 NEWSLETTER
NEWSLETTER
In November 2022, we announced that AWS customers can generate images from text with Stable Diffusion models in Amazon SageMaker JumpStart. Stable Diffusion is a deep learning model that allows you to generate realistic, high-quality images and stunning art in just a few seconds. Although creating impressive images can find use in industries ranging from art to NFTs and beyond, today we also expect AI to be personalizable. Today, we announce that you can personalize the image generation model to your use case by fine-tuning it on your custom dataset in Amazon SageMaker JumpStart. This can be useful when creating art, logos, custom designs, NFTs, and so on, or fun stuff such as generating custom AI images of your pets or avatars of yourself.
In this post, we provide an overview of how to fine-tune the Stable Diffusion model in two ways: programmatically through JumpStart APIs available in the SageMaker Python SDK, and JumpStart’s user interface (UI) in Amazon SageMaker Studio. We also discuss how to make design choices including dataset quality, size of training dataset, choice of hyperparameter values, and applicability to multiple datasets. Finally, we discuss the over 80 publicly available fine-tuned models with different input languages and styles recently added in JumpStart.
Stable Diffusion and transfer learning
Stable Diffusion is a text-to-image model that enables you to create photorealistic images from just a text prompt. A diffusion model trains by learning to remove noise that was added to a real image. This de-noising process generates a realistic image. These models can also generate images from text alone by conditioning the generation process on the text. For instance, Stable Diffusion is a latent diffusion where the model learns to recognize shapes in a pure noise image and gradually brings these shapes into focus if the shapes match the words in the input text. The text must first be embedded into a latent space using a language model. Then, a series of noise addition and noise removal operations are performed in the latent space with a U-Net architecture. Finally, the de-noised output is decoded into the pixel space.
In machine learning (ML), the ability to transfer the knowledge learned in one domain to another is called transfer learning. You can use transfer learning to produce accurate models on your smaller datasets, with much lower training costs than the ones involved in training the original model. With transfer learning, you can fine-tune the stable diffusion model on your own dataset with as little as five images. For example, on the left are training images of a dog named Doppler used to fine-tune the model, in the middle and right are images generated by the fine-tuned model when asked to predict Doppler’s image on the beach and a pencil sketch.

On the left are images of a white chair used to fine-tune the model and an image of the chair in red generated by the fine-tuned model. On the right are images of an ottoman used to fine-tune the model and an image of a cat sitting on an ottoman.

Fine-tuning large models like Stable Diffusion usually requires you to provide training scripts. There are a host of issues, including out of memory issues, payload size issues, and more. Furthermore, you have to run end-to-end tests to make sure that the script, the model, and the desired instance work together in an efficient manner. JumpStart simplifies this process by providing ready-to-use scripts that have been robustly tested. The JumpStart fine-tuning script for Stable Diffusion models builds on the fine-tuning script from DreamBooth. You can access these scripts with a single click through the Studio UI or with very few lines of code through the JumpStart APIs.
Note that by using the Stable Diffusion model, you agree to the CreativeML Open RAIL++-M License.
Use JumpStart programmatically with the SageMaker SDK
This section describes how to train and deploy the model with the SageMaker Python SDK. We choose an appropriate pre-trained model in JumpStart, train this model with a SageMaker training job, and deploy the trained model to a SageMaker endpoint. Furthermore, we run inference on the deployed endpoint, all using the SageMaker Python SDK. The following examples contain code snippets. For the full code with all of the steps in this demo, see the Introduction to JumpStart – Text to Image example notebook.
Train and fine-tune the Stable Diffusion model
Each model is identified by a unique model_id. The following code shows how to fine-tune a Stable Diffusion 2.1 base model identified by model_id model-txt2img-stabilityai-stable-diffusion-v2-1-base on a custom training dataset. For a full list of model_id values and which models are fine-tunable, refer to Built-in Algorithms with pre-trained Model Table. For each model_id, in order to launch a SageMaker training job through the Estimator class of the SageMaker Python SDK, you need to fetch the Docker image URI, training script URI, and pre-trained model URI through the utility functions provided in SageMaker. The training script URI contains all the necessary code for data processing, loading the pre-trained model, model training, and saving the trained model for inference. The pre-trained model URI contains the pre-trained model architecture definition and the model parameters. The pre-trained model URI is specific to the particular model. The pre-trained model tarballs have been pre-downloaded from Hugging Face and saved with the appropriate model signature in Amazon Simple Storage Service (Amazon S3) buckets, such that the training job runs in network isolation. See the following code:
With these model-specific training artifacts, you can construct an object of the Estimator class:
Training dataset
The following are the instructions for how the training data should be formatted:
- Input – A directory containing the instance images,
dataset_info.json, with the following configuration:- Images may be of .png, .jpg, or .jpeg format
- The
dataset_info.jsonfile must be of the format{'instance_prompt':<<instance_prompt>>}
- Output – A trained model that can be deployed for inference
The S3 path should look like s3://bucket_name/input_directory/. Note the trailing / is required.
The following is an example format of the training data:
For instructions on how to format the data while using prior preservation, refer to the section Prior Preservation in this post.
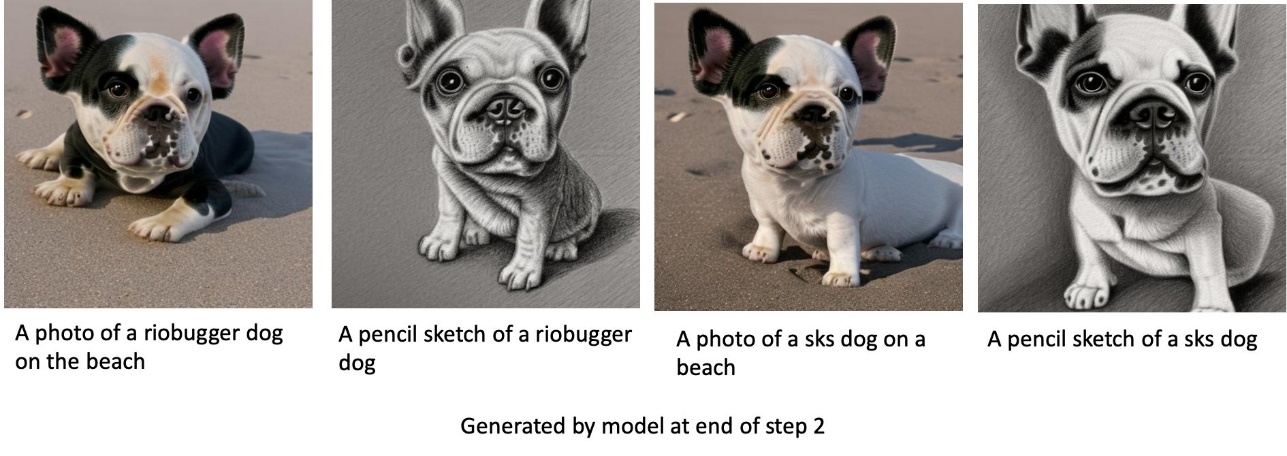
We provide a default dataset of cat images. It consists of eight images (instance images corresponding to instance prompt) of a single cat with no class images. It can be downloaded from GitHub. If using the default dataset, try the prompt “a photo of a riobugger cat” while doing inference in the demo notebook.
License: MIT.
Hyperparameters
Next, for transfer learning on your custom dataset, you might need to change the default values of the training hyperparameters. You can fetch a Python dictionary of these hyperparameters with their default values by calling hyperparameters.retrieve_default, update them as needed, and then pass them to the Estimator class. See the following code:
The following hyperparameters are supported by the fine-tuning algorithm:
- with_prior_preservation – Flag to add prior preservation loss. Prior preservation is a regularizer that avoids overfitting. (Choices:
[“True”,“False”], default:“False”.) - num_class_images – The minimum class images for prior preservation loss. If
with_prior_preservation = Trueand there aren’t enough images already present inclass_data_dir, additional images will be sampled withclass_prompt. (Values: positive integer, default: 100.) - Epochs – The number of passes that the fine-tuning algorithm takes through the training dataset. (Values: positive integer, default: 20.)
- Max_steps – The total number of training steps to perform. If not
None, overrides epochs. (Values:“None”or a string of integer, default:“None”.) - Batch size –: The number of training examples that are worked through before the model weights are updated. Same as the batch size during class images generation if
with_prior_preservation = True. (Values: positive integer, default: 1.) - learning_rate – The rate at which the model weights are updated after working through each batch of training examples. (Values: positive float, default: 2e-06.)
- prior_loss_weight – The weight of prior preservation loss. (Values: positive float, default: 1.0.)
- center_crop – Whether to crop the images before resizing to the desired resolution. (Choices:
[“True”/“False”], default:“False”.) - lr_scheduler – The type of learning rate scheduler. (Choices:
["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"], default:"constant".) For more information, see Learning Rate Schedulers. - adam_weight_decay – The weight decay to apply (if not zero) to all layers except all bias and
LayerNormweights inAdamWoptimizer. (Value: float, default: 1e-2.) - adam_beta1 – The beta1 hyperparameter (exponential decay rate for the first moment estimates) for the
AdamWoptimizer. (Value: float, default: 0.9.) - adam_beta2 – The beta2 hyperparameter (exponential decay rate for the first moment estimates) for the
AdamWoptimizer. (Value: float, default: 0.999.) - adam_epsilon – The
epsilonhyperparameter for theAdamWoptimizer. It is usually set to a small value to avoid division by 0. (Value: float, default: 1e-8.) - gradient_accumulation_steps – The number of updates steps to accumulate before performing a backward/update pass. (Value: integer, default: 1.)
- max_grad_norm – The maximum gradient norm (for gradient clipping). (Value: float, default: 1.0.)
- seed – Fix the random state to achieve reproducible results in training. (Value: integer, default: 0.)
Deploy the fine-trained model
After model training is finished, you can directly deploy the model to a persistent, real-time endpoint. We fetch the required Docker Image URIs and script URIs and deploy the model. See the following code:
On the left are the training images of a cat named riobugger used to fine-tune the model (default parameters except max_steps = 400). In the middle and right are the images generated by the fine-tuned model when asked to predict riobugger’s image on the beach and a pencil sketch.

For more details on inference, including supported parameters, response format, and so on, refer to Generate images from text with the stable diffusion model on Amazon SageMaker JumpStart.
Access JumpStart through the Studio UI
In this section, we demonstrate how to train and deploy JumpStart models through the Studio UI. The following video shows how to find the pre-trained Stable Diffusion model on JumpStart, train it, and then deploy it. The model page contains valuable information about the model and how to use it. After configuring the SageMaker training instance, choose Train. After the model is trained, you can deploy the trained model by choosing Deploy. After the endpoint is in the “in service” stage, it’s ready to respond to inference requests.
To accelerate the time to inference, JumpStart provides a sample notebook that shows how to run inference on the newly created endpoint. To access the notebook in Studio, choose Open Notebook in the Use Endpoint from Studio section of the model endpoint page.
JumpStart also provides a simple notebook which you can use to fine-tune the stable diffusion model and deploy the resulting fine-tuned model. You can use it to generate fun images of your dog. To access the notebook, search for “Generate Fun images of your dog” in the JumpStart search bar. To execute the notebook, you can use as little as five training images and upload to the local studio folder. If you have more than five images, you can upload them as well. Notebook uploads the training images to S3, trains the model on your dataset and deploy the resulting model. Training may take 20 mins to finish. You can change the number of steps to speed up the training. Notebook provides some sample prompts to try with the deployed model but you can try any prompt that you like. You can also adapt the notebook to create avatars of yourself or your pets. For instance, instead of your dog, you can upload images of your cat in the first step and then change the prompts from dogs to cats and the model will generate images of your cat.
Fine-tuning considerations
Training Stable Diffusion models tends to overfit quickly. To get good-quality images, we must find a good balance between the available training hyperparameters such as number of training steps and the learning rate. In this section, we show some experimental results and provide guidance on how set these parameters.
Recommendations
Consider the following recommendations:
- Start with good quality of training images (4–20). If training on human faces, you may need more images.
- Train for 200–400 steps when training on dogs or cats and other non-human subjects. If training on human faces, you may need more steps. If overfitting happens, reduce the nnumber of steps. If under-fitting happens (the fine-tuned model can’t generate the target subject’s image), increase the number of steps.
- If training on non-human faces, you may set
with_prior_preservation = Falsebecause it doesn’t significantly impact performance. On human faces, you may need to setwith_prior_preservation=True. - If setting
with_prior_preservation=True, use the ml.g5.2xlarge instance type. - When training on multiple subjects sequentially, if the subjects are very similar (for example, all dogs), the model retains the last subject and forgets the previous subjects. If subjects are different (for example, first a cat then a dog), the model retains both subjects.
- We recommend using a low learning rate and progressively increasing the number of steps until the results are satisfactory.
Training dataset
The quality of the fine-tuned model is directly impacted by the quality of the training images. Therefore, you need to collect high-quality images to get good results. Blurred or low-resolution images will impact the quality of the fine-tuned model. Keep in mind the following additional parameters:
- Number of training images – You may fine-tune the model on as little as four training images. We experimented with training datasets of size as little as 4 images and as many as 16 images. In both cases, fine-tuning was able to adapt the model to the subject.
- Dataset formats – We tested the fine-tuning algorithm on images of format .png, .jpg, and .jpeg. Other formats may also work.
- Image resolution – Training images may be any resolution. The fine-tuning algorithm will resize all training images before starting fine-tuning. That being said, if you want to have more control over the cropping and resizing of the training images, we recommend resizing the images yourself to the base resolution of the model (in this example, 512×512 pixels).
Experiment settings
In the experiment in this post, while fine-tuning we use the default values of the hyperparameters unless specified. Furthermore, we use one of the four datasets:
- Dog1-8 – Dog 1 with 8 images
- Dog1-16 – Dog 1 with 16 images
- Dog2-4 – Dog 2 with four images
- Cat-8 – Cat with 8 images
To reduce cluttering, we only show one representative image of the dataset in each section along with the dataset name. You can find the full training set in the section Experimentation Datasets in this post.
Overfitting
Stable Diffusion models tend to overfit when fine-tuning on a few images. Therefore, you need to select the parameters such as epochs, max_epochs, and learning rate carefully. In this section, we used the Dog1-16 dataset.

To evaluate the model’s performance, we evaluate the fine-tuned model for four tasks:
- Can the fine-tuned model generate images of the subject (Doppler dog) in the same setting as it was trained on?
- Observation – Yes it can. It’s worth noting that model performance increases with the number of training steps.
- Can the fine-tuned model generate images of the subject in a different setting than it was trained on? For example, can it generate images of Doppler on a beach?
- Observation – Yes it can. It’s worth noting that model performance increases with the number of training steps up to a certain point. If the model is being trained for too long, however, the model performance degrades as the model tends to overfit.
- Can the fine-tuned model generate images of a class which the training subject belong to? For example, can it generate an image of a generic dog?
- Observation – As we increase the number of training steps, the model starts to overfit. As a result, it forgets the generic class of a dog and will only produce images related to the subject.
- Can the fine-tuned model generate images of a class or subject not in the training dataset? For example, can it generate an image of a cat?
- Observation – As we increase the number of training steps, the model starts to overfit. As a result, it will only produce images related to the subject, regardless of the class specified.
We fine-tune the model for a different number of steps (by setting max_steps hyperparameters) and for each fine-tuned model, we generate images on each of the following four prompts (shown in the following examples from left to right:
- “A photo of a Doppler dog”
- “A photo of a Doppler dog on a beach”
- “A photo of a dog”
- “A photo of a cat”
The following images are from the model trained with 50 steps.

The following model was trained with 100 steps.

We trained the following model with 200 steps.

The following images are from a model trained with 400 steps.

Lastly, the following images are the result of 800 steps.

Train on multiple datasets
While fine-tuning, you may want to fine-tune on multiple subjects and have the fine-tuned model be able to generate images of all the subjects. Unfortunately, JumpStart is currently limited to training on a single subject. You can’t fine-tune the model on multiple subjects at the same time. Furthermore, fine-tuning the model for different subjects sequentially results in the model forgetting the first subject if the subjects are similar.
We consider the following experimentation in this section:
- Fine-tune the model for Subject A.
- Fine-tune the resulting model from Step 1 for Subject B.
- Generate images of Subject A and Subject B using the output model from Step 2.
In the following experiments, we observe that:
- If A is dog 1 and B is dog 2, then all images generated in Step 3 resemble dog 2
- If A is dog 2 and B is dog 1, then all images generated in Step 3 resemble dog 1
- If A is dog 1 and B is cat, then images generated with dog prompts resemble dog 1 and images generated with cat prompts resemble cat
Train on dog 1 and then dog 2
In Step 1, we fine-tune the model for 200 steps on eight images of dog 1. In Step 2, we fine-tune the model further for 200 steps on four images of dog 2.

The following are the images generated by the fine-tuned model at the end of Step 2 for different prompts.
Train on dog 2 and then dog 1
In Step 1, we fine-tune the model for 200 steps on four images of dog 2. In Step 2, we fine-tune the model further for 200 steps on eight images of dog 1.

The following are the images generated by the fine-tuned model at the end of Step 2 with different prompts.

Train on dogs and cats
In Step 1, we fine-tune the model for 200 steps on eight images of a cat. Then we fine-tune the model further for 200 steps on eight images of dog 1.

The following are the images generated by the fine-tuned model at the end of Step 2. Images with cat-related prompts look like the cat in Step 1 of the fine-tuning, and images with dog-related prompts look like the dog in Step 2 of the fine-tuning.

Prior preservation
Prior preservation is a technique that uses additional images of the same class that we are trying to train on. For instance, if the training data consists of images of a particular dog, with prior preservation, we incorporate class images of generic dogs. It tries to avoid overfitting by showing images of different dogs while training for a particular dog. A tag indicating the specific dog present in the instance prompt is missing in the class prompt. For instance, the instance prompt may be “a photo of a riobugger cat” and the class prompt may be “a photo of a cat.” You can enable prior preservation by setting the hyperparameter with_prior_preservation = True. If setting with_prior_preservation = True, you must include class_prompt in dataset_info.json and may include any class images available to you. The following is the training dataset format when setting with_prior_preservation = True:
- Input – A directory containing the instance images,
dataset_info.jsonand (optional) directoryclass_data_dir. Note the following:- Images may be of .png, .jpg, .jpeg format.
- The
dataset_info.jsonfile must be of the format{'instance_prompt':<<instance_prompt>>,'class_prompt':<<class_prompt>>}. - The
class_data_dirdirectory must have class images. Ifclass_data_diris not present or there aren’t enough images already present inclass_data_dir, additional images will be sampled withclass_prompt.
For datasets such as cats and dogs, prior preservation doesn’t significantly impact the performance of the fine-tuned model and therefore can be avoided. However, when training on faces, this is necessary. For more information, refer to Training Stable Diffusion with Dreambooth using Diffusers.
Instance types
Fine-tuning Stable Diffusion models require accelerated computation provided by GPU-supported instances. We experiment our fine-tuning with ml.g4dn.2xlarge (16 GB CUDA memory, 1 GPU) and ml.g5.2xlarge (24 GB CUDA memory, 1 GPU) instances. The memory requirement is higher when generating class images. Therefore, if setting with_prior_preservation=True, use the ml.g5.2xlarge instance type, because training runs into the CUDA out of memory issue on the ml.g4dn.2xlarge instance. The JumpStart fine-tuning script currently utilizes single GPU and therefore, fine-tuning on multi-GPU instances will not yield performance gain. For more information on different instance types, refer to Amazon EC2 Instance Types.
Limitations and bias
Even though Stable Diffusion has impressive performance in generating images, it suffers from several limitations and biases. These include but are not limited to:
- The model may not generate accurate faces or limbs because the training data doesn’t include sufficient images with these features
- The model was trained on the LAION-5B dataset, which has adult content and may not be fit for product use without further considerations
- The model may not work well with non-English languages because the model was trained on English language text
- The model can’t generate good text within images
For more information on limitations and bias, see Stable Diffusion v2-1-base Model Card. These limitations for the pre-trained model can also carry over to the fine-tuned models.
Clean up
After you’re done running the notebook, make sure to delete all resources created in the process to ensure that the billing is stopped. Code to clean up the endpoint is provided in the associated Introduction to JumpStart – Text to Image example notebook.
Publicly available fine-tuned models in JumpStart
Even though Stable Diffusion models released by StabilityAI have impressive performance, they have limitations in terms of the language or domain it was trained on. For instance, Stable Diffusion models were trained on English text, but you may need to generate images from non-English text. Alternatively, Stable Diffusion models were trained to generate photorealistic images, but you may need to generate animated or artistic images.
JumpStart provides over 80 publicly available models with various languages and themes. These models are often fine-tuned versions from Stable Diffusion models released by StabilityAI. If your use case matches with one of the fine-tuned models, you don’t need to collect your own dataset and fine-tune it. You can simply deploy one of these models through the Studio UI or using easy-to-use JumpStart APIs. To deploy a pre-trained Stable Diffusion model in JumpStart, refer to Generate images from text with the stable diffusion model on Amazon SageMaker JumpStart.
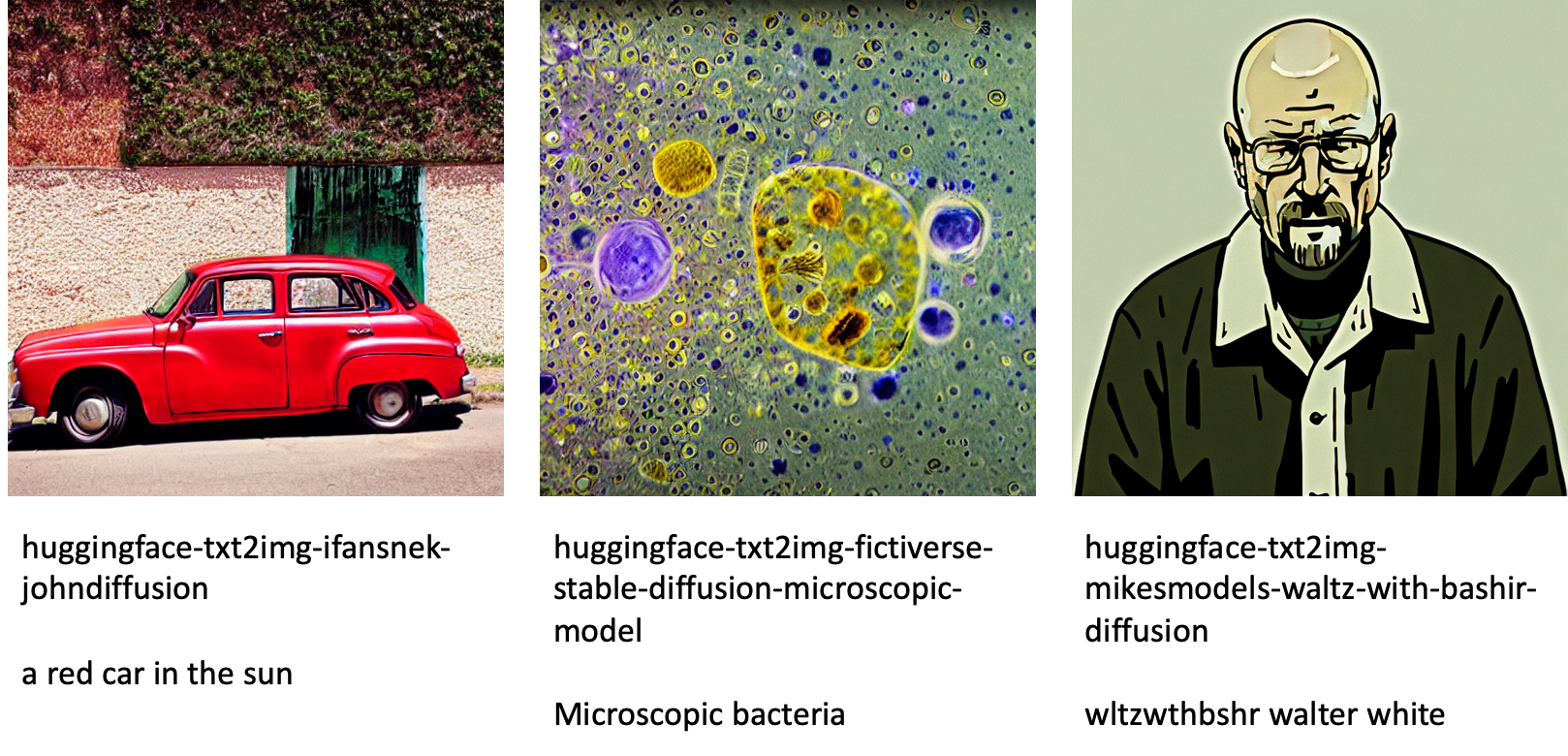
The following are some of the examples of images generated by the different models available in JumpStart.


Note that these models are not fine-tuned using JumpStart scripts or DreamBooth scripts. You can download the full list of publicly available fine-tuned models with example prompts from here.
For more example generated images from these models, please see section Open Sourced Fine-tuned models in the Appendix.
Conclusion
In this post, we showed how to fine-tune the Stable Diffusion model for text-to-image and then deploy it using JumpStart. Furthermore, we discussed some of the considerations you should make while fine-tuning the model and how it can impact the fine-tuned model’s performance. We also discussed the over 80 ready-to-use fine-tuned models available in JumpStart. We showed code snippets in this post—for the full code with all of the steps in this demo, see the Introduction to JumpStart – Text to Image example notebook. Try out the solution on your own and send us your comments.
To learn more about the model and the DreamBooth fine-tuning, see the following resources:
To learn more about JumpStart, check out the following blog posts:
About the Authors
 Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.
Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.
 Heiko Hotz is a Senior Solutions Architect for AI & Machine Learning with a special focus on natural language processing (NLP), large language models (LLMs), and generative AI. Prior to this role, he was the Head of Data Science for Amazon’s EU Customer Service. Heiko helps our customers be successful in their AI/ML journey on AWS and has worked with organizations in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. In his spare time, Heiko travels as much as possible.
Heiko Hotz is a Senior Solutions Architect for AI & Machine Learning with a special focus on natural language processing (NLP), large language models (LLMs), and generative AI. Prior to this role, he was the Head of Data Science for Amazon’s EU Customer Service. Heiko helps our customers be successful in their AI/ML journey on AWS and has worked with organizations in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. In his spare time, Heiko travels as much as possible.
Appendix: Experiment datasets
This section contains the datasets used in the experiments in this post.
Dog1-8

Dog1-16

Dog2-4

Dog3-8

Appendix: Open Sourced Fine-tuned models
The following are some of the examples of images generated by the different models available in JumpStart. Each image is captioned with a model_id starting with a prefix huggingface-txt2img- followed by the prompt used to generate the image in the next line.






























{kind=link}