 NEWSLETTER
NEWSLETTER
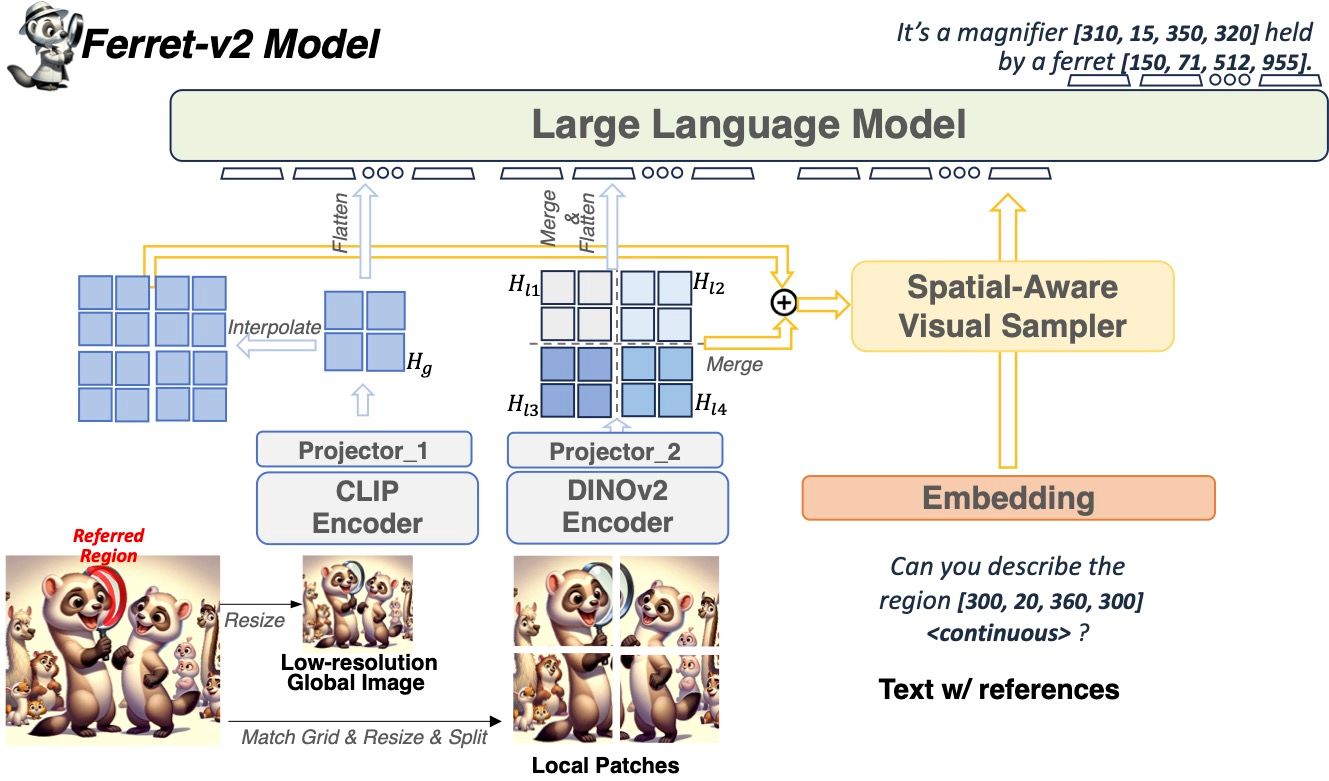
While Ferret seamlessly integrates regional understanding into the Large Language Model (LLM) to facilitate its referencing and grounding capability, it suffers from certain limitations: it is restricted by the pre-trained fixed visual encoder and failed to perform well on larger tasks. In this work, we present Ferret-v2, a significant update of Ferret, with three key designs. (1) Any-Resolution Grounding and Grounding: A flexible approach that effortlessly handles higher image resolution, improving the model’s ability to process and understand images in greater detail. (2) Multi-Granularity Visual Encoding: By integrating the additional DINOv2 encoder, the model learns better and more diverse underlying contexts for both global and fine-grained visual information. (3) A Three-Stage Training Paradigm: In addition to image caption alignment, an additional stage is proposed for high-resolution dense alignment before final instruction tuning. Experiments show that Ferret-v2 provides substantial improvements over Ferret and other state-of-the-art methods, thanks to its high-resolution scaling and fine-grained visual processing.






{kind=link}