 NEWSLETTER
NEWSLETTER
Cardinality estimation (CE) is crucial for optimizing query performance in relational databases. It involves predicting the number of intermediate results that a database query will return, which directly influences the choice of execution plans by query optimizers. Accurate cardinality estimates are essential for selecting efficient join orders, determining whether to use an index, and choosing the best join method. These decisions significantly impact query execution times and overall database performance. Inaccurate estimates can lead to poor execution plans, resulting in significantly slower performance, sometimes by several orders of magnitude. This makes CE a fundamental aspect of database management, with extensive research devoted to improving its accuracy and efficiency.
However, the challenge lies in the limitations of current methods for cardinality estimation. Traditional CE techniques, widely used in modern database systems, rely on heuristics and simplified models, such as the assumption of data uniformity and column independence. While computationally efficient, these methods often need to accurately predict cardinalities, especially in complex queries involving multiple tables and filters. Learned CE models have emerged as a promising alternative, offering better accuracy by leveraging data-driven approaches. However, these models must overcome significant barriers to adoption in practical settings. High training costs, the need for large data sets, and a systematic benchmark to evaluate the performance of these models on diverse databases have hampered their widespread use.
Existing methods, including traditional heuristic-based approaches, have been supplemented with learned models that use instance-specific features of the data. These learned models can improve accuracy, but often at the cost of extensive training requirements. For example, workload-driven approaches require running tens of thousands of queries to collect true cardinalities for training, incurring significant computational costs. More recent data-driven methods attempt to model the distribution of data within and across tables without running queries, which reduces some costs but still requires retraining as the data changes. Despite these advances, the lack of a comprehensive benchmark has made it difficult to compare different models and evaluate their generalization across multiple datasets.
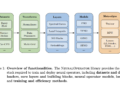
Google Inc. researchers have presented Bank of cardsCardBench is a benchmark designed to address the need for a systematic evaluation framework for learned cardinality estimation models. CardBench is a comprehensive benchmark that includes thousands of queries across 20 distinct real-world databases, significantly more than any previous benchmark. This allows for a more thorough evaluation of learned CE models under a variety of conditions. The benchmark supports three key configurations: instance-based models, which are trained on a single dataset; zero-shot models, which are pre-trained on multiple datasets and then tested on an unseen dataset; and fine-tuned models, which are pre-trained and then fine-tuned on a small amount of data from the target dataset.
CardBench’s design includes tools to calculate the necessary data statistics, generate realistic SQL queries, and create annotated query graphs to train CE models. The benchmark offers two training datasets: one for single-table queries with multiple filter predicates and one for binary join queries involving two tables. The benchmark includes 9,125 single-table queries and 8,454 binary join queries for one of its smaller datasets, ensuring a robust and challenging environment for model evaluation. The training data labels, derived from Google BigQuery, required seven years of CPU query execution time, highlighting the significant computational investment in creating this benchmark. By providing these datasets and tools, CardBench lowers the barrier for researchers interested in developing and testing new CE models.
Performance evaluations performed using CardBench show promising results, particularly for the fine-tuned models. While zero-shot models struggle with accuracy when applied to unseen datasets, especially on complex queries involving joins, the fine-tuned models achieve accuracy comparable to instance-based methods with much less training data. For example, the fine-tuned graph neural network (GNN) models achieved a median q error of 1.32 and a 95th percentile q error of 120 on binary join queries, significantly outperforming the zero-shot models. The results suggest that fine-tuning the pre-trained models can substantially improve their performance even with 500 queries. This makes them viable for practical applications where training data may be limited.
In conclusion, CardBench represents a significant advancement in learned cardinality estimation. Researchers can systematically evaluate and compare different CE models by providing a comprehensive and diverse benchmark, fostering further innovation in this critical area. The benchmark’s ability to support fine-tuned models, which require less data and training time, offers a practical solution for real-world applications where the cost of training new models can be prohibitive.
Take a look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram Channel and LinkedIn GrAbove!. If you like our work, you will love our fact sheet..
Don't forget to join our SubReddit of over 50,000 ml
Below is a highly recommended webinar from our sponsor: ai/webinar-nvidia-nims-and-haystack?utm_campaign=2409-campaign-nvidia-nims-and-haystack-&utm_source=marktechpost&utm_medium=banner-ad-desktop” target=”_blank” rel=”noreferrer noopener”>'Developing High-Performance ai Applications with NVIDIA NIM and Haystack'
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary engineer and entrepreneur, Asif is committed to harnessing the potential of ai for social good. His most recent initiative is the launch of an ai media platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easily understandable to a wide audience. The platform has over 2 million monthly views, illustrating its popularity among the public.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>





{kind=link}