 NEWSLETTER
NEWSLETTER
Large language models (LLMs) have demonstrated impressive capabilities in in-context learning (ICL), a form of supervised learning that does not require parameter updates. However, researchers are now exploring whether this capability extends to reinforcement learning (RL), introducing the concept of in-context reinforcement learning (ICRL). The challenge lies in adapting the ICL approach, which is based on input-output pairs, to an RL framework that involves input-output-reward triplets. This shift from a static data set to a dynamic online learning scenario presents unique difficulties in early model construction and adaptation. The key issue is determining whether LLMs can effectively learn and improve their performance through ICRL, potentially opening new avenues for ai systems to adapt and learn from their environment without traditional parameter updates.
Existing attempts to explore ICL have primarily focused on supervised learning scenarios. Researchers have extensively studied the underlying mechanisms and effectiveness of ICL, demonstrating that LLMs can learn new tasks within their context window. However, these efforts have been limited to supervised learning, leaving the potential of ICRL largely unexplored.
Recent advances in extending the length of context windows of LLMs have enabled studies involving hundreds or thousands of demonstrations, showing continuous improvements in performance. While some research suggests that models can learn from errors, this finding should have universal support and may require explicit reasoning about errors.
In reinforcement learning, previous work has investigated the ability of LLMs to solve multi-armed bandit problems in a simplified RL environment. These studies found challenges with naïve approaches and highlighted LLMs' difficulties with exploration. However, they were limited to simple scenarios and did not address more complex contextual bandit problems or general RL tasks.
Researchers from Cornell University, EPFL, and Harvard University proposed a unique method for ICRL that addresses the limitations of naive approaches by introducing two key innovations. First, it addresses the problem of exploration by incorporating stochasticity into cue construction, using the sensitivity of LLMs to cue composition. Second, it simplifies the learning process by filtering out negative examples from the context, making the message more similar to traditional in-context learning formats.
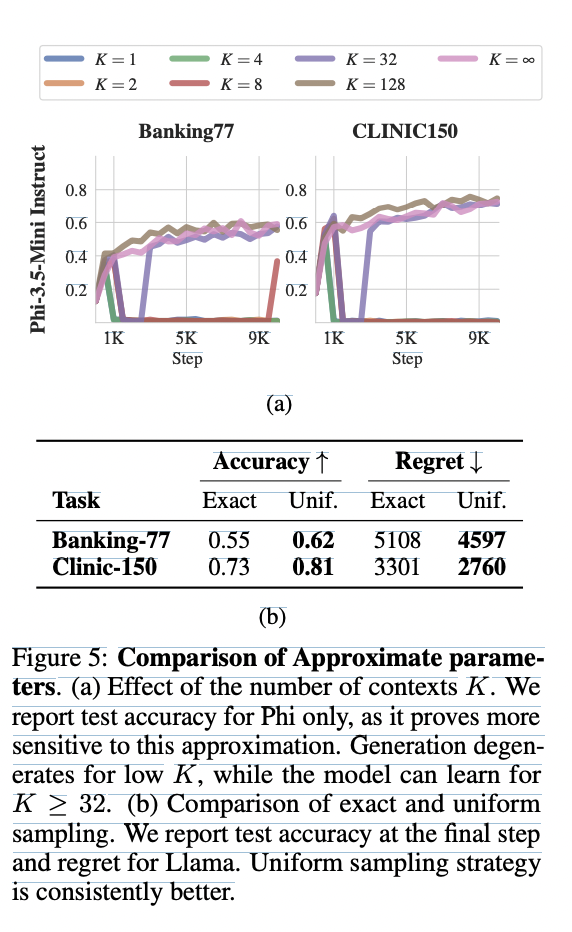
This approach effectively prevents degeneracy in experiments and allows LLMs to perform ICRL successfully. The method demonstrates a strong correlation between performance and computational resources, allowing for flexible trade-offs between accuracy and efficiency. To mitigate the increasing computational costs associated with looking at more examples, the researchers developed an approximation technique that maintains performance while reducing resource requirements.
The proposed ICRL method has shown impressive results on various classification tasks, significantly improving the model performance compared to zero-shot accuracy. For example, in the Banking77 classification task, Llama's accuracy increased from 17.2% to 66.0% via ICRL. The approach has proven effective with different LLM architectures, showing its potential as a versatile technique to improve the adaptive learning capabilities of ai systems.
This method introduces two key approaches to ICRL: naive ICRL and explorative ICRL. Naive ICRL follows a simple implementation where the model observes new examples, predicts outcomes, and receives rewards. These episodes are buffered and used to build the context for future predictions. However, this approach fails due to its inability to explore the output space effectively.
Exploratory ICRL addresses these limitations by introducing stochasticity and focusing on positive reinforcement. Randomly selects past episodes to include in the message, using the LLMs' sensitivity for message composition. This method only includes episodes with positive rewards in the context, simplifying the learning process. The algorithm uses a Bernoulli variable parameterized by pkeep to determine which past episodes to include, creating unique reasoning for each entry.
To manage context window saturation, Explorative ICRL employs three downsampling strategies: unbiased shuffling, leading prefix selection, and trailing suffix selection. While this approach effectively introduces exploration and improves performance, it has a higher computational cost due to the need for a new context construction for each entry, which limits the benefits of caching used in the Naive approach.


The results demonstrate that LLMs can effectively learn in context from rewards alone using the Explorative ICRL method. This approach shows significant improvements over zero-shot performance across various tasks and models. For example, Explorative ICRL improved Llama's accuracy by 48.8% on Banking-77 and 56.8% on Clinic-150, with similar gains observed for the Phi model.
Exploratory ICRL consistently outperforms zero-shot baselines and shows continued growth in performance over time, especially on more challenging datasets with numerous labels. In some environments, its accuracy approaches that of in-context supervised learning, highlighting its potential as a powerful learning technique.
In contrast, the Naive ICRL approach fails to learn and often performs worse than the zero approach due to its inability to explore effectively. Visualization of prediction confusion matrices and outcome distributions clearly illustrates the superior exploration capabilities of Explorative ICRL compared to the Naive approach.
Further analysis reveals that both key modifications to Explorative ICRL (stochasticity for exploration and focus on positive reward episodes) contribute significantly to its success. The method shows some robustness to noisy rewards, maintaining performance even with a 10% probability of inverted rewards.

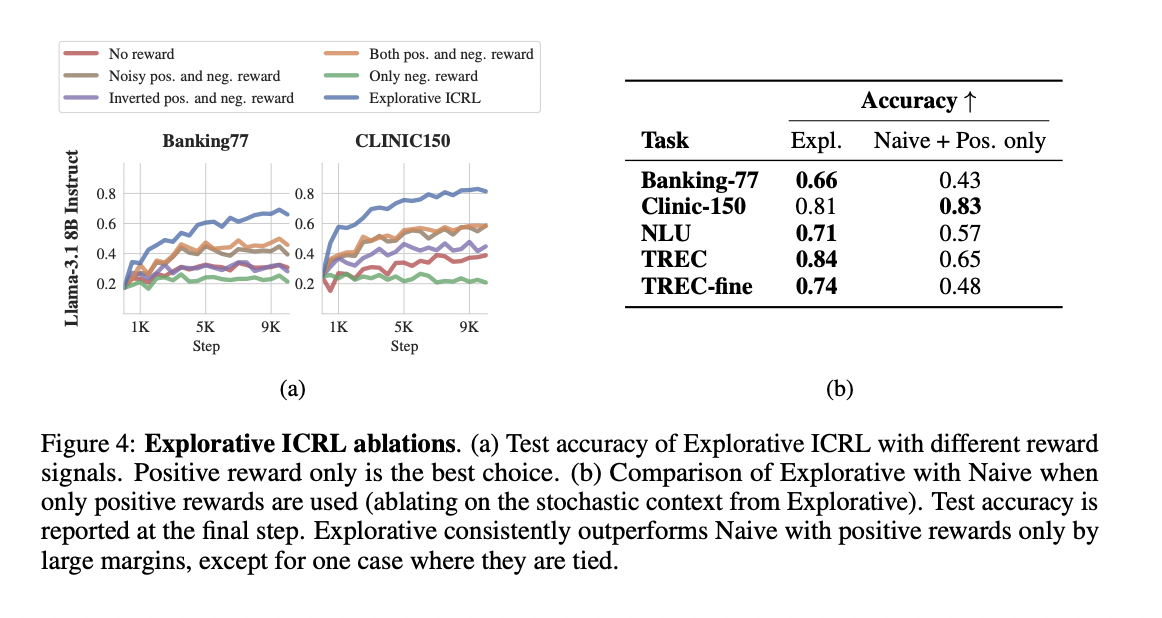
This research demonstrates the potential of LLMs to realize ICRL. The study presents three algorithms: naive, exploratory and approximate ICRL. While the naive approach fails due to poor exploration, the exploratory method successfully introduces stochasticity into fast construction and focuses on positive examples, leading to consistent ICRL performance. The approximate method addresses the high computational costs of exploratory ICRL by providing a balance between efficiency and robustness.
The study findings highlight the importance of exploration in ICRL and the effectiveness of stochastic fast construction. However, the researchers recognize several limitations and areas for future work. These include the need to investigate ICRL in more complex problem domains beyond classification, explore the use of nuanced reward signals beyond binary feedback, and address the challenge of reasoning about episodes with negative rewards.
In addition to this, the computational intensity of the proposed methods, especially as the number of observed episodes increases, presents an ongoing challenge. While the approximate method offers a partial solution, questions remain about the optimization of ICRL for limited context windows and extended interactions. These limitations outline crucial directions for future research to advance the field of reinforcement learning in context with LLM.
look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 50,000ml
(Next Event: Oct 17, 202) RetrieveX – The GenAI Data Recovery Conference (Promoted)
Asjad is an internal consultant at Marktechpost. He is pursuing B.tech in Mechanical Engineering from Indian Institute of technology, Kharagpur. Asjad is a machine learning and deep learning enthusiast who is always researching applications of machine learning in healthcare.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}