 NEWSLETTER
NEWSLETTER
En el mundo del comercio minorista en línea, crear descripciones de productos de alta calidad para millones de productos es una tarea crucial, pero que requiere mucho tiempo. El uso del aprendizaje automático (ML) y el procesamiento del lenguaje natural (NLP) para automatizar la generación de descripciones de productos tiene el potencial de ahorrar esfuerzo manual y transformar la forma en que operan las plataformas de comercio electrónico. Una de las principales ventajas de las descripciones de productos de alta calidad es la mejora de la capacidad de búsqueda. Los clientes pueden localizar más fácilmente productos que tienen descripciones correctas, porque permite al motor de búsqueda identificar productos que coinciden no sólo con la categoría general sino también con los atributos específicos mencionados en la descripción del producto. Por ejemplo, un producto que tiene una descripción que incluye palabras como “manga larga” y “cuello de algodón” será devuelto si un consumidor busca una “camisa de algodón de manga larga”. Además, tener descripciones de productos factoides puede aumentar la satisfacción del cliente al permitir una experiencia de compra más personalizada y mejorar los algoritmos para recomendar productos más relevantes a los usuarios, lo que aumenta la probabilidad de que los usuarios realicen una compra.
Con el avance de la IA generativa, podemos utilizar modelos visión-lenguaje (VLM) para predecir atributos del producto directamente a partir de imágenes. Los modelos de subtítulos de imágenes o respuesta visual a preguntas (VQA) previamente entrenados funcionan bien al describir imágenes cotidianas, pero no pueden capturar los matices específicos del dominio de los productos de comercio electrónico necesarios para lograr un rendimiento satisfactorio en todas las categorías de productos. Para resolver este problema, esta publicación le muestra cómo predecir atributos de productos específicos de un dominio a partir de imágenes de productos ajustando un VLM en un conjunto de datos de moda usando amazon SageMaker y luego usando amazon Bedrock para generar descripciones de productos usando los atributos predichos como entrada. Para que puedas seguirnos, compartimos el código en un repositorio de GitHub.
amazon Bedrock es un servicio totalmente administrado que ofrece una selección de modelos básicos (FM) de alto rendimiento de empresas líderes en inteligencia artificial como AI21 Labs, Anthropic, Cohere, Meta, Stability ai y amazon a través de una única API, junto con un amplio conjunto de capacidades que necesita para crear aplicaciones de IA generativa con seguridad, privacidad e IA responsable.
Puede utilizar un servicio administrado, como amazon Rekognition, para predecir los atributos del producto, como se explica en Automatización de la generación de descripciones de productos con amazon Bedrock. Sin embargo, si está intentando extraer características específicas y detalladas de su producto o su dominio (industria), es necesario ajustar un VLM en amazon SageMaker.
Modelos visión-lenguaje
Desde 2021, ha habido un aumento en el interés por los modelos visión-lenguaje (VLM), lo que llevó al lanzamiento de soluciones como Preentrenamiento de lenguaje contrastivo-imagen (ACORTAR) y Bootstrapping Idioma-Imagen Pre-entrenamiento (PUNTO LUMINOSO EN UN RADAR). Cuando se trata de tareas como subtítulos de imágenes, generación de imágenes guiadas por texto y respuesta visual a preguntas, los VLM han demostrado un rendimiento de última generación.
En esta publicación, utilizamos BLIP-2, que se introdujo en BLIP-2: Entrenamiento previo de imágenes y lenguaje de arranque con codificadores de imágenes congeladas y modelos de lenguaje grandes, como nuestro VLM. BLIP-2 consta de tres modelos: un codificador de imágenes tipo CLIP, un Querying Transformer (Q-Former) y un modelo de lenguaje grande (LLM). Usamos un versión de BLIP-2, que contiene Flan-T5-XL como el LLM.
El siguiente diagrama ilustra la descripción general de BLIP-2:
Figura 1: descripción general de BLIP-2
La versión previamente entrenada del modelo BLIP-2 se demostró en Creación de una aplicación de IA generativa de imagen a texto utilizando modelos multimodales en amazon SageMaker y Creación de una solución de moderación de contenido basada en IA generativa en amazon SageMaker JumpStart. En esta publicación, demostramos cómo ajustar BLIP-2 para un caso de uso específico de un dominio.
Descripción general de la solución
El siguiente diagrama ilustra la arquitectura de la solución.
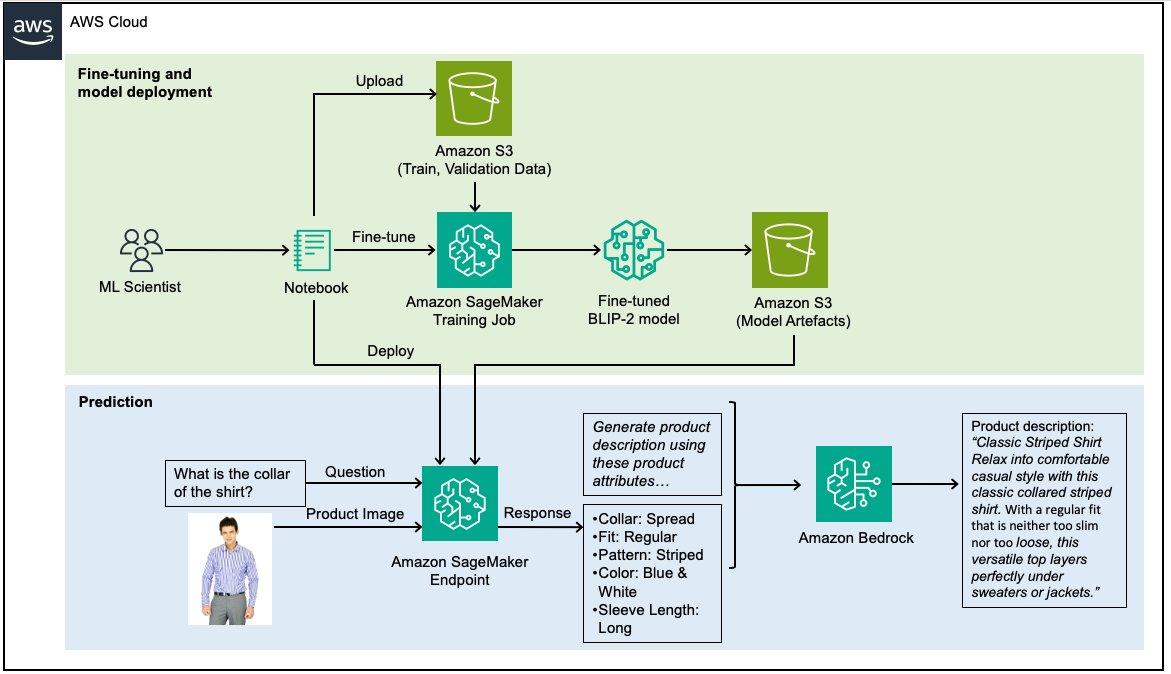
Figura 2: Arquitectura de solución de alto nivel
La descripción general de alto nivel de la solución es:
- Un científico de ML utiliza cuadernos de Sagemaker para procesar y dividir los datos en datos de entrenamiento y validación.
- Los conjuntos de datos se cargan en amazon Simple Storage Service (amazon S3) mediante el cliente S3 (un contenedor de una llamada HTTP).
- Luego, el cliente Sagemaker se utiliza para iniciar un trabajo de capacitación de Sagemaker, nuevamente un contenedor para una llamada HTTP.
- El trabajo de entrenamiento gestiona la copia de los conjuntos de datos de S3 al contenedor de entrenamiento, el entrenamiento del modelo y el guardado de sus artefactos en S3.
- Luego, a través de otra llamada del cliente Sagemaker, se genera un punto final, copiando los artefactos del modelo en el contenedor de alojamiento del punto final.
- Luego, el flujo de trabajo de inferencia se invoca a través de una solicitud de AWS Lambda, que primero realiza una solicitud HTTP al punto final de Sagemaker y luego la utiliza para realizar otra solicitud a amazon Bedrock.
En las siguientes secciones, demostramos cómo:
- Configurar el entorno de desarrollo
- Cargar y preparar el conjunto de datos.
- Ajuste el modelo BLIP-2 para conocer los atributos del producto utilizando SageMaker
- Implemente el modelo BLIP-2 ajustado y prediga los atributos del producto utilizando SageMaker
- Genere descripciones de productos a partir de atributos de producto previstos utilizando amazon Bedrock
Configurar el entorno de desarrollo
Se necesita una cuenta de AWS con un rol de AWS Identity and Access Management (IAM) que tenga permisos para administrar los recursos creados como parte de la solución. Para obtener más información, consulte Creación de una cuenta de AWS.
Usamos amazon SageMaker Studio con el ml.t3.medium instancia y el Data Science 3.0 imagen. Sin embargo, también puede utilizar una instancia de cuaderno de amazon SageMaker o cualquier entorno de desarrollo integrado (IDE) de su elección.
Nota: Asegúrese de configurar correctamente sus credenciales de AWS Command Line Interface (AWS CLI). Para obtener más información, consulte Configurar la AWS CLI.
Se utiliza una instancia ml.g5.2xlarge para trabajos de capacitación de SageMaker y una ml.g5.2xlarge La instancia se utiliza para los puntos finales de SageMaker. Asegúrese de tener suficiente capacidad para esta instancia en su cuenta de AWS solicitando un aumento de cuota si es necesario. Consulte también los precios de las instancias bajo demanda.
Necesitas clonar este repositorio de GitHub por replicar la solución demostrada en esta publicación. Primero, inicie el cuaderno. main.ipynb en SageMaker Studio seleccionando la Imagen como Data Science y núcleo como Python 3. Instale todas las bibliotecas requeridas mencionadas en el requirements.txt.
Cargar y preparar el conjunto de datos.
Para esta publicación utilizamos el Conjunto de datos de imágenes de moda de Kaggle, que contiene 44.000 productos con etiquetas de múltiples categorías, descripciones e imágenes de alta resolución. En esta publicación queremos demostrar cómo perfeccionar un modelo para aprender atributos como la tela, el ajuste, el cuello, el patrón y el largo de la manga de una camisa usando la imagen y una pregunta como entradas.
Cada producto se identifica con un ID como 38642 y hay un mapa de todos los productos en styles.csv. Desde aquí, podemos obtener la imagen de este producto desde images/38642.jpg y los metadatos completos de styles/38642.json. Para ajustar nuestro modelo, necesitamos convertir nuestros ejemplos estructurados en una colección de pares de preguntas y respuestas. Nuestro conjunto de datos final tiene el siguiente formato después del procesamiento para cada atributo:
Id | Question | Answer38642 | What is the fabric of the clothing in this picture? | Fabric: Cotton
Ajuste el modelo BLIP-2 para conocer los atributos del producto utilizando SageMaker
Para iniciar un trabajo de capacitación de SageMaker, necesitamos el Estimador HuggingFace. SageMaker inicia y administra todas las instancias necesarias de amazon Elastic Compute Cloud (amazon EC2) por nosotros, proporciona el contenedor Hugging Face apropiado, carga los scripts especificados y descarga datos de nuestro depósito S3 al contenedor para /opt/ml/input/data.
Afinamos BLIP-2 usando el Adaptación de bajo rango (LoRA), que agrega matrices de descomposición de rangos entrenables a cada capa de estructura de Transformer mientras mantiene los pesos del modelo previamente entrenado en un estado estático. Esta técnica puede aumentar el rendimiento del entrenamiento y reducir la cantidad de RAM de GPU requerida 3 veces y la cantidad de parámetros entrenables 10,000 veces. A pesar de utilizar menos parámetros entrenables, se ha demostrado que LoRA funciona tan bien o mejor que la técnica de ajuste completo.
Nos preparamos entrypoint_vqa_finetuning.py que implementa el ajuste fino de BLIP-2 con la técnica LoRA usando Hugging Face transformadores, Acelerary Ajuste fino eficiente en los parámetros (PEFT). El script también fusiona los pesos de LoRA con los pesos del modelo después del entrenamiento. Como resultado, puede implementar el modelo como un modelo normal sin ningún código adicional.
Podemos comenzar nuestro trabajo de capacitación ejecutando el método .fit() y pasando nuestra ruta de amazon S3 para las imágenes y nuestro archivo de entrada.
Implemente el modelo BLIP-2 ajustado y prediga los atributos del producto utilizando SageMaker
Implementamos el modelo BLIP-2 ajustado en el punto final en tiempo real de SageMaker utilizando el Contenedor de inferencia HuggingFace. También puede utilizar el contenedor de inferencia de modelo grande (LMI), que se describe con más detalle en Creación de una solución de moderación de contenido generativa basada en IA en amazon SageMaker JumpStart, que implementa un modelo BLIP-2 previamente entrenado. Aquí, hacemos referencia a nuestro modelo ajustado en amazon S3 en lugar del modelo previamente entrenado disponible en el centro Hugging Face. Primero creamos el modelo e implementamos el punto final.
Cuando el estado del terminal pasa a ser en serviciopodemos invocar el punto final para la tarea de generación de visión a lenguaje instruida con una imagen de entrada y una pregunta como mensaje:
La respuesta de salida se parece a la siguiente:
{"Sleeve Length": "Long Sleeves"}
Genere descripciones de productos a partir de atributos de producto previstos utilizando amazon Bedrock
Para comenzar con amazon Bedrock, solicite acceso a los modelos fundamentales (no están habilitados de forma predeterminada). Puede seguir los pasos de la documentación para habilitar el acceso al modelo. En esta publicación, utilizamos Claude de Anthropic en amazon Bedrock para generar descripciones de productos. Específicamente utilizamos el modelo anthropic.claude-3-sonnet-20240229-v1 porque proporciona buen rendimiento y velocidad.
Después de crear el cliente boto3 para amazon Bedrock, creamos una cadena de mensaje que especifica que queremos generar descripciones de productos utilizando los atributos del producto.
You are an expert in writing product descriptions for shirts. Use the data below to create product description for a website. The product description should contain all given attributes.Provide some inspirational sentences, for example, how the fabric moves. Think about what a potential customer wants to know about the shirts. Here are the facts you need to create the product descriptions: (Here we insert the predicted attributes by the BLIP-2 model)
Los parámetros del modelo y del mensaje, incluido el número máximo de tokens utilizados en la respuesta y la temperatura, se pasan al cuerpo. La respuesta JSON debe analizarse antes de que el texto resultante se imprima en la línea final.
La respuesta de descripción del producto generada se parece a la siguiente:
"Classic Striped Shirt Relax into comfortable casual style with this classic collared striped shirt. With a regular fit that is neither too slim nor too loose, this versatile top layers perfectly under sweaters or jackets."
Conclusión
Le mostramos cómo la combinación de VLM en SageMaker y LLM en amazon Bedrock presenta una solución poderosa para automatizar la generación de descripciones de productos de moda. Al ajustar el modelo BLIP-2 en un conjunto de datos de moda mediante amazon SageMaker, puede predecir atributos de producto matizados y específicos del dominio directamente a partir de imágenes. Luego, utilizando las capacidades de amazon Bedrock, puede generar descripciones de productos a partir de los atributos de producto previstos, mejorando la capacidad de búsqueda y la personalización de las plataformas de comercio electrónico. A medida que continuamos explorando el potencial de la IA generativa, los LLM y VLM emergen como una vía prometedora para revolucionar la generación de contenido en el panorama en constante evolución del comercio minorista en línea. Como siguiente paso, puede intentar ajustar este modelo en su propio conjunto de datos utilizando el código proporcionado en el repositorio de GitHub para probar y comparar los resultados para sus casos de uso.
Sobre los autores
 Antonia Wiebeler es científica de datos en el Centro de innovación de IA generativa de AWS, donde le gusta crear pruebas de concepto para los clientes. Su pasión es explorar cómo la IA generativa puede resolver problemas del mundo real y crear valor para los clientes. Si bien no codifica, le gusta correr y competir en triatlones.
Antonia Wiebeler es científica de datos en el Centro de innovación de IA generativa de AWS, donde le gusta crear pruebas de concepto para los clientes. Su pasión es explorar cómo la IA generativa puede resolver problemas del mundo real y crear valor para los clientes. Si bien no codifica, le gusta correr y competir en triatlones.
 Daniel Zagyvá es científico de datos en AWS Professional Services. Se especializa en el desarrollo de soluciones de aprendizaje automático escalables y de nivel de producción para clientes de AWS. Su experiencia se extiende a diferentes áreas, incluido el procesamiento del lenguaje natural, la inteligencia artificial generativa y las operaciones de aprendizaje automático.
Daniel Zagyvá es científico de datos en AWS Professional Services. Se especializa en el desarrollo de soluciones de aprendizaje automático escalables y de nivel de producción para clientes de AWS. Su experiencia se extiende a diferentes áreas, incluido el procesamiento del lenguaje natural, la inteligencia artificial generativa y las operaciones de aprendizaje automático.
 Lun Yeh es ingeniero de aprendizaje automático en AWS Professional Services. Se especializa en PNL, pronósticos, MLOps e inteligencia artificial generativa y ayuda a los clientes a adoptar el aprendizaje automático en sus negocios. Se graduó en la TU Delft con una licenciatura en ciencia y tecnología de datos.
Lun Yeh es ingeniero de aprendizaje automático en AWS Professional Services. Se especializa en PNL, pronósticos, MLOps e inteligencia artificial generativa y ayuda a los clientes a adoptar el aprendizaje automático en sus negocios. Se graduó en la TU Delft con una licenciatura en ciencia y tecnología de datos.
 Fotinos Kyriakides es consultor de IA/ML en AWS Professional Services y se especializa en el desarrollo de plataformas y soluciones de ML listas para producción para clientes de AWS. En su tiempo libre, a Fotinos le gusta correr y explorar.
Fotinos Kyriakides es consultor de IA/ML en AWS Professional Services y se especializa en el desarrollo de plataformas y soluciones de ML listas para producción para clientes de AWS. En su tiempo libre, a Fotinos le gusta correr y explorar.






{kind=link}