 NEWSLETTER
NEWSLETTER
In recent years, the integration of artificial intelligence into various domains has revolutionized how we interact with technology. One of the most promising advancements is the development of multimodal models capable of understanding and processing both visual and textual information. Among these, the Llama 3.2 Vision Model stands out as a powerful tool for applications that require intricate analysis of images. This article explores the process of fine-tuning the Llama 3.2 Vision Model specifically for extracting calorie information from food images, using Unsloth ai.
Learning Objectives
- Explore the architecture and features of the Llama 3.2 Vision model.
- Get introduced to Unsloth ai and its key features.
- Learn how to fine-tune the Llama 3.2 11B Vision model, to effectively analyze food-related data, using an image dataset with the help of Unsloth ai.
This article was published as a part of the Data Science Blogathon.
Llama 3.2 Vision Model
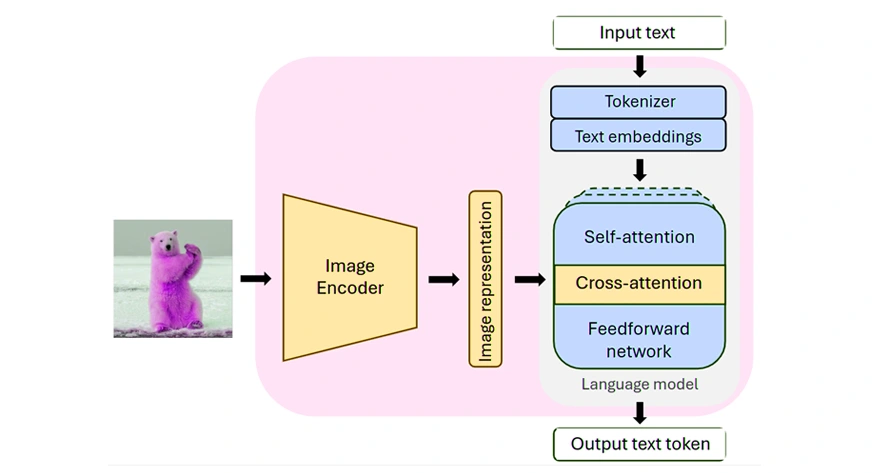
The Llama 3.2 Vision model, developed by Meta, is a state-of-the-art multimodal large language model designed for advanced visual understanding and reasoning tasks. Here are the key details about the model:
- Architecture: Llama 3.2 Vision builds upon the Llama 3.1 text-only model, utilizing an optimized transformer architecture. It incorporates a vision adapter consisting of cross-attention layers that integrate image encoder representations with the language model.
- Sizes Available: The model comes in two parameter sizes:
- 11B (11 billion parameters) for efficient deployment on consumer-grade GPUs.
- 90B (90 billion parameters) for large-scale applications.
- Multimodal Input: Llama 3.2 Vision can process both text and images, allowing it to perform tasks such as visual recognition, image reasoning, captioning, and answering questions related to images.
- Training Data: The model was trained on approximately 6 billion image-text pairs, enhancing its ability to understand and generate content based on visual inputs.
- Context Length: It supports a context length of up to 128k tokens
Also Read: Llama 3.2 90B vs GPT 4o: Image Analysis Comparison
Applications of Llama 3.2 Vision Model
Llama 3.2 Vision is designed for various applications, including:
- Visual Question Answering (VQA): Answering questions based on the content of images.
- Image Captioning: Generating descriptive captions for images.
- Image-Text Retrieval: Matching images with their textual descriptions.
- Visual Grounding: Linking language references to specific parts of an image.
<h2 class="wp-block-heading" id="h-what-is-unsloth-ai“>What is Unsloth ai?
Unsloth ai is an innovative platform designed to enhance the fine-tuning of large language models (LLMs) like Llama-3, Mistral, Phi-3, and Gemma. It aims to streamline the complex process of adapting pre-trained models for specific tasks, making it faster and more efficient.
<h3 class="wp-block-heading" id="h-key-features-of-unsloth-ai“>Key Features of Unsloth ai
- Accelerated Training: Unsloth boasts the ability to fine-tune models up to 30 times faster while reducing memory usage by 60%. This significant improvement is achieved through advanced techniques such as manual autograd, chained matrix multiplication, and optimized GPU kernels.
- User-Friendly: The platform is open-source and easy to install, allowing users to set it up locally or utilize cloud resources like Google Colab. Comprehensive documentation supports users in navigating the fine-tuning process.
- Scalability: Unsloth supports a range of hardware configurations, from single GPUs to multi-node setups, making it suitable for both small teams and enterprise-level applications.
- Versatility: The platform is compatible with various popular LLMs and can be applied to diverse tasks such as language generation, summarization, and conversational ai.
Unsloth ai represents a significant advancement in ai model training, making it accessible for developers and researchers looking to create high-performance custom models efficiently.
Performance Benchmarks of Llama 3.2 Vision
The Llama 3.2 vision models excel at interpreting charts and diagrams.
The 11 billion model surpasses Claude 3 Haiku in visual benchmarks such as MMMU-Pro, Vision (23.7), ChartQA (83.4), AI2 Diagram (91.1) while the 90 Billion model surpasses Claude 3 Haiku in all the visual interpretation tasks.
As a result, Llama 3.2 is an ideal option for tasks that require document comprehension, visual question answering, and extracting data from charts.
<h2 class="wp-block-heading" id="h-fine-tuning-llama-3-2-11b-vision-model-using-unsloth-ai“>Fine Tuning Llama 3.2 11B Vision Model Using Unsloth ai
In this tutorial, we will walk through the process of fine-tuning the Llama 3.2 11B Vision model. By leveraging its advanced capabilities, we aim to enhance the model’s accuracy in recognizing food items and estimating their caloric content based on visual input.
Fine-tuning this model involves customizing it to better understand the nuances of food imagery and nutritional data, thereby improving its performance in real-world applications. We will delve into the key steps involved in this fine-tuning process, including dataset preparation, and configuring the training environment. We’ll also be employing techniques such as LoRA (Low-Rank Adaptation) to optimize model performance while minimizing resource usage.
We will be leveraging Unsloth ai to customize the model’s capabilities. The dataset we’ll be using consists of food images, each accompanied by information on the calorie content of the various food items. This will allow us to improve the model’s ability to analyze food-related data effectively.
So, let’s begin!
Step 1. Installing Necessary Libraries
!pip install unslothStep 2. Defining the Model
from unsloth import FastVisionModel
import torch
model, tokenizer = FastVisionModel.from_pretrained(
"unsloth/Llama-3.2-11B-Vision-Instruct",
load_in_4bit = True,
use_gradient_checkpointing = "unsloth",
)
model = FastVisionModel.get_peft_model(
model,
finetune_vision_layers = True,
finetune_language_layers = True,
finetune_attention_modules = True,
finetune_mlp_modules = True,
r = 16,
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
random_state = 3443,
use_rslora = False,
loftq_config = None,
)- from_pretrained: This method loads a pre-trained model and its tokenizer. The specified model is “unsloth/Llama-3.2-11B-Vision-Instruct”.
- load_in_4bit=True: This argument indicates that the model should be loaded with 4-bit quantization, which reduces memory usage significantly while maintaining performance.
- use_gradient_checkpointing=”unsloth”: This enables gradient checkpointing, which helps in managing memory during training by saving intermediate activations.
get_peft_model: This method configures the model for fine-tuning using Parameter-Efficient Fine-Tuning (PEFT) techniques.
Fine-tuning options:
- finetune_vision_layers=True: Enables fine-tuning of the vision layers.
- finetune_language_layers=True: Enables fine-tuning of the language layers ( likely transformer layers responsible for understanding text)
- finetune_attention_modules=True: Enables fine-tuning of attention modules.
- finetune_mlp_modules=True: Enables fine-tuning of multi-layer perceptron (MLP) modules.
LoRA Parameters:
- r=16, lora_alpha=16, lora_dropout=0: These parameters configure Low-Rank Adaptation (LoRA), which is a technique to reduce the number of trainable parameters while maintaining performance.
- bias=”none”: This specifies that no bias terms will be included in the fine-tuning process for the layers.
- random_state=3443: This sets the random seed for reproducibility. By using this seed, the model fine-tuning process will be deterministic and give the same results if run again with the same setup.
- use_rslora=False: This indicates that the variant of LoRA called RSLORA is not being used. RSLORA is a different approach for parameter-efficient fine-tuning.
- loftq_config=None: This would refer to any configuration related to low-precision quantization. Since it’s set to None, no specific configuration for quantization is applied.
Step 3. Loading the Dataset
from datasets import load_dataset
dataset = load_dataset("aryachakraborty/Food_Calorie_Dataset",
split = "train(0:100)")We load a dataset on food images along with their calorie description in text.
The dataset has 3 columns – ‘image’, ‘Query’, ‘Response’
Step 4. Converting Dataset to a Conversation
def convert_to_conversation(sample):
conversation = (
{
"role": "user",
"content": (
{"type": "text", "text": sample("Query")},
{"type": "image", "image": sample("image")},
),
},
{
"role": "assistant",
"content": ({"type": "text", "text": sample("Response")}),
},
)
return {"messages": conversation}
pass
converted_dataset = (convert_to_conversation(sample) for sample in dataset)We convert the dataset into a conversation with two roles involved – user and assistant.
The assistant replies to the user query on the user provided images.
Step 5. Inference of the Model Before Fine Tuning Model
FastVisionModel.for_inference(model) # Enable for inference!
image = dataset(0)("image")
messages = (
{
"role": "user",
"content": (
{"type": "image"},
{"type": "text", "text": "You are an expert nutritionist analyzing the image to identify food items and estimate their calorie content and calculate the total calories. Please provide a detailed report in the format: 1. Item 1 - estimated calories 2. Item 2 - estimated calories ..."},
),
}
)
input_text = tokenizer.apply_chat_template(
messages, add_generation_prompt=True)
inputs = tokenizer(image,input_text, add_special_tokens=False,return_tensors="pt",).to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer, skip_prompt=True)
_ = model.generate(
**inputs,
streamer=text_streamer,
max_new_tokens=500,
use_cache=True,
temperature=1.5,
min_p=0.1
)Output:
Item 1: Fried Dumplings – 400-600 calories
Item 2: Red Sauce – 200-300 calories
Total Calories – 600-900 calories
Based on serving sizes and ingredients, the estimated calorie count for the two items is 400-600 and 200-300 for the fried dumplings and red sauce respectively. When consumed together, the combined estimated calorie count for the entire dish is 600-900 calories.
Total Nutritional Information:
- Calories: 600-900 calories
- Serving Size: 1 plate of steamed momos
Conclusion: Based on the ingredients used to prepare the meal, the nutritional information can be estimated.
The output is generated for the below input image:

As seen from the output of the original model, the items mentioned in the text refer to “Fried Dumplings” even though the original input image has “steamed momos” in it. Also, the calories of the lettuce present in the input image is not mentioned in the output from the original model.
Output from Original Model:
- Item 1: Fried Dumplings – 400-600 calories
- Item 2: Red Sauce – 200-300 calories
- Total Calories – 600-900 calories
Based on serving sizes and ingredients, the estimated calorie count for the two items is 400-600 and 200-300 for the fried dumplings and red sauce respectively. When consumed together, the combined estimated calorie count for the entire dish is 600-900 calories.
Total Nutritional Information:
- Calories: 600-900 calories
- Serving Size: 1 plate of steamed momos
Conclusion: Based on the ingredients used to prepare the meal, the nutritional information can be estimated.
Step 6. Starting the Fine Tuning
from unsloth import is_bf16_supported
from unsloth.trainer import UnslothVisionDataCollator
from trl import SFTTrainer, SFTConfig
FastVisionModel.for_training(model) # Enable for training!
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
data_collator=UnslothVisionDataCollator(model, tokenizer), # Must use!
train_dataset=converted_dataset,
args=SFTConfig(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
warmup_steps=5,
max_steps=30,
learning_rate=2e-4,
fp16=not is_bf16_supported(),
bf16=is_bf16_supported(),
#Logging Steps
logging_steps=5,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
report_to="none", # For Weights and Biases
# You MUST put the below items for vision finetuning:
remove_unused_columns = False,
dataset_text_field="",
dataset_kwargs={"skip_prepare_dataset": True},
dataset_num_proc=4,
max_seq_length=2048,
),
)
trainer_stats = trainer.train()SFTTrainer Parameters
- SFTTrainer(…): This initializes the trainer that will be used to fine-tune the model. The SFTTrainer is specifically designed for Supervised Fine-Tuning of models.
- model=model: The pre-loaded or initialized model that will be fine-tuned.
- tokenizer=tokenizer: The tokenizer used to convert text inputs into token IDs. This ensures that both text and image data are properly processed for the model.
- data_collator=UnslothVisionDataCollator(model, tokenizer): The data collator is responsible for preparing batches of data (specifically vision-language data). This collator handles how image-text pairs are batched together, ensuring they are properly aligned and formatted for the model.
- train_dataset=converted_dataset: This is the dataset that will be used for training. It’s assumed that converted_dataset is a pre-processed dataset that includes image-text pairs or similar structured data.
SFTConfig Class Parameters
- per_device_train_batch_size=2: This sets the batch size to 2 for each device (e.g., GPU) during training.
- gradient_accumulation_steps=4: This parameter determines the number of forward passes (or steps) that are performed before updating the model weights. Essentially, it allows for simulating a larger batch size by accumulating gradients over multiple smaller batches.
- warmup_steps=5: his parameter specifies the number of initial training steps during which the learning rate is gradually increased from a small value to the initial learning rate. The number of steps for learning rate warmup, where the learning rate gradually increases to the target value.
- max_steps=30: The maximum number of training steps (iterations) to perform during the fine-tuning.
- learning_rate=2e-4: The learning rate for the optimizer, set to 0.0002.
Precision Settings
- fp16=not is_bf16_supported(): If bfloat16 (bf16) precision is not supported (checked by is_bf16_supported()), then 16-bit floating point precision (fp16) will be used. If bf16 is supported, the code will automatically use bf16 instead.
- bf16=is_bf16_supported(): This checks if the hardware supports bfloat16 precision and enables it if supported.
Logging & Optimization
- logging_steps=5: The number of steps after which training progress will be logged.
- optim=”adamw_8bit”: This sets the optimizer to AdamW with 8-bit precision (likely for more efficient computation and reduced memory usage).
- weight_decay=0.01: The weight decay (L2 regularization) to prevent overfitting by penalizing large weights.
- lr_scheduler_type=”linear”: This sets the learning rate scheduler to a linear decay, where the learning rate linearly decreases from the initial value to zero.
- seed=3407: This sets the random seed for reproducibility in training.
- output_dir=”outputs”: This specifies the directory where the trained model and other outputs (e.g., logs) will be saved.
- report_to=”none”: This disables reporting to external systems like Weights & Biases, so training logs will not be sent to any remote tracking services.
Vision-Specific Parameters
- remove_unused_columns=False: Keeps all columns in the dataset, which may be necessary for vision tasks.
- dataset_text_field=””: Indicates which field in the dataset contains text data; here, it’s left empty, possibly indicating that there might not be a specific text field needed.
- dataset_kwargs={“skip_prepare_dataset”: True}: Skips any additional preparation steps for the dataset, assuming it’s already prepared.
- dataset_num_proc=4: Number of processes to use when loading or processing the dataset, which can speed up data loading. By setting the dataset_num_proc parameter, you can enable parallel processing of the dataset.
- max_seq_length=2048: Maximum sequence length for input data, allowing longer sequences to be processed. The max_seq_length parameter specifies the upper limit on the number of tokens (or input IDs) that can be fed into the model at once. Setting this parameter too low may lead to truncation of longer inputs, which can result in loss of important information.
Also Read: Fine-tuning Llama 3.2 3B for RAG
Step 7. Checking the Results of the Model Post Fine-Tuning
FastVisionModel.for_inference(model) # Enable for inference!
image = dataset(0)("image")
messages = (
{
"role": "user",
"content": (
{"type": "image"},
{"type": "text", "text": "You are an expert nutritionist analyzing the image to identify food items and estimate their calorie content and calculate the total calories. Please provide a detailed report in the format: 1. Item 1 - estimated calories 2. Item 2 - estimated calories ..."},
),
}
)
input_text = tokenizer.apply_chat_template(
messages, add_generation_prompt=True)
inputs = tokenizer(image,input_text, add_special_tokens=False,return_tensors="pt",).to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer, skip_prompt=True)
_ = model.generate(
**inputs,
streamer=text_streamer,
max_new_tokens=500,
use_cache=True,
temperature=1.5,
min_p=0.1
)Output from Fine-Tuned Model:
As seen from the output of the finetuned model, all the three items are correctly mentioned in the text along with their calories in the needed format.
Testing on Sample Data
We also test how good the fine-tuned model is on unseen data. So, we select the rows of the data not seen by the model before.
from datasets import load_dataset
dataset1 = load_dataset("aryachakraborty/Food_Calorie_Dataset",
split = "train(100:)")
#Select an input image and print it
dataset1(2)('image')We select this as the input image.

FastVisionModel.for_inference(model) # Enable for inference!
image = dataset1(2)("image")
messages = (
{
"role": "user",
"content": (
{"type": "image"},
{"type": "text", "text": "You are an expert nutritionist analyzing the image to identify food items and estimate their calorie content and calculate the total calories. Please provide a detailed report in the format: 1. Item 1 - estimated calories 2. Item 2 - estimated calories ..."},
),
}
)
input_text = tokenizer.apply_chat_template(
messages, add_generation_prompt=True)
inputs = tokenizer(image,input_text, add_special_tokens=False,return_tensors="pt",).to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer, skip_prompt=True)
_ = model.generate(
**inputs,
streamer=text_streamer,
max_new_tokens=500,
use_cache=True,
temperature=1.5,
min_p=0.1
)Output from Fine-Tuned Model:
As we can see from the output of the fine-tuned model, all the components of the pizza have been accurately identified and their calories have been mentioned as well.
Conclusion
The integration of ai models like Llama 3.2 Vision is transforming the way we analyze and interact with visual data, particularly in fields like food recognition and nutritional analysis. By fine-tuning this powerful model with Unsloth ai, we can significantly improve its ability to understand food images and accurately estimate calorie content.
The fine-tuning process, leveraging advanced techniques such as LoRA and the efficient capabilities of Unsloth ai, ensures optimal performance while minimizing resource usage. This approach not only enhances the model’s accuracy but also opens the door for real-world applications in food analysis, health monitoring, and beyond. Through this tutorial, we’ve demonstrated how to adapt cutting-edge ai models for specialized tasks, driving innovation in both technology and nutrition.
Key Takeaways
- The development of multimodal models, like Llama 3.2 Vision, enables ai to process and understand both visual and textual data, opening up new possibilities for applications such as food image analysis.
- Llama 3.2 Vision is a powerful tool for tasks involving image recognition, reasoning, and visual grounding, with a focus on extracting detailed information from images, such as calorie content in food images.
- Fine-tuning the Llama 3.2 Vision model allows it to be customized for specific tasks, such as food calorie extraction, improving its ability to recognize food items and estimate nutritional data accurately.
- Unsloth ai significantly accelerates the fine-tuning process, making it up to 30 times faster while reducing memory usage by 60%, enabling the creation of custom models more efficiently.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Frequently Asked Questions
A. The Llama 3.2 Vision model is a multimodal ai model developed by Meta, capable of processing both text and images. It uses a transformer architecture and cross-attention layers to integrate image data with language models, enabling it to perform tasks like visual recognition, captioning, and image-text retrieval.
A. Fine-tuning customizes the model to specific tasks, such as extracting calorie information from food images. By training the model on a specialized dataset, it becomes more accurate at recognizing food items and estimating their nutritional content, making it more effective in real-world applications.
A. Unsloth ai enhances the fine-tuning process by making it faster and more efficient. It allows models to be fine-tuned up to 30 times faster while reducing memory usage by 60%. The platform also provides tools for easy setup and scalability, supporting both small teams and enterprise-level applications.
A. LoRA is a technique used to optimize model performance while reducing resource usage. It helps fine-tune large language models more efficiently, making the training process faster and less computationally intensive without compromising accuracy. LoRA modifies only a small subset of parameters by introducing low-rank matrices into the model architecture.
A. The fine-tuned model can be used in various applications, including calorie extraction from food images, visual question answering, document understanding, and image captioning. It can significantly enhance tasks that require both visual and textual analysis, especially in fields like health and nutrition.





