 NEWSLETTER
NEWSLETTER
Large language models (LLMs) have gained significant attention in recent years, but understanding their capabilities and limitations remains a challenge. Researchers are trying to develop methodologies to reason about the strengths and weaknesses of ai systems, particularly LLMs. Current approaches often lack a systematic framework to predict and analyze the behavior of these systems. This has led to difficulties in anticipating how LLMs will perform various tasks, especially those that differ from their primary training objective. The challenge lies in bridging the gap between the ai system's training process and its observed performance on various tasks, which requires a more comprehensive analytical approach.
In this study, researchers from the Wu Tsai Institute, Yale University, OpenAI, Princeton University, Roundtable and Princeton University have focused on analyzing the new OpenAI system, o1, which was explicitly optimized for reasoning tasks, to determine if it presents the same. embers of autoregression” observed in previous LLMs. Researchers apply the teleological perspective, which considers the pressures that shape ai systems, to predict and evaluate o1 performance. This approach examines whether moving o1 away from pure next word prediction training mitigates the limitations associated with that goal. The study compares the performance of o1 with other LLMs on various tasks, evaluating its sensitivity to output probability and task frequency. On top of that, the researchers introduce a robust metric (token count during response generation) to quantify the difficulty of the task. This comprehensive analysis aims to reveal whether o1 represents a significant advance or still retains behavioral patterns linked to next word prediction training.
The results of the study reveal that o1, while showing significant improvements over previous LLMs, still shows sensitivity to output probability and task frequency. Across four tasks (shift ciphers, Pig Latin, item swapping, and reversal), o1 demonstrated greater accuracy on examples with high-probability outcomes compared to low-probability ones. For example, in the shift encryption task, the accuracy of o1 ranged from 47% for low probability cases to 92% for high probability cases. On top of that, o1 consumed more tokens when processing low probability examples, indicating even more difficulty. Regarding task frequency, o1 initially showed similar performance on common and rare task variants, outperforming other LLMs on rare variants. However, when tested on more challenging versions of classification and shift encryption tasks, o1 showed better performance on common variants, suggesting that task frequency effects become evident when the model is pushed to its limits. .
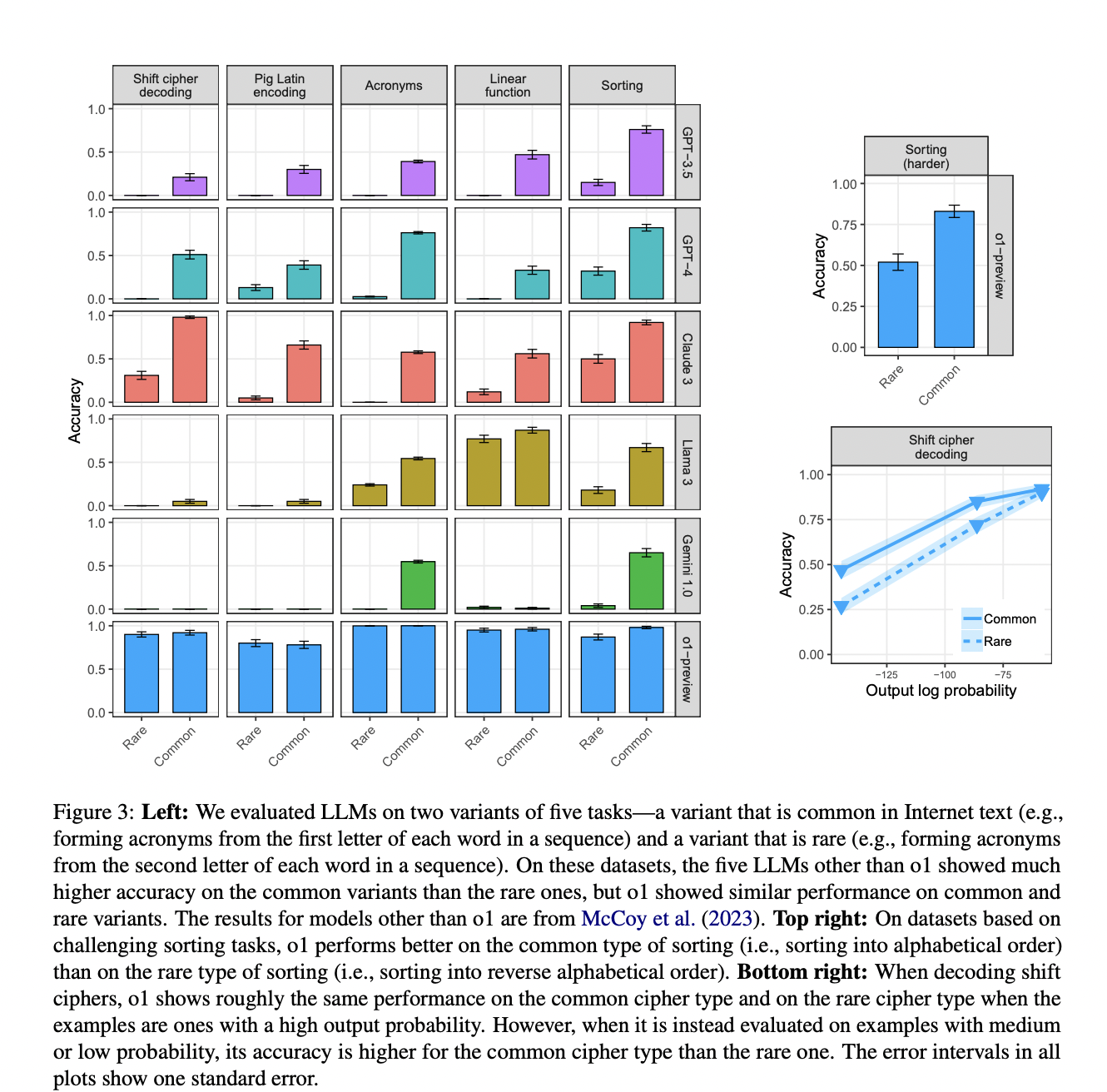
The researchers conclude that o1, despite its significant improvements over previous LLMs, still shows sensitivity to output probability and task frequency. This aligns with the teleological perspective, which considers all optimization processes applied to an ai system. O1's strong performance on algorithmic tasks reflects his explicit optimization of reasoning. However, the observed behavioral patterns suggest that o1 likely also underwent substantial next-word prediction training. The researchers propose two potential sources for the probability sensitivity of o1: biases in text generation inherent to systems optimized for statistical prediction and biases in the development of chains of thought that favor high-probability scenarios. To overcome these limitations, the researchers suggest incorporating model components that do not rely on probabilistic judgments, such as modules that execute Python code. Ultimately, while o1 represents a significant advance in ai capabilities, it still retains traces of its autoregressive training, demonstrating that the path to AGI continues to be influenced by the fundamental techniques used in the development of language models.
look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 50,000ml
Are you interested in promoting your company, product, service or event to over 1 million ai developers and researchers? Let's collaborate!
Asjad is an internal consultant at Marktechpost. He is pursuing B.tech in Mechanical Engineering from Indian Institute of technology, Kharagpur. Asjad is a machine learning and deep learning enthusiast who is always researching applications of machine learning in healthcare.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>





{kind=link}