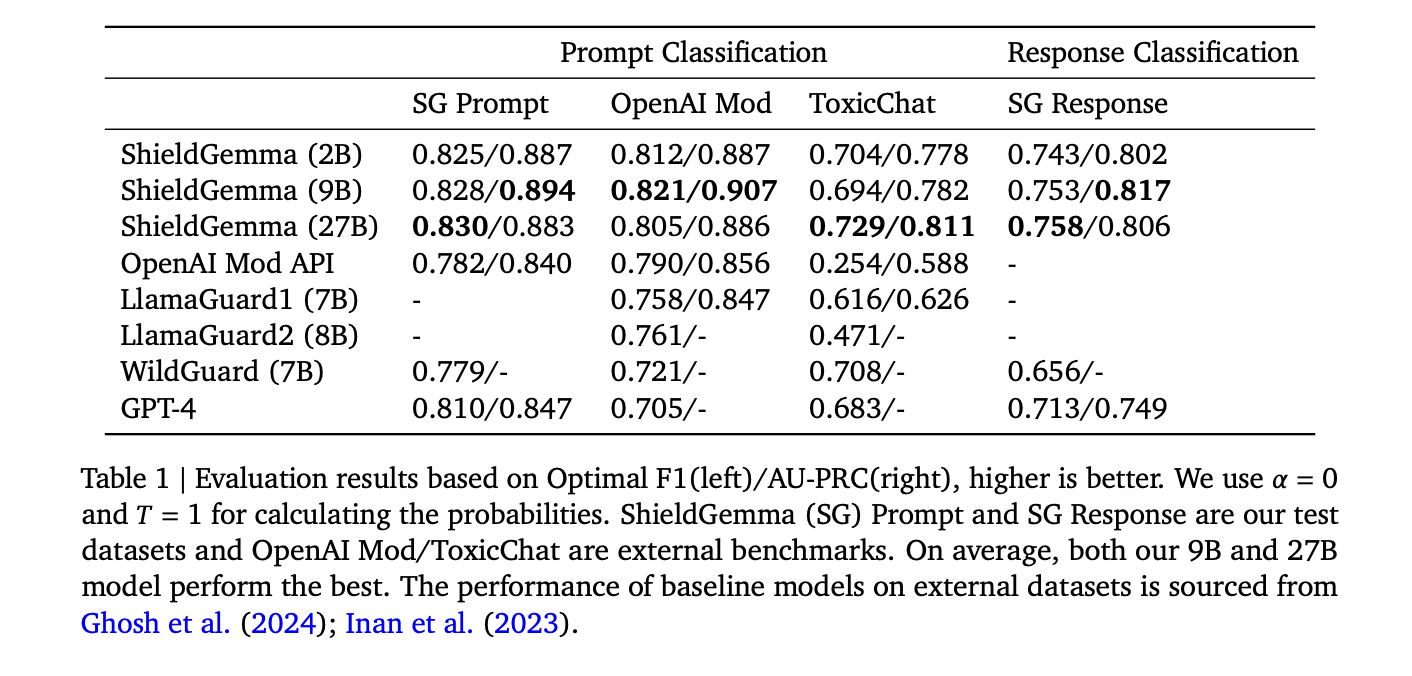
ShieldGemma (SG) models demonstrate superior performance on binary classification tasks across all sizes (parameters 2B, 9B, and 27B) compared to the baseline models. The SG-9B model, in particular, achieves 10.8% higher average AU-PRC on external benchmarks than LlamaGuard1, despite having a similar model size and training data volume. Furthermore, the F1 score of the 9B model outperforms WildGuard and GPT-4 by 4.3% and 6.4%, respectively. Within the ShieldGemma family, performance is consistent on internal benchmarks. However, on external benchmarks, the 9B and 27B models show slightly better generalization ability, with 1.2% and 1.7% higher average AU-PRC scores than the 2B model, respectively. These results highlight the effectiveness of ShieldGemma on content moderation tasks across various model sizes.
ShieldGemma marks a significant advancement in security content moderation for large language models. This set of models (parameters 2B to 27B) built on Gemma2 demonstrates superior performance across a variety of benchmarks. The key innovation lies in its novel synthetic data generation process, which produces high-quality and diverse datasets while minimizing human annotation. This methodology extends beyond security applications and potentially benefits several ai development domains. By outperforming existing baselines and offering flexible deployment options, ShieldGemma improves the security and reliability of LLM interactions. Sharing these resources with the research community aims to accelerate progress in ai safety and responsible deployment.
Review the Paper and HF model card. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram Channel and LinkedIn GrAbove!. If you like our work, you will love our Newsletter..
Don't forget to join our Over 47,000 ML subscribers on Reddit
Find upcoming ai webinars here
Asjad is a consultant intern at Marktechpost. He is pursuing Bachelors in Mechanical Engineering from Indian Institute of technology, Kharagpur. Asjad is a Machine Learning and Deep Learning enthusiast who is always researching the applications of Machine Learning in the healthcare domain.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>





{kind=link}