
Approximate nearest neighbor search (ANNS) is a critical technology that powers several ai-powered applications such as data mining, search engines, and recommendation systems. The main goal of ANNS is to identify the closest vectors to a given query in high-dimensional spaces. This process is essential in contexts where quickly finding similar items is crucial, such as image recognition, natural language processing, and large-scale recommendation engines. However, as data size increases to billions of vectors, ANNS systems face considerable challenges in terms of performance and scalability. Efficient management of these data sets requires significant computational and memory resources, making it a very complex and expensive task.
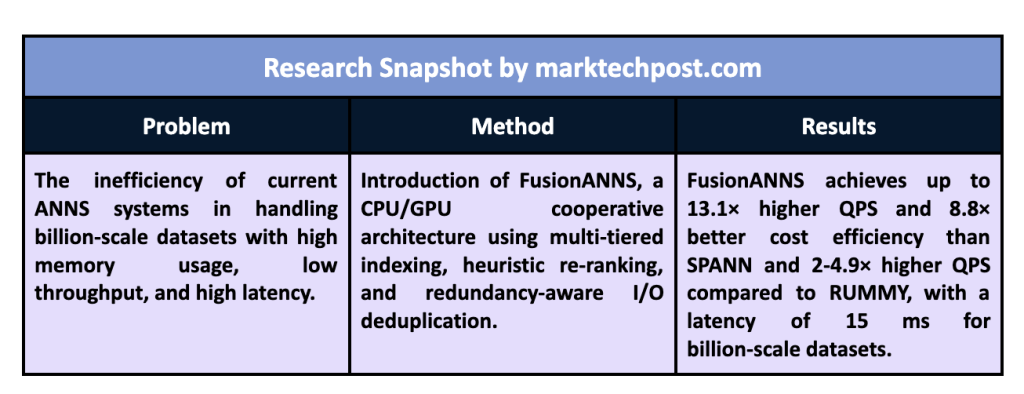
The main problem this research addresses is that existing ANNS solutions often need help to handle the immense scale of modern data sets while maintaining efficiency and accuracy. Traditional approaches are inadequate for billion-scale data because they require high memory usage and computational power. Techniques such as inverted file (IVF) and graph-based indexing methods have been developed to address these limitations. Still, they often require terabyte-scale memory, making them expensive and resource-intensive. Furthermore, the computational complexity of performing massive calculations of distances between high-dimensional vectors on such large data sets is a bottleneck for current ANNS systems.
In the current state of ANNS technology, memory-intensive methods, such as IVF and graph-based indexes, are often employed to structure the search space. While these methods can improve query performance, they also significantly increase memory consumption, particularly for large data sets containing billions of vectors. Hierarchical indexing (HI) and product quantization (PQ) techniques have optimized memory usage by storing indices on SSDs and using compressed representations of vectors. However, these solutions can cause serious performance degradation due to the overhead introduced by data compression and decompression operations, which can lead to accuracy losses. Current systems such as SPANN and RUMMY have demonstrated varying degrees of success, but remain limited by their inability to balance memory consumption and computational efficiency.
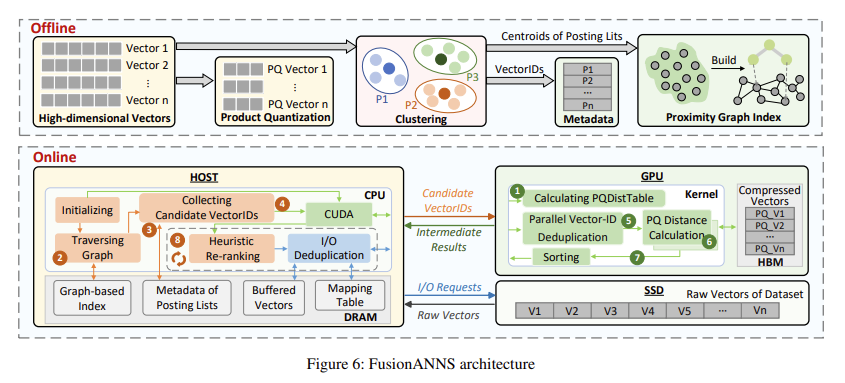
Researchers from Huazhong University of Science and technology and Huawei Technologies Co., Ltd presented FusionANNSa new CPU/GPU collaborative processing architecture designed specifically for billion-scale data sets to address these challenges. FusionANNS uses an innovative multi-level index structure that leverages the strengths of CPUs and GPUs. This architecture enables high-performance, low-latency approximate nearest neighbor searches using a single entry-level GPU, making it a cost-effective solution. The researchers' focus is on three main innovations: multi-level indexing, heuristic reclassification, and redundancy-aware I/O deduplication, which minimize data transmission between CPU, GPU, and SSD to eliminate data bottlenecks. performance.
FusionANNS' multi-level indexing structure enables collaborative CPU/GPU filtering by storing raw vectors on SSD, compressed vectors in GPU high-bandwidth memory (HBM), and vector identifiers in host memory . This structure prevents excessive data exchange between CPU and GPU, significantly reducing I/O operations. Heuristic reclassification further improves query accuracy by dividing the reclassification process into multiple mini-batches and employing a feedback control mechanism to terminate unnecessary calculations early. The final component, redundancy-aware I/O deduplication, groups vectors with high similarity into optimized storage layouts, reducing the number of I/O requests during reclassification by 30% and eliminating I/O operations. S redundant through effective caching strategies.
Experimental results indicate that FusionANNS outperforms state-of-the-art systems such as SPANN and RUMMY in several metrics. The system achieves up to 13.1 times more queries per second (QPS) and 8.8 times better profitability compared to SPANN, and between 2 and 4.9 times more QPS and 6.8 times better profitability compared to RUMMY. For a data set containing 1 billion vectors, FusionANNS can handle the query process with a QPS of over 12,000 while maintaining latency as low as 15 milliseconds. These results demonstrate that FusionANNS is very effective in handling billion-scale data sets without large memory resources.
Key findings from this research include:
- Performance improvement: FusionANNS achieves up to 13.1x higher QPS and 8.8x better cost efficiency than the state-of-the-art SSD-based SPANN system.
- Efficiency gain: Provides 5.7 to 8.8 times greater efficiency in handling SSD-based data access and processing.
- Scalability: FusionANNS can handle data sets at billions of scale using only an entry-level GPU and minimal memory resources.
- Profitability: The system shows a 2 to 4.9 times improvement in cost effectiveness compared to existing in-memory solutions such as RUMMY.
- Latency reduction: FusionANNS maintains a query latency of 15 milliseconds, significantly lower than other SSD-based and GPU-accelerated solutions.
- Innovation in Design: The use of multi-level indexing, heuristic reclassification, and redundancy-aware I/O deduplication are innovative contributions that distinguish FusionANNS from existing methods.
In conclusion, FusionANNS represents a breakthrough in ANNS technology by delivering high throughput, low latency, and superior cost effectiveness. The researchers' novel approach to CPU/GPU collaboration and multi-level indexing offers a practical solution for scaling ANNS to support large data sets. FusionANNS sets a new standard for handling high-dimensional data in real-world applications by reducing memory footprint and eliminating unnecessary computations.
look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet..
Don't forget to join our SubReddit over 50,000ml.
We are inviting startups, companies and research institutions that are working on small language models to participate in this next Magazine/Report 'Small Language Models' by Marketchpost.com. This magazine/report will be published in late October/early November 2024. Click here to schedule a call!
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for social good. Their most recent endeavor is the launch of an ai media platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easily understandable to a wide audience. The platform has more than 2 million monthly visits, which illustrates its popularity among the public.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}