
Today, we are excited to announce that the first model in the next generation Falcon 2 family, the Falcon 2 11B foundation model (FM) from technology Innovation Institute (TII), is available through amazon SageMaker JumpStart to deploy and run inference.
Falcon 2 11B is a trained dense decoder model on a 5.5 trillion token dataset and supports multiple languages. The Falcon 2 11B model is available on SageMaker JumpStart, a machine learning (ML) hub that provides access to built-in algorithms, FMs, and pre-built ML solutions that you can deploy quickly and get started with ML faster.
In this post, we walk through how to discover, deploy, and run inference on the Falcon 2 11B model using SageMaker JumpStart.
What is the Falcon 2 11B model
Falcon 2 11B is the first FM released by TII under their new artificial intelligence (ai) model series Falcon 2. It’s a next generation model in the Falcon family—a more efficient and accessible large language model (LLM) that is trained on a 5.5 trillion token dataset primarily consisting of web data from RefinedWeb with 11 billion parameters. It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. It’s equipped with multilingual capabilities and can seamlessly tackle tasks in English, French, Spanish, German, Portuguese, and other languages for diverse scenarios.
Falcon 2 11B is a raw, pre-trained model, which can be a foundation for more specialized tasks, and also allows you to fine-tune the model for specific use cases such as summarization, text generation, chatbots, and more.
Falcon 2 11B is supported by the SageMaker TGI Deep Learning Container (DLC) which is powered by Text Generation Inference (TGI), an open source, purpose-built solution for deploying and serving LLMs that enables high-performance text generation using tensor parallelism and dynamic batching.
The model is available under the TII Falcon License 2.0, the permissive Apache 2.0-based software license, which includes an acceptable use policy that promotes the responsible use of ai.
What is SageMaker JumpStart
SageMaker JumpStart is a powerful feature within the SageMaker ML platform that provides ML practitioners a comprehensive hub of publicly available and proprietary FMs. With this managed service, ML practitioners get access to a growing list of cutting-edge models from leading model hubs and providers that they can deploy to dedicated SageMaker instances within a network isolated environment, and customize models using SageMaker for model training and deployment.
You can discover and deploy the Falcon 2 11B model with a few clicks in amazon SageMaker Studio or programmatically through the SageMaker Python SDK, enabling you to derive model performance and MLOps controls with SageMaker features such as amazon SageMaker Pipelines, amazon SageMaker Debugger, or container logs. The Falcon 2 11B model is available today for inferencing from 22 AWS Regions where SageMaker JumpStart is available. Falcon 2 11B will require g5 and p4 instances.
Prerequisites
To try out the Falcon 2 model using SageMaker JumpStart, you need the following prerequisites:
- An AWS account that will contain all your AWS resources.
- An AWS Identity and Access Management (IAM) role to access SageMaker. To learn more about how IAM works with SageMaker, refer to Identity and Access Management for amazon SageMaker.
- Access to SageMaker Studio or a SageMaker notebook instance or an interactive development environment (IDE) such as PyCharm or Visual Studio Code. We recommend using SageMaker Studio for straightforward deployment and inference.
Discover Falcon 2 11B in SageMaker JumpStart
You can access the FMs through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. In this section, we go over how to discover the models in SageMaker Studio.
SageMaker Studio is an IDE that provides a single web-based visual interface where you can access purpose-built tools to perform all ML development steps, from preparing data to building, training, and deploying your ML models. For more details on how to get started and set up SageMaker Studio, refer to amazon SageMaker Studio.
In SageMaker Studio, you can access SageMaker JumpStart by choosing JumpStart in the navigation pane or by choosing JumpStart from the Home page.
From the SageMaker JumpStart landing page, you can find pre-trained models from the most popular model hubs. You can search for Falcon in the search box. The search results will list the Falcon 2 11B text generation model and other Falcon model variants available.
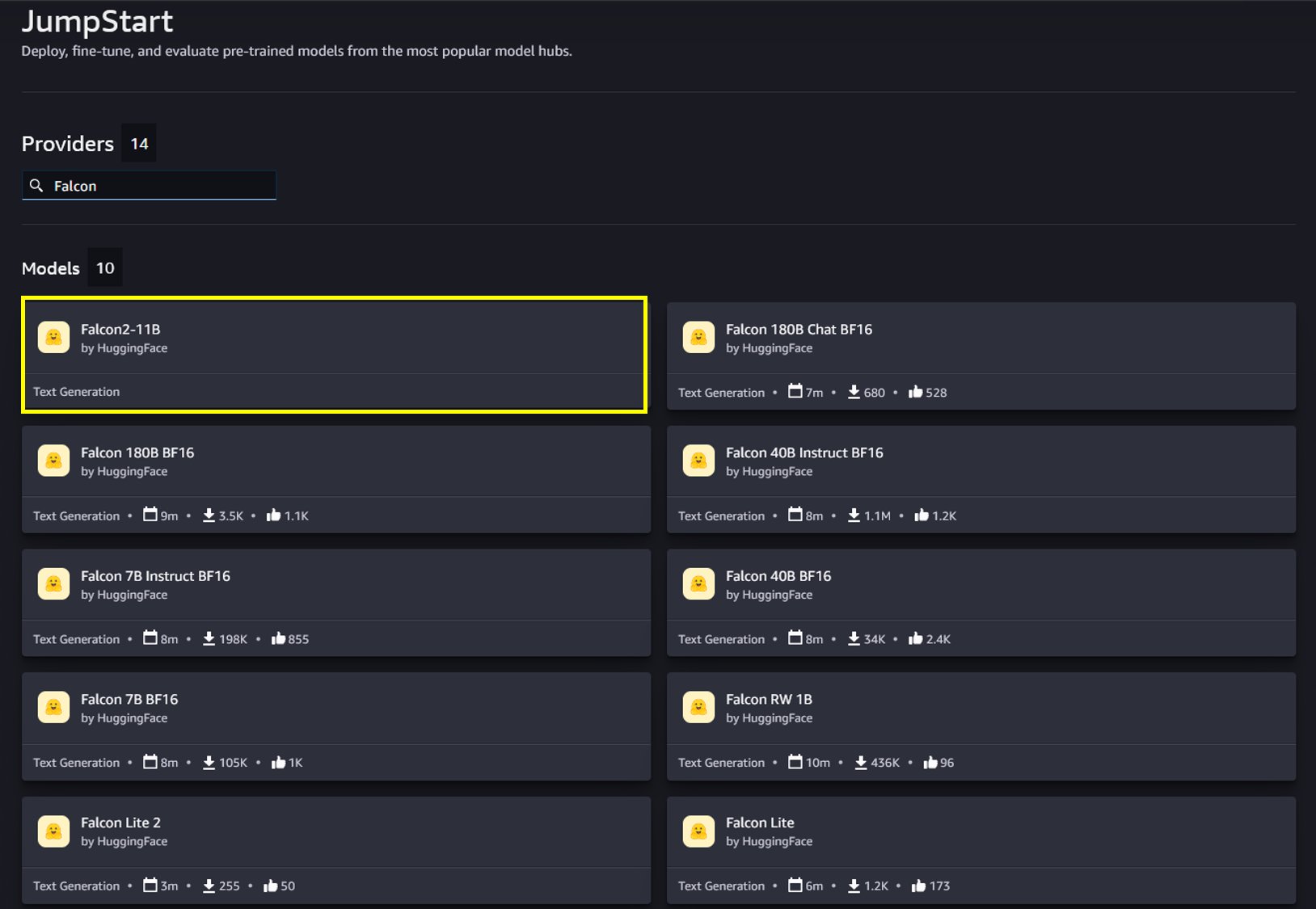
You can choose the model card to view details about the model such as license, data used to train, and how to use the model. You will also find two options, Deploy and Preview notebooks, to deploy the model and create an endpoint.
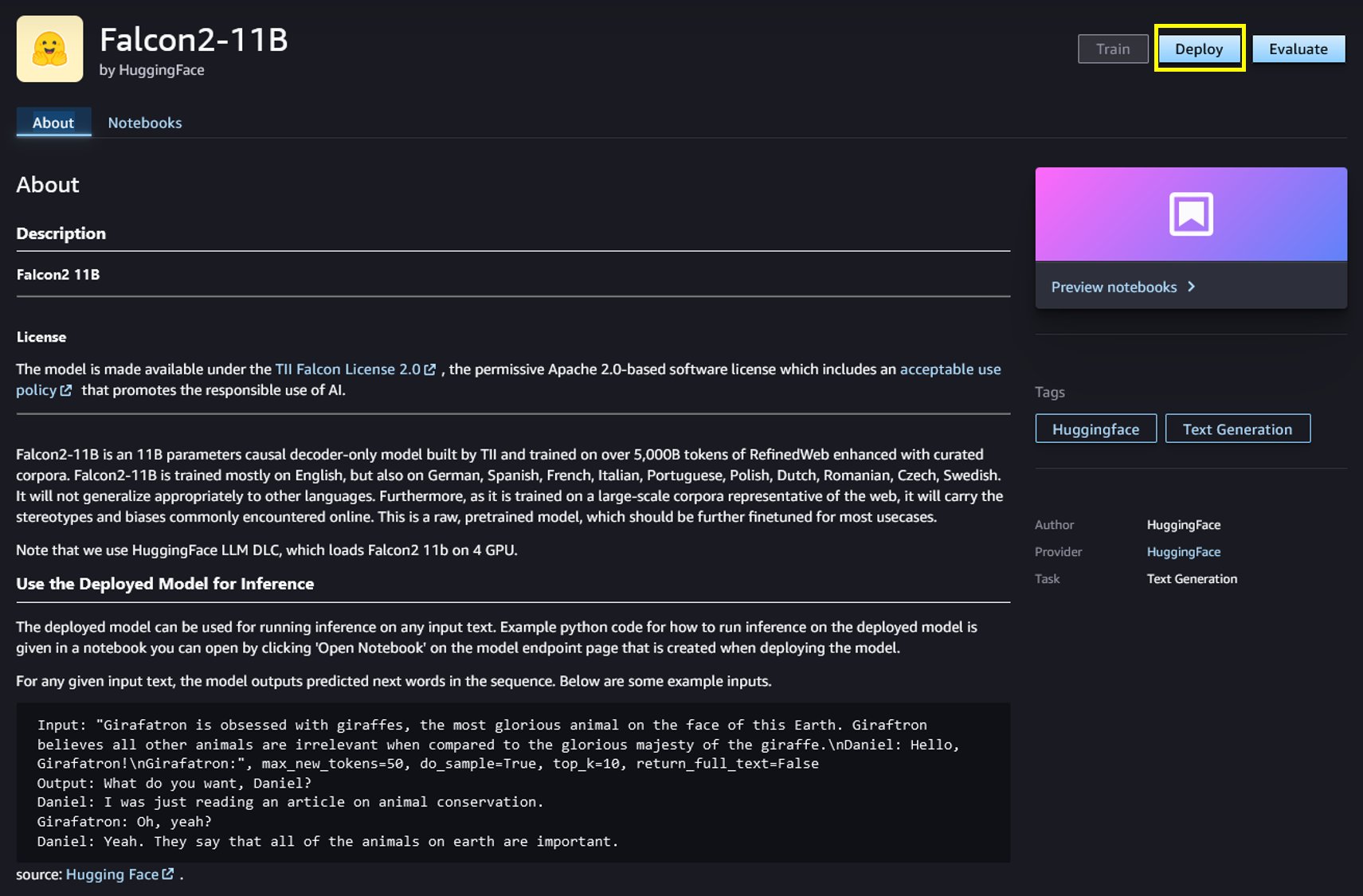
Deploy the model in SageMaker JumpStart
Deployment starts when you choose Deploy. SageMaker performs the deploy operations on your behalf using the IAM SageMaker role assigned in the deployment configurations. After deployment is complete, you will see that an endpoint is created. You can test the endpoint by passing a sample inference request payload or by selecting the testing option using the SDK. When you use the SDK, you will see example code that you can use in the notebook editor of your choice in SageMaker Studio.
Falcon 2 11B text generation
To deploy using the SDK, we start by selecting the Falcon 2 11B model, specified by the model_id with value huggingface-llm-falcon2-11b. You can deploy any of the selected models on SageMaker with the following code. Similarly, you can deploy the Falcon 2 11B LLM using its own model ID.
This deploys the model on SageMaker with default configurations, including the default instance type and default VPC configurations. You can change these configurations by specifying non-default values in JumpStartModel. The recommended instance types for this model endpoint usage are ml.g5.12xlarge, ml.g5.24xlarge, ml.g5.48xlarge, or ml.p4d.24xlarge. Make sure you have the account-level service limit for one or more of these instance types to deploy this model. For more information, refer to Requesting a quota increase.
After it is deployed, you can run inference against the deployed endpoint through the SageMaker predictor:
Example prompts
You can interact with the Falcon 2 11B model like any standard text generation model, where the model processes an input sequence and outputs predicted next words in the sequence. In this section, we provide some example prompts and sample output.
Text generation
The following is an example prompt for text generated by the model:
The following is the output:
Code generation
Using the preceding example, we can use code generation prompts as follows:
The code uses Falcon 2 11B to generate a Python function that writes a JSON file. It defines a payload dictionary with the input prompt "Write a function in Python to write a json file:" and some parameters to control the generation process, like the maximum number of tokens to generate and whether to enable sampling. It then sends this payload to a predictor (likely an API), receives the generated text response, and prints it to the console. The printed output should be the Python function for writing a JSON file, as requested in the prompt.
The following is the output:
The output from the code generation defines the write_json_file that takes the file name and a Python object and writes the object as JSON data. Falcon 2 11B uses the built-in JSON module and handles exceptions. An example usage is provided at the bottom, writing a dictionary with name, age, and city keys to a file named data.json. The output shows the expected JSON file content, illustrating the model’s natural language processing (NLP) and code generation capabilities.
Sentiment analysis
You can perform sentiment analysis using a prompt like the following with Falcon 2 11B:
The following is the output:
The code for sentiment analysis demonstrates using Falcon 2 11B to provide examples of tweets with their corresponding sentiment labels (positive, negative, neutral). The last tweet (“I love spending time with my family”) is left without a sentiment to prompt the model to generate the classification itself. The max_new_tokens parameter is set to 2, indicating that the model should generate a short output, likely just the sentiment label. With do_sample set to true, the model can sample from its output distribution, potentially leading to better results for sentiment tasks. Classification based on text inputs and patterns learned from previous examples is what teaches this model to output the desired and accurate response.
Question answering
You can also use a question answering prompt like the following with Falcon 2 11B:
The following is the output:
The user sends an input question or prompt to Falcon 2 11B, along with parameters like the maximum number of tokens to generate and whether to enable sampling. The model then generates a relevant response based on its understanding of the question and its training data. After the initial response, a follow-up question is asked, and the model provides another answer, showcasing its ability to engage in a conversational question-answering process.
Multilingual capabilities
You can use languages such as German, Spanish, French, Italian, Portuguese, Polish, Dutch, Romanian, Czech, and Swedish with Falcon 2 11B. In the following code, we demonstrate the model’s multilingual capabilities:
The following is the output:
Mathematics and reasoning
Falcon 2 11B models also report strength in mathematic accuracy:
The following is the output:
The code shows Falcon 2 11B’s capability to comprehend natural language prompts involving mathematical reasoning, break them down into logical steps, and generate human-like explanations and solutions.
Clean up
After you’re done running the notebook, delete all the resources you created in the process so your billing is stopped. Use the following code:
Conclusion
In this post, we showed you how to get started with Falcon 2 11B in SageMaker Studio and deploy the model for inference. Because FMs are pre-trained, they can help lower training and infrastructure costs and enable customization for your use case.
Visit SageMaker JumpStart in SageMaker Studio now to get started. For more information, refer to SageMaker JumpStart, JumpStart Foundation Models, and Getting started with amazon SageMaker JumpStart.
About the Authors
 Supriya Puragundla is a Senior Solutions Architect at AWS. She helps key customer accounts on their generative ai and ai/ML journeys. She is passionate about data-driven ai and the area of depth in ML and generative ai.
Supriya Puragundla is a Senior Solutions Architect at AWS. She helps key customer accounts on their generative ai and ai/ML journeys. She is passionate about data-driven ai and the area of depth in ML and generative ai.
 Armando Diaz is a Solutions Architect at AWS. He focuses on generative ai, ai/ML, and data analytics. At AWS, Armando helps customers integrate cutting-edge generative ai capabilities into their systems, fostering innovation and competitive advantage. When he’s not at work, he enjoys spending time with his wife and family, hiking, and traveling the world.
Armando Diaz is a Solutions Architect at AWS. He focuses on generative ai, ai/ML, and data analytics. At AWS, Armando helps customers integrate cutting-edge generative ai capabilities into their systems, fostering innovation and competitive advantage. When he’s not at work, he enjoys spending time with his wife and family, hiking, and traveling the world.
 Niithiyn Vijeaswaran is an Enterprise Solutions Architect at AWS. His area of focus is generative ai and AWS ai Accelerators. He holds a Bachelor’s degree in Computer Science and Bioinformatics. Niithiyn works closely with the Generative ai GTM team to enable AWS customers on multiple fronts and accelerate their adoption of generative ai. He’s an avid fan of the Dallas Mavericks and enjoys collecting sneakers.
Niithiyn Vijeaswaran is an Enterprise Solutions Architect at AWS. His area of focus is generative ai and AWS ai Accelerators. He holds a Bachelor’s degree in Computer Science and Bioinformatics. Niithiyn works closely with the Generative ai GTM team to enable AWS customers on multiple fronts and accelerate their adoption of generative ai. He’s an avid fan of the Dallas Mavericks and enjoys collecting sneakers.
 Avan Bala is a Solutions Architect at AWS. His area of focus is ai for DevOps and machine learning. He holds a Bachelor’s degree in Computer Science with a minor in Mathematics and Statistics from the University of Maryland. Avan is currently working with the Enterprise Engaged East Team and likes to specialize in projects about emerging ai technology. When not working, he likes to play basketball, go on hikes, and try new foods around the country.
Avan Bala is a Solutions Architect at AWS. His area of focus is ai for DevOps and machine learning. He holds a Bachelor’s degree in Computer Science with a minor in Mathematics and Statistics from the University of Maryland. Avan is currently working with the Enterprise Engaged East Team and likes to specialize in projects about emerging ai technology. When not working, he likes to play basketball, go on hikes, and try new foods around the country.
 Dr. Farooq Sabir is a Senior artificial intelligence and Machine Learning Specialist Solutions Architect at AWS. He holds PhD and MS degrees in Electrical Engineering from the University of Texas at Austin and an MS in Computer Science from Georgia Institute of technology. He has over 15 years of work experience and also likes to teach and mentor college students. At AWS, he helps customers formulate and solve their business problems in data science, machine learning, computer vision, artificial intelligence, numerical optimization, and related domains. Based in Dallas, Texas, he and his family love to travel and go on long road trips.
Dr. Farooq Sabir is a Senior artificial intelligence and Machine Learning Specialist Solutions Architect at AWS. He holds PhD and MS degrees in Electrical Engineering from the University of Texas at Austin and an MS in Computer Science from Georgia Institute of technology. He has over 15 years of work experience and also likes to teach and mentor college students. At AWS, he helps customers formulate and solve their business problems in data science, machine learning, computer vision, artificial intelligence, numerical optimization, and related domains. Based in Dallas, Texas, he and his family love to travel and go on long road trips.
 Hemant Singh is an Applied Scientist with experience in amazon SageMaker JumpStart. He got his master’s from Courant Institute of Mathematical Sciences and B.tech from IIT Delhi. He has experience in working on a diverse range of machine learning problems within the domain of natural language processing, computer vision, and time series analysis.
Hemant Singh is an Applied Scientist with experience in amazon SageMaker JumpStart. He got his master’s from Courant Institute of Mathematical Sciences and B.tech from IIT Delhi. He has experience in working on a diverse range of machine learning problems within the domain of natural language processing, computer vision, and time series analysis.






{kind=link}