
Large language models (LLMs) are critical to advancing natural language processing tasks due to their deep understanding and generation capabilities. These models are constantly refined to better understand and execute complex instructions in various applications. Despite significant progress in this field, a problem remains: LLMs often produce results that only partially conform to the instructions given. This misalignment can lead to inefficiencies, especially when models are applied to specialized tasks that require high precision.
Existing research includes fitting LLMs with human-annotated data, as demonstrated by models such as GPT-4. Frameworks like WizardLM and its advanced iteration, WizardLM+, improve the complexity of instructions to improve model training. The studies by Zhao et al. and Zhou et al. assert the importance of instructional complexity in model alignment. Furthermore, Schick and Schütze advocate automating synthetic data generation, taking advantage of the in-context learning capabilities of LLMs. Knowledge distillation techniques, introduced by Hinton et al., also help refine LLMs for specific instructional tasks.
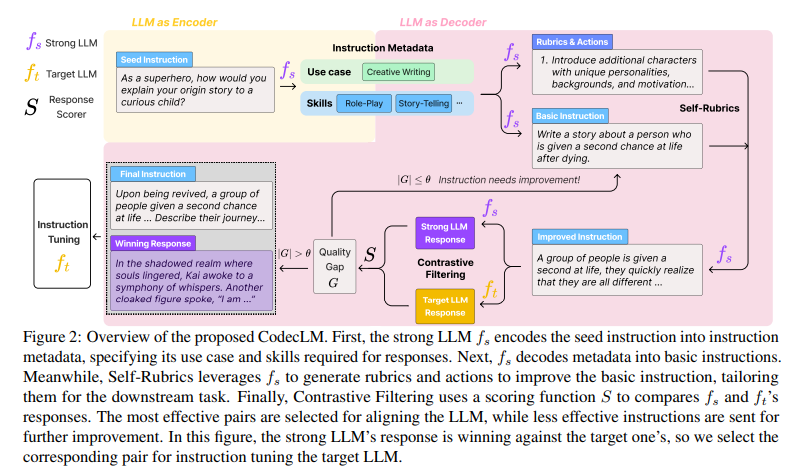
Google Cloud ai researchers have developed CodecLM, an innovative framework designed to align LLMs with specific user instructions by generating custom synthetic data. CodecLM distinguishes itself by using an encoding-decoding mechanism to produce highly personalized instruction data, ensuring that LLMs perform optimally on various tasks. This methodology leverages self-rubric and contrastive filtering techniques, improving the relevance and quality of synthetic instructions and significantly improving the models' ability to follow complex instructions accurately.
CodecLM employs an encode-decode approach, transforming initial instructions into concise metadata that captures the essential characteristics of the instructions. This metadata then guides the generation of synthetic instructions tailored to specific user tasks. To improve the quality and relevance of instruction, the framework uses self-rubrics to add complexity and specificity and contrastive filtering to select the most effective instruction-response pairs based on performance metrics. The effectiveness of CodecLM is validated on several open-domain instruction-following benchmarks, demonstrating significant improvements in LLM alignment compared to traditional methods without relying on extensive manual data annotation.
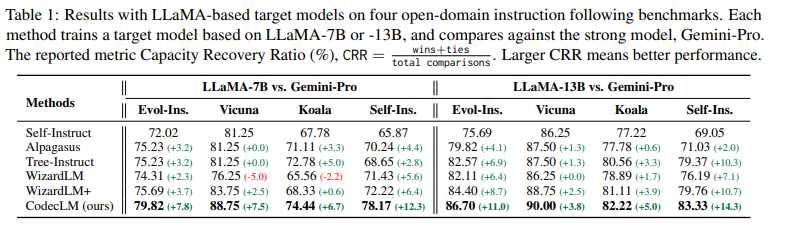
CodecLM's performance was rigorously evaluated across several benchmarks. In the Vicuña benchmark, CodecLM recorded a Capacity Recovery Ratio (CRR) of 88.75%, a 12.5% improvement over its closest competitor. The Self-Instruct benchmark achieved a CRR of 82.22%, which is a 15.2% increase over the closest competing model. These figures confirm the effectiveness of CodecLM in improving the ability of LLMs to follow complex instructions with greater precision and alignment with specific user tasks.
In conclusion, CodecLM represents a significant advance in aligning LLMs with specific user instructions by generating custom synthetic data. By leveraging an innovative encoding and decoding approach, enhanced by autorubrics and contrastive filtering, CodecLM significantly improves the accuracy of LLMs that follow complex instructions. This improvement in LLM performance has practical implications, offering a scalable and efficient alternative to traditional, labor-intensive LLM training methods and improving the models' ability to align with specific user tasks.
Review the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter. Join our Telegram channel, Discord channeland LinkedIn Grabove.
If you like our work, you will love our Newsletter..
Don't forget to join our SubReddit over 40,000ml
Do you want to be in front of 1.5 million ai audiences? Work with us here
![]()
Nikhil is an internal consultant at Marktechpost. He is pursuing an integrated double degree in Materials at the Indian Institute of technology Kharagpur. Nikhil is an ai/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in materials science, he is exploring new advances and creating opportunities to contribute.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>





{kind=link}