 NEWSLETTER
NEWSLETTER
Popularidad del trapo
En los últimos dos años mientras trabajaba con firmas financieras, he observado de primera mano cómo identifican y priorizan los casos generativos de uso de IA, equilibrando la complejidad con el valor potencial.
Generación de recuperación de generación (Rag) a menudo se destaca como una capacidad fundamental en muchas soluciones impulsadas por LLM, lo que logró un equilibrio entre la facilidad de implementación y el impacto del mundo real. Combinando un perdiguero que superficie documentos relevantes con un LLM que sintetiza respuestas, trapo Acceso de conocimiento de línea de líneahaciéndolo invaluable para aplicaciones como atención al cliente, investigación y gestión del conocimiento interno.
La definición de los criterios de evaluación claros es clave para garantizar que las soluciones de LLM cumplan con los estándares de rendimiento, al igual que el desarrollo basado en pruebas (TDD) garantiza la confiabilidad en el software tradicional. Dibujo de los principios de TDD, un enfoque basado en la evaluación establece puntos de referencia medibles para validar y mejorar los flujos de trabajo de IA. Esto se vuelve especialmente importante para los LLM, donde la complejidad de las respuestas abiertas exige una evaluación consistente y reflexiva para ofrecer resultados confiables.
Para las aplicaciones RAG, un conjunto de evaluación típico incluye pares de entrada-salida representativos que se alinean con el caso de uso previsto. Por ejemplo, en las aplicaciones de chatbot, esto podría implicar pares de preguntas y respuestas que reflejen las consultas de los usuarios. En otros contextos, como recuperar y resumir el texto relevante, el conjunto de evaluación podría incluir documentos fuente junto con resúmenes esperados o puntos clave extraídos. Estos pares a menudo se generan a partir de un subconjunto de documentos, como los que son más vistos o se acceden con frecuencia, asegurando que la evaluación se centre en el contenido más relevante.
Desafíos clave
La creación de conjuntos de datos de evaluación para sistemas RAG ha enfrentado tradicionalmente dos desafíos principales.
- El proceso a menudo se basaba en expertos en la materia (PYME) para revisar manualmente los documentos y generar pares de preguntas y respuestas, lo que lo hace. intensivo en el tiempo, inconsistente y costoso.
- Limitaciones que evitan que los LLM procesen elementos visuales dentro de documentos, como tablas o diagramas, ya que están restringidos al manejo del texto. Las herramientas de OCR estándar luchan para cerrar esta brechaa menudo no extrae información significativa del contenido no textual.
Capacidades multimodales
Los desafíos del manejo de documentos complejos han evolucionado con la introducción de capacidades multimodales en los modelos fundamentales. Los modelos comerciales y de código abierto ahora pueden Procesar el texto y el contenido visual. Esta capacidad de visión elimina la necesidad de flujos de trabajo de extracción de texto separados, ofreciendo un enfoque integrado para manejar PDF de medios mixtos.
Al aprovechar estas características de visión, Los modelos pueden ingerir páginas completas a la vez, reconociendo estructuras de diseño, etiquetas de gráficos y contenido de mesa. Esto no solo reduce el esfuerzo manual, sino que también mejora la escalabilidad y la calidad de los datos, lo que lo convierte en un poderoso facilitador para los flujos de trabajo de RAG que dependen de información precisa de una variedad de fuentes.
Curación del conjunto de datos para el informe de investigación de gestión de patrimonio
Para demostrar una solución al problema de la generación del conjunto de evaluación manual, probé mi enfoque usando un documento de muestra: el informe 2023 Cerulli. Este tipo de documento es típico en la gestión de patrimonio, donde los informes de estilo analista a menudo combinan texto con imágenes complejas. Para un asistente de búsqueda con trapo, un corpus de conocimiento como este probablemente contendría muchos de estos documentos.
Mi objetivo era Demuestre cómo se podría aprovechar un solo documento para generar pares de preguntas y respuestas, incorporando elementos de texto y visuales. Si bien no definí dimensiones específicas para los pares de preguntas y respuestas en esta prueba, una implementación del mundo real implicaría proporcionar detalles sobre tipos de preguntas (comparativo, análisis, opción múltiple), temas (estrategias de inversión, tipos de cuentas) y muchos otros aspectos. El enfoque principal de este experimento fue garantizar que la LLM generara preguntas que incorporaron elementos visuales y produjeron respuestas confiables.
Mi flujo de trabajo, ilustrado en el diagrama, aprovecha el modelo Claude Sonnet 3.5 de Anthrope, que simplifica el proceso de trabajar con PDF al manejar la conversión de documentos en imágenes antes de pasarlas al modelo. Este La funcionalidad incorporada elimina la necesidad de dependencias de terceros adicionales, racionalización del flujo de trabajo y reduciendo la complejidad del código.
Excluí páginas preliminares del informe como la tabla de contenido y glosario, centrándome en páginas con contenido relevante y gráficos para generar pares de preguntas y respuestas. A continuación se muestra el aviso que usé para generar los conjuntos iniciales de respuesta-respuesta.
You are an expert at analyzing financial reports and generating question-answer pairs. For the provided PDF, the 2023 Cerulli report:1. Analyze pages {start_idx} to {end_idx} and for **each** of those 10 pages:
- Identify the **exact page title** as it appears on that page (e.g., "Exhibit 4.03 Core Market Databank, 2023").
- If the page includes a chart, graph, or diagram, create a question that references that visual element. Otherwise, create a question about the textual content.
- Generate two distinct answers to that question ("answer_1" and "answer_2"), both supported by the page’s content.
- Identify the correct page number as indicated in the bottom left corner of the page.
2. Return exactly 10 results as a valid JSON array (a list of dictionaries). Each dictionary should have the keys: “page” (int), “page_title” (str), “question” (str), “answer_1” (str), and “answer_2” (str). The page title typically includes the word "Exhibit" followed by a number.
Generación de parejas de preguntas y respuestas
Para refinar el proceso de generación de preguntas y respuestas, implementé un enfoque de aprendizaje comparativo Eso genera dos respuestas distintas para cada pregunta. Durante la fase de evaluación, estas respuestas se evalúan en dimensiones clave, como precisión y claridad, con la respuesta más fuerte seleccionada como la respuesta final.
Este enfoque refleja cómo a los humanos a menudo les resulta más fácil tomar decisiones al comparar alternativas en lugar de evaluar algo de forma aislada. Es como un examen ocular: el optometrista no pregunta si su visión ha mejorado o disminuido, sino que presenta dos lentes y pregunta, ¿cuál es más clara, opción 1 u opción 2? Este proceso comparativo Elimina la ambigüedad de evaluar la mejora absoluta y se centra en las diferencias relativashaciendo que la elección sea más simple y más procesable. Del mismo modo, al presentar dos opciones de respuesta concretas, el sistema puede evaluar de manera más efectiva qué respuesta es más fuerte.
Esta metodología también se cita como una mejor práctica en el artículo. “Lo que aprendimos de un año de construcción con LLM” por líderes en el espacio de IA. Destacan el valor de las comparaciones por pares, indicando: “En lugar de pedirle al LLM que obtenga una sola salida en una escala Likert, presente dos opciones y pídale que seleccione la mejor. Esto tiende a conducir a resultados más estables. “ ¡Recomiendo leer su serie de tres partes, ya que proporciona información invaluable sobre la construcción de sistemas efectivos con LLM!
Evaluación de LLM
Para evaluar los pares de preguntas y respuestas generadas, utilicé Claude Opus para sus capacidades de razonamiento avanzado. Actuando como un “juez” El LLM comparó las dos respuestas generadas para cada pregunta y seleccionó la mejor opción basada en criterios como la franqueza y la claridad. Este enfoque está respaldado por una extensa investigación (Zheng et al., 2023) que muestra que los LLM pueden realizar evaluaciones a la par con los revisores humanos.
Este enfoque reduce significativamente la cantidad de revisión manual requerida por las PYMEhabilitando un proceso de refinamiento más escalable y eficiente. Si bien las PYME siguen siendo esenciales durante las etapas iniciales para verificar las preguntas y validar las salidas del sistema, esta dependencia disminuye con el tiempo. Una vez que se establece un nivel suficiente de confianza en el rendimiento del sistema, se reduce la necesidad de verificación de manchas frecuente, lo que permite que las PYME se centren en tareas de mayor valor.
Lecciones aprendidas
La capacidad PDF de Claude tiene un límite de 100 páginas, por lo que dividí el documento original en cuatro secciones de 50 páginas. Cuando intenté procesar cada sección de 50 páginas en una sola solicitud, e instruí explícitamente el modelo para generar un par de preguntas y respuestas por página, todavía se perdió algunas páginas. El límite de token no era el verdadero problema; El modelo tendía a centrarse en el contenido que considerara más relevante, dejando ciertas páginas subrepresentadas.
Para abordar esto, experimenté con el procesamiento del documento en lotes más pequeños, probando 5, 10 y 20 páginas a la vez. A través de estas pruebas, descubrí que los lotes de 10 páginas (por ejemplo, páginas 1–10, 11-20, etc.) proporcionaron el mejor equilibrio entre precisión y eficiencia. El procesamiento de 10 páginas por lote aseguró resultados consistentes en todas las páginas al tiempo que optimizaba el rendimiento.
Otro desafío fue vincular los pares de preguntas y respuestas a su fuente. El uso de pequeños números de página en el pie de página de un PDF solo no funcionó constantemente. En contraste, los títulos de página o encabezados claros en la parte superior de cada página sirvieron como anclajes confiables. Fueron más fáciles de recoger para el modelo y me ayudaron a asignar con precisión cada par de preguntas y respuestas a la sección correcta.
Salida de ejemplo
A continuación se muestra una página de ejemplo del informe, con dos tablas con datos numéricos. Se generó la siguiente pregunta para esta página:
¿Cómo ha cambiado la distribución de AUM en las empresas de RIA híbridas de diferentes tamaños?
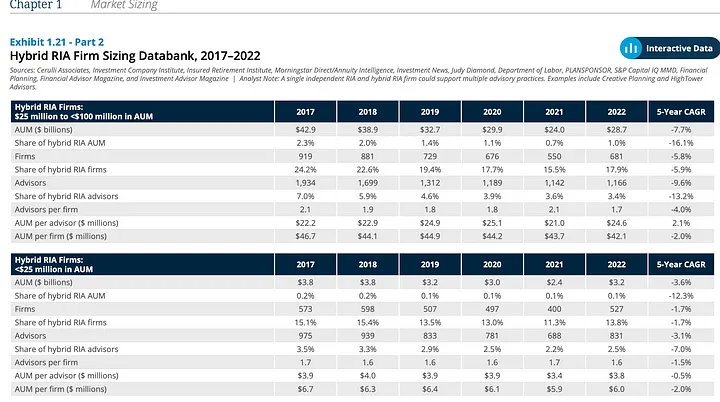
Respuesta: Las empresas medianas ($ 25 millones a <$ 100 millones) experimentaron una disminución en la acción de AUM del 2.3% al 1.0%.
En la primera tabla, la columna 2017 muestra una participación del 2.3% de AUM para las empresas medianas, lo que disminuye a 1.0% en 2022, mostrando así la capacidad de la LLM para sintetizar el contenido visual y tabular con precisión.
Beneficios
La combinación de almacenamiento en caché, un lote y un flujo de trabajo de preguntas y respuestas refinadas condujo a tres ventajas clave:
Almacenamiento en caché
- En mi experimento, procesar un informe singular sin almacenamiento en caché habría costado $ 9, pero al aprovechar el almacenamiento en caché, reduje este costo a $ 3, un 3x ahorro de costos. Según el modelo de precios de Anthrope, la creación de un caché cuesta $ 3.75 / millones de tokens, sin embargo, las lecturas de la memoria caché son solo $ 0.30 / millones de tokens. En contraste, los tokens de entrada cuestan $ 3 / millones de tokens cuando no se usa almacenamiento en caché.
- En un escenario del mundo real con más de un documento, los ahorros se vuelven aún más significativos. Por ejemplo, el procesamiento de 10,000 informes de investigación de longitud similar sin almacenamiento en caché costaría $ 90,000 en costos de insumos solo. Con el almacenamiento en caché, este costo cae a $ 30,000, logrando la misma precisión y calidad mientras se ahorra $ 60,000.
Procesamiento por lotes con descuento
- Utilizando los lotes de Anthrope, los costos de producción de la API de recortes por la mitad, por lo que es una opción mucho más barata para ciertas tareas. Una vez que había validado las indicaciones, ejecuté un solo trabajo por lotes para evaluar todos los conjuntos de respuestas de preguntas y respuestas a la vez. Este método resultó mucho más rentable que procesar cada par de preguntas y respuestas individualmente.
- Por ejemplo, Claude 3 Opus generalmente cuesta $ 15 por millón de tokens de producción. Al usar un lote, esto cae a $ 7.50 por millón de tokens – una reducción del 50%. En mi experimento, cada par de preguntas y respuestas generó un promedio de 100 tokens, lo que resultó en aproximadamente 20,000 tokens de salida para el documento. A la tarifa estándar, esto habría costado $ 0.30. Con el procesamiento por lotes, el costo se redujo a $ 0.15, HighlighTng cómo este enfoque optimiza los costos para tareas no secuenciales como las ejecuciones de evaluación.
Tiempo ahorrado para las PYME
- Con pares de preguntas y respuestas más precisas y ricas en contexto, los expertos en la materia pasaron menos tiempo examinando a través de PDF y aclarar detalles, y más tiempo enfocándose en ideas estratégicas. Este enfoque también elimina la necesidad de contratar personal adicional o asignar recursos internos para curar conjuntos de datos manualmente, un proceso que puede llevar mucho tiempo y costoso. Al automatizar estas tareas, las empresas ahorran significativamente los costos laborales al tiempo que racionalizan los flujos de trabajo de las PYME, lo que hace que esta sea una solución escalable y rentable.






{kind=link}