 NEWSLETTER
NEWSLETTER
This blog is part of the series, Generative ai and ai/ML in Capital Markets and Financial Services.
Company earnings calls are crucial events that provide transparency into a company’s financial health and prospects. Earnings reports detail a firm’s financials over a specific period, including revenue, net income, earnings per share, balance sheet, and cash flow statement. Earnings calls are live conferences where executives present an overview of results, discuss achievements and challenges, and provide guidance for upcoming periods.
These disclosures are vitally important for capital markets, significantly impacting stock prices. Investors and analysts closely watch key metrics like revenue growth, earnings per share, margins, cash flow, and projections to assess performance against peers and industry trends. The rate of growth and profit margins influence the premium and multiplier that investors are willing to pay for a company’s stock, ultimately affecting stock returns and price movements.
Earnings calls also allow investors to look for new clues about a company’s future. Companies often release information about new products, cutting-edge technology, mergers and acquisitions, and investments in new market themes and trends during these events. Such details can signal potential growth opportunities for investors, analysts, and portfolio managers.
Traditionally, earnings call scripts have followed similar templates, making it a repeatable task to generate them from scratch each time. On the other hand, generative artificial intelligence (ai) models can learn these templates and produce coherent scripts when fed with quarterly financial data. With generative ai, companies can streamline the process of creating first drafts of earnings call scripts for a new quarter using repeatable templates and information about specific performance and business highlights. The initial draft of a large language model (LLM) generated earnings call script can be then refined and customized using feedback from the company’s executives.
amazon Bedrock offers a straightforward way to build and scale generative ai applications with foundation models (FMs) and LLMs. amazon Bedrock is a fully managed service that offers a choice of high-performing FMs from leading ai companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral ai, Stability ai, and amazon through a single API. Model customization helps you deliver differentiated and personalized user experiences. To customize models for specific tasks, you can privately fine-tune FMs using your own labeled datasets in just a few quick steps.
In this post, we showcase how to generate the first draft of an earnings call script for the new quarter using LLMs. We demonstrate two methods to generate an earnings call script with LLMs: few-shot learning and fine-tuning. We assess the generated earnings call scripts and the applied methods from different dimensions—comprehensiveness, hallucinations, writing style, ease of use, and cost—and present our findings.
Solution overview
We apply two methods to generate the first draft of an earnings call script for the new quarter using LLMs:
- Prompt engineering with few-shot learning – We use examples of the past earnings scripts with Anthropic Claude 3 Sonnet on amazon Bedrock to generate an earnings call script for a new quarter.
- Fine-tuning – We fine-tune Meta Llama 2 70B on amazon Bedrock using input/output labeled data from the past earnings scripts and use the customized model to generate an earnings call script for a new quarter.
Both methods involve utilizing a consistent dataset of earnings call transcripts across multiple quarters. We use several past years of quarterly earnings calls, with one quarter set aside, which was used as ground truth for testing and comparison.
The process starts by retrieving the earnings call transcripts from the past quarters to the recent quarter. The next step involves selecting multiple scripts from the previous quarters to serve as few-shot learning examples as well as input/output dataset for fine-tuning. The script for the most recent quarter is held out for validation and evaluation of generated scripts. The generated script is evaluated by comparing it with the actual script for the quarter, which was initially kept aside.
The following diagram illustrates the solution architecture and workflow for both methods.
In the following sections, we discuss the workflows of each method in more detail.
Few-shot learning with Anthropic Claude 3 Sonnet on amazon Bedrock
The prompt engineering for few-shot learning using Anthropic Claude 3 Sonnet is divided into four sections, as shown in the following figure. Three sections have constant instructions to the LLM based on assigning the LLM a role, instructions on style and tone of narrative, and examples for earnings calls from past quarters for few-shot learning. The fourth section has information on financial performance, results, and business highlights for the current quarter for which earnings calls are to be generated by the LLM.

We used Anthropic Claude 3 Sonnet to generate an earnings call for a new quarter using earnings calls from past quarters. The following is an example of our few-shot learning along with prompt instructions:
Section A: Overall prompt instructions (context) You are the CEO and CFO of Any Company preparing to present the quarterly earnings report to investors. Draft a comprehensive earnings call script that covers the key financial metrics, business highlights, and future outlook for the given quarter. Provide details on revenue, operating income, segment performance, and important strategic initiatives or product launches during the quarter.
Section B: Specific guidance for the earnings script (context) The earnings script should be written in a formal, investor-friendly tone suitable for a public earnings call. Use clear and concise language to explain financial performance and business developments. Aim to strike a balance between providing sufficient details and keeping the script reasonably concise. Incorporate specific data points and figures but avoid overwhelming with excessive numerical minutiae. The overall structure should flow logically, covering key topics like revenue, operating income, segment highlights, strategic priorities, and forward-looking guidance. Use the following 5 instructions when generating results for the earnings call script.
1. Provide a clear structure by organizing the content into logical sections, such as financial highlights, segment performance, operational metrics, strategic initiatives, and a forward-looking view. 2. Include granular details and insights into the factors impacting performance, such as customer behavior trends, supply chain improvements, cost optimization efforts, and any other relevant context etc.3. Substantiate your commentary with specific data points and percentages to lend credibility to your statements. 4. Offer a comprehensive forward-looking view by discussing capital investments, preparedness for upcoming events or seasons, and the long-term strategic focus or priorities. 5. Maintain a measured, objective, and analytical tone throughout the content, avoiding overly conversational or casual language.
Section C: Example Scripts from past quarters (for Few Shot/ Chain-of-thought)
The example scripts from past quarters provide a reference for the structure, tone, and level of detail expected in an earnings call script. Use these examples to understand how to present financial data, highlight key business initiatives, and address investor concerns or questions. However, ensure that the script for current specific Quarter is tailored to the specific financial performance and business events of that quarter.amazon Earnings call transcript for Q1 2021 ...
amazon Earnings call transcript for Q2 2021 ...<\example>
Section D: Financial data for quarter for which script is required (context)
Provide the actual financial results for the specific quarter, including:Total revenue and year-over-year growth rateRevenue breakdown by key segments (e.g. AWS, Online Stores, etc.)Operating income (total and by segment if available)Any key operating metrics (e.g. Prime membership, third-party seller metrics, etc.)Notes on significant factors impacting results (e.g. foreign exchange, product launches, one-time events)Forward-looking guidance on revenue, operating income for next quarterHighlight key business developments, product launches or strategic priorities for the quarter :
<\financial_data>
Fine-tune Meta Llama 2 70B on amazon Bedrock
In this section, we present our approach to improving the quality of generated earnings call scripts by fine-tuning an LLM. We chose to adapt the Meta Llama 2 70B model, which is powerful and known for its strong performance across various natural languages tasks, to the specific domain of earnings call scripts.
The following diagram illustrates the workflow for our fine-tuning method.
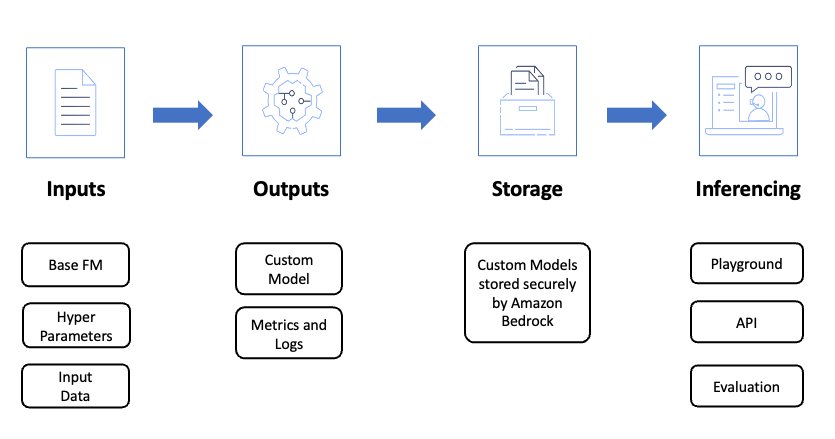
To prepare the training data, we collected a comprehensive dataset of real earnings call transcripts from Q1 2021 to Q4 2022 for amazon.com. This focused dataset allows the model to better learn the company’s domain-specific knowledge and terminology. The time span also makes sure the model can learn from recent trends and patterns in earnings communications.
amazon Bedrock offers a model customization feature that enables you to directly use your own data to customize a wide variety of models. This feature not only helps improve model performance on specific tasks but also allows the model to better understand company-specific domain knowledge and terms, ultimately creating a better user experience.
To fine-tune a text-to-text model, you need to prepare training and optional validation datasets by creating a JSONL file with multiple JSON lines. Each JSON line is a sample containing both a prompt and completion field. In our use case, the prompt contains the prompt template, which includes key financial data for that quarter, and the completion field contains the actual earnings call transcript for that quarter.
We use the following prompt template:
{"prompt": ”Section A: Overall prompt instructions (context)… Section B: Specific guidance for the earnings script (context)… Section D: Financial data for Q1 2021 for which script is required (context) The financial data for {time_period} is:{Section D}<\financial_data> Please generate the earning report for {time_period} to the investors, based on the information provided above. Don't make up any information. ", "completion": ”Real earning call script for that Q1 2021"}
The training data is prepared in JSONL format, with each line representing an earnings call for a quarter:
{"prompt": "", "completion": ""}{"prompt": "", "completion": ""}{"prompt": "", "completion": ""}
When the dataset is ready, we upload it to amazon Simple Storage Service (amazon S3) and set up a customization job in amazon Bedrock. The training time varies from minutes to hours, depending on the size of the training data and the selected model. After the training job is complete, you must purchase Provisioned Throughput to use the model and generate future earnings call scripts. You can select the No Commitment option for Provisioned Throughput, which is billed on an hourly basis.
For inference, because some language models require a clear separation between the input prompt and expected output during fine-tuning, we need to add a special delimiting key before providing the input to the model. Specifically, for the Meta Llama 2 70B model, we add the key \n\n Response:\n after the input prompt. This delimiter helps the model distinguish where the prompt ends and the expected response should begin, allowing it to generate more accurate outputs. The prompt would look as follows:
Prompt:{User_Input_Prompt}
Response:
By providing this formatted prompt during inference, the fine-tuned Meta Llama 2 70B model can better understand the input context and generate a more relevant earnings call script as the response.
For better performance, you can use the same prompt template with the current quarter’s financial data (without the few-shot learning examples), format it with the delimiter, and send it to the customized model to generate the final earnings call script for that quarter.
Evaluation of few-shot prompt engineering and fine-tuning
We evaluated the generated earnings call transcripts from both methods (few-shot prompt engineering and fine-tuning) using two different approaches:
- Evaluated by a human reviewer
- Evaluated by comparing three variations using an LLM (Anthropic Claude 3 Sonnet)
Evaluated by human reviewer
The following table summarizes a human reviewer’s evaluation.
It is imperative to note that two factors contributed to the differences: varying approaches (few-shot learning and fine-tuning) and disparate models (Anthropic Claude 3 and Meta Llama 70B). Consequently, the results cannot be interpreted as a mere comparison of models. It is advisable to explore the approaches with your specific use case and data, and subsequently evaluate the outcomes by discussing with subject matter experts from the relevant business department.
| Factor | Fine-Tuned Model | Few-shot Prompt Engineering |
| Comprehensiveness | The script covers most of the key points provided in the prompts, although it ignored a few details. For example, it misses the point that the growth in advertising was primarily driven by using machine learning models to improve relevancy of ads. | The script covers key points provided in the prompts. |
| Hallucination | Two instances. (1) “This growth was driven by strong demand for our Prime Day event, which saw record-breaking sales and attracted millions of new Prime members.” (2) “This growth was driven by strong demand in our key markets, including India and Japan.” | Once. (1) “In North America, revenue grew 11% year-over-year to $87.9 billion, fueled by continued robust demand and greater purchase frequency by Prime Members.” |
| Writing style | (1) This script uses mostly objective and precise language, which is consistent with the real earnings call. Still, it has subjective expressions such as “a huge success,” and imprecise expressions such as “double digit growth.” (2) The language offers less variations. For example, it uses the format of “This ___ was driven by ___” 10 times without variations. (3) The model generated some additional sentences. For example, “Now, let’s turn to our forward guidance. At this time, we’re not providing specific revenue or operating income guidance for the fourth quarter.“ | The real earnings call uses precise and objective language, while this script uses more metaphoric expressions such as “laser-focused” and “made further strides,” as well as subjective expressions such as “invest prudently” and “disciplined execution.“ |
| Ease of Use | (1) Fine-tuning a model in amazon Bedrock gives the option of following steps on the amazon Bedrock console or apply coding to interact with LLMs on amazon Bedrock through the API. (2) The fine-tuning process generally takes longer compared to few-shot prompt engineering based on the same documents. (3) Fine-tuning requires preparing data in input/output format (JSON files) for training the selected model. (4) If a new document is added, the whole fine-tuned model needs to be updated by going through the same fine-tuning process. | (1) amazon Bedrock allows users to give instructions and example data to an LLM as is using both the UI or creating reproducible codes. (2) If a new document is added, the user only needs to add to the prompt an example for few-shot learning or prompt instructions. Overall, few-shot prompt engineering is easier to implement, compared to fine-tuning a model. |
| Cost | Monthly cost incurred for fine-tuning = Fine-tuning training cost for the model (priced by number of tokens for training data) + custom model storage per month + hourly cost (or Provisioned Throughput cost for time commitment) of custom model inference. | Priced by number of input (few-shot prompts and examples) and output tokens for the model. |
The cost comparison can be further evaluated by the frequency of usage, as shown in the following table.
| Method | One-Time Cost | Recurring Cost | Inference Cost |
| Fine-Tuning | Priced by the number of tokens for training data | Custom model storage cost per month | Custom model inference cost (hourly or Provisioned Throughput commitment) |
| Few-Shot Prompt Engineering | N/A | N/A | Priced by number of input (prompts and examples) and output tokens |
Evaluated by comparing three variations using an LLM
We tested the following variations:
- Variation A – Earnings call transcript from few-shot learning with Anthropic Claude v3 Sonnet
- Variation B – Earnings call transcript with fine-tuned Meta Llama 70B
- Variation C – Actual earnings call transcript for the quarter
The following table summarizes the key similarities and differences between the three variations of the amazon Q3 2023 earnings call transcript. Variation A and Variation B have two main differences – different approaches (few-shot learning vs fine-tuning) and different models (Anthropic Claude 3 vs Meta Llama 70B).
| . | Identified Factor | Result Summaries |
| Similarities | Financial Metrics | All variations report strong financial results, with revenue growth around 11% year-over-year and significant increases in operating income. |
| Business Highlights | They highlight the success of Prime Day as a major driver of sales and Prime member growth. The transcripts mention continued growth in third-party seller services, advertising, and AWS. | |
| Management Focus | There is a focus on improving operational efficiency, cost optimization, and supply chain/delivery improvements. | |
| Innovation and Partnerships | Generative ai initiatives and partnerships (such as Anthropic, amazon Bedrock, and amazon CodeWhisperer) are discussed in relation to AWS. | |
| Dissimilarities | Level of Financial Detail | Variation A provides more detailed financials (exact revenue, operating income figures) than B and C. |
| Narrative/ Commentary Style – | Variation B has more personal commentary from “Jeff Bezos” and “Brian Olsavsky” compared to A and C’s more generic and impersonal style. | |
| Level of Business Detail – | Variation C goes into more specifics on initiatives like regionalization, inventory optimization, and cost reduction efforts. Variation A discusses priorities and forward-looking initiatives in more depth compared to B and C. | |
| Forward Guidance | Only Variation C mentions actual forward guidance on capital investments for 2023. |
Moreover, we can compare the difference between A vs. C and B vs. C to better compare the generated results to the actual earning scripts.
| Identified Factor | Difference between A & C | Difference between B & C |
| Financial Details | A lacks some of the specific financial details and figures present in the actual script. | B is more similar to the actual script in terms of providing segment-wise financial figures and percentages. |
| Depth of Content | A mentions broad themes and priorities, whereas C dives deeper into operational metrics, cost savings initiatives, and strategic updates. | C provides additional details on topics like free cash flow, capital investments, and strategic initiatives like generative ai. |
Overall, although the core financial highlights are similar, there are nuances in the depth of details provided and the narrative and commentary style across the three variations.
Conclusion
Generating high-quality earnings call script drafts using LLMs is a promising approach that can streamline the process for companies. Both the few-shot prompt engineering and fine-tuning methods demonstrated the ability to produce scripts covering key financial metrics, business updates, and forward-looking guidance. Each method has its own nuances. However, there are trade-offs in terms of comprehensiveness, hallucinations, writing style, ease of implementation, and cost that companies must evaluate based on their specific needs and priorities. As language models continue advancing, further research in customizing and refining these models for the financial services and capital markets domain could unlock even more value for financial communications processes.
This blog presents a framework for two different approaches: few-shot prompt engineering and fine-tuning with Large Language Models (LLMs), followed by an evaluation of the results. The findings should not be interpreted as prescriptive recommendations for favoring one approach over the other, as the choice depends on the specific content and prompts. Additionally, the results should not be construed as a direct comparison of LLMs, as the methodologies employed with each LLM differ, making it an apples-to-oranges comparison. As LLMs continue to advance, we anticipate further improvements in their output quality.
As next steps, you can use amazon Bedrock to explore your own data and use cases. You can engage in few-shot prompt engineering and fine-tuning methods with different LLMs on amazon Bedrock, using your specific data securely and privately. Furthermore, you can evaluate the results of these methods by collaborating with subject matter experts or using evaluation frameworks, enabling you to assess the performance and suitability of the methods and LLMs on amazon Bedrock for your particular use case. You can try out and compare the results, and either use prompt engineering or deploy your own fine-tuned model to generate the earnings calls tied to your company. You can also evaluate both approaches for any related use case.
Refer to Prompt engineering guidelines and Custom models for more information about these two methods. To learn more about applying generative ai for investment research, please refer to ai-powered assistants for investment research with multi-modal data: An application of Agents for amazon Bedrock.
Refer to this blog to find out more about, empowering analysts to perform financial statement analysis, hypothesis testing, and cause-effect analysis with amazon Bedrock, Anthropic Claude 3 Sonnet, and prompt engineering
About the Authors
 Sovik Kumar Nath is an ai/ML and Generative ai senior solution architect with AWS. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. He has double masters degrees from the University of South Florida, University of Fribourg, Switzerland, and a bachelors degree from the Indian Institute of technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and watching movies.
Sovik Kumar Nath is an ai/ML and Generative ai senior solution architect with AWS. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. He has double masters degrees from the University of South Florida, University of Fribourg, Switzerland, and a bachelors degree from the Indian Institute of technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and watching movies.
 Yanyan Zhang is a Senior Generative ai Data Scientist at amazon Web Services, where she has been working on cutting-edge ai/ML technologies as a Generative ai Specialist, helping customers leverage GenAI to achieve their desired outcomes. Yanyan graduated from Texas A&M University with a Ph.D. degree in Electrical Engineering. Outside of work, she loves traveling, working out and exploring new things.
Yanyan Zhang is a Senior Generative ai Data Scientist at amazon Web Services, where she has been working on cutting-edge ai/ML technologies as a Generative ai Specialist, helping customers leverage GenAI to achieve their desired outcomes. Yanyan graduated from Texas A&M University with a Ph.D. degree in Electrical Engineering. Outside of work, she loves traveling, working out and exploring new things.
 Jia (Vivian) Li is a Senior Solutions Architect in AWS, with specialization in ai/ML. She currently supports customers in financial industry. Prior to joining AWS in 2022, she had 7 years of experience supporting enterprise customers use ai/ML in the cloud to drive business results. Vivian has a BS from Peking University and a PhD from University of Southern California. In her spare time, she enjoys all the water activities, and hiking in the beautiful mountains in her home state, Colorado.
Jia (Vivian) Li is a Senior Solutions Architect in AWS, with specialization in ai/ML. She currently supports customers in financial industry. Prior to joining AWS in 2022, she had 7 years of experience supporting enterprise customers use ai/ML in the cloud to drive business results. Vivian has a BS from Peking University and a PhD from University of Southern California. In her spare time, she enjoys all the water activities, and hiking in the beautiful mountains in her home state, Colorado.






{kind=link}