
Introducción
A la hora de asistir a una entrevista de trabajo o contratar para una gran empresa, revisar cada CV en detalle muchas veces resulta poco práctico debido al gran volumen de solicitantes. En cambio, aprovechar la extracción de datos del CV para centrarse en qué tan bien se alinean los requisitos laborales clave con el CV de un candidato puede conducir a una coincidencia exitosa tanto para el empleador como para el candidato.
Imagínese que revisen la etiqueta de su perfil: ¡no se preocupe! Ahora es fácil evaluar su idoneidad para un puesto e identificar cualquier brecha en sus calificaciones en relación con los requisitos laborales.
Por ejemplo, si una oferta de trabajo destaca la experiencia en gestión de proyectos y el dominio de un software específico, el candidato debe asegurarse de que estas habilidades estén claramente visibles en su CV. Este enfoque específico ayuda a los gerentes de contratación a identificar rápidamente a los solicitantes calificados y garantiza que el candidato sea considerado para puestos en los que pueda prosperar.
Al enfatizar las calificaciones más relevantes, el proceso de contratación se vuelve más eficiente y ambas partes pueden beneficiarse de una buena combinación. La empresa encuentra el talento adecuado más rápidamente y es más probable que el candidato consiga un puesto que se ajuste a sus habilidades y experiencia.
Resultados de aprendizaje
- Comprender la importancia de la extracción de datos de los CV para la automatización y el análisis.
- Adquiera competencia en el uso de bibliotecas de Python para la extracción de texto de varios formatos de archivo.
- Aprenda a preprocesar imágenes para mejorar la precisión de la extracción de texto.
- Explore técnicas para manejar la distinción entre mayúsculas y minúsculas y normalizar tokens en texto extraído.
- Identifique herramientas y bibliotecas clave esenciales para una extracción eficaz de datos de CV.
- Desarrolle habilidades prácticas para extraer texto tanto de imágenes como de archivos PDF.
- Reconocer los desafíos involucrados en la extracción de datos de CV y las soluciones efectivas.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Para extraer datos de forma eficaz de currículums y CV, aprovechar las herramientas adecuadas es esencial para agilizar el proceso y garantizar la precisión. Esta sección destacará bibliotecas y tecnologías clave que mejoran la eficiencia de la extracción de datos de CV, permitiendo mejores análisis e información de los perfiles de los candidatos.
Pitón
Tiene una biblioteca o método que puede dividir oraciones o párrafos en palabras. En Python, puede lograr la tokenización de palabras utilizando diferentes bibliotecas y métodos, como split() (tokenización básica) o las bibliotecas Natural Language Toolkit (NLTK) y spaCy para una tokenización más avanzada.
La tokenización simple (división de oraciones) no reconoce puntuaciones ni otros caracteres especiales.
sentences="Today is a beautiful day!."
sentences.split()
('Today', 'is', 'a', 'beautiful', 'day!.')Bibliotecas: NLTK y SpaCy
Python tiene una herramienta más poderosa para la tokenización (Natural Language Toolkit (NLTK).
En NLTK (Natural Language Toolkit), el tokenizador de punkt tokeniza activamente el texto mediante el uso de un modelo previamente entrenado para la división de oraciones y la tokenización de palabras sin supervisión.
import nltk
nltk.download('punkt')
from nltk import word_tokenize
sentences="Today is a beautiful day!."
sentences.split()
print(sentences)
words= word_tokenize(sentences)
print(words)
(nltk_data) Downloading package punkt to
(nltk_data) C:\Users\ss529\AppData\Roaming\nltk_data...
Today is a beautiful day!.
('Today', 'is', 'a', 'beautiful', 'day', '!', '.')
(nltk_data) Package punkt is already up-to-date!Características clave de punkt:
- Puede convertir un texto determinado en oraciones y palabras sin necesidad de información previa sobre la gramática o sintaxis del idioma.
- Utiliza modelos de aprendizaje automático para detectar límites de oraciones, lo cual es útil en idiomas donde la puntuación no separa estrictamente las oraciones.
SpaCy es una biblioteca avanzada de PNL que ofrece tokenización precisa y otras funciones de procesamiento del lenguaje.
Expresiones regulares: tokenización personalizada basada en patrones, pero requiere configuración manual.
import re
regular= "(A-za-z)+(\W)?"
re.findall(regular, sentences)
('Today ', 'is ', 'a ', 'beautiful ', 'day!')Pytesseract
Es una herramienta de reconocimiento óptico de caracteres basada en Python que se utiliza para leer texto en imágenes.
Biblioteca de almohadas
Una biblioteca de código abierto para manejar varios formatos de imágenes, útil para la manipulación de imágenes.
Imágenes o archivos PDF
Los currículums pueden estar en formato PDF o imagen.
PDFPlumber o PyPDF2
Para extraer texto de un PDF y convertirlo en palabras, puedes seguir estos pasos en Python:
- Extraiga texto de un PDF utilizando una biblioteca como PyPDF2 o pdfplomber.
- Tokenice el texto extraído utilizando cualquier método de tokenización, como split(), NLTK o spaCy.
Obtener palabras de archivos PDF o imágenes
Para archivos pdf necesitaremos Pdf Plumber y para imágenes OCR.
Si desea extraer texto de una imagen (en lugar de un PDF) y luego tokenizar y calificar según palabras predefinidas para diferentes campos, puede lograrlo siguiendo estos pasos:
Instale la máquina OCR pytesseract.
Ayudará a extraer texto de imágenes.
pip install pytesseract Pillow nltkInstalar la almohada de la biblioteca
Ayudará a manejar varias imágenes.
Cuando se trata de procesamiento y manipulación de imágenes en Python, como cambiar el tamaño, recortar o convertir entre diferentes formatos, la biblioteca de código abierto que a menudo me viene a la mente es Pillow.
Veamos cómo funciona la almohada, para ver la imagen en Jupyter Notebook tengo que usar la pantalla y dentro de los corchetes tengo que almacenar la variable que contiene la imagen.
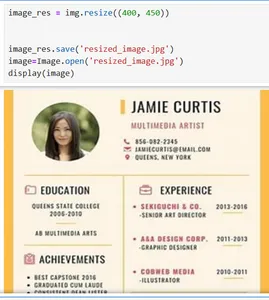
from PIL import Image
image = Image.open('art.jfif')
display(image)
Para cambiar el tamaño y guardar la imagen, se utiliza el método de cambio de tamaño y guardado, el ancho se establece en 400 y el alto en 450.
Características clave de la almohada:
- Formatos de imagen: admite diferentes formatos
- Funciones de manipulación de imágenes: se pueden cambiar el tamaño, recortar imágenes, convertir imágenes en color a grises, etc.
Instale nltk para tokenización (o spaCy)
Descubra cómo mejorar sus capacidades de procesamiento de texto instalando NLTK o spaCy, dos potentes bibliotecas para la tokenización en el procesamiento del lenguaje natural.
Descargar Tesseract y configurar la ruta
Aprenda cómo descargar Tesseract desde GitHub e integrarlo perfectamente en su secuencia de comandos agregando la ruta necesaria para una funcionalidad OCR optimizada.
pytesseract.pytesseract.tesseract_cmd = 'C:\Program Files\Tesseract-OCR\tesseract.exe''- macOS: instalación de cerveza tesseract
- Linux: instale a través del administrador de paquetes (por ejemplo, sudo apt install tesseract-ocr).
- pip instalar pytesseract Almohada
Hay varias herramientas, entre ellas, la biblioteca de código abierto Tesseract, desarrollada por Google, que admite muchos idiomas y OCR.
Pytesseract se utiliza para proyectos basados en Python, que actúan como contenedor para el motor Tesseract OCR.
Técnicas de extracción de imágenes y texto PDF
En la era digital, extraer texto de imágenes y archivos PDF se ha vuelto esencial para diversas aplicaciones, incluido el análisis de datos y el procesamiento de documentos. Este artículo explora técnicas efectivas para preprocesar imágenes y aprovechar bibliotecas potentes para mejorar el reconocimiento óptico de caracteres (OCR) y agilizar la extracción de texto de diversos formatos de archivos.
Preprocesamiento de imágenes para mejorar el rendimiento del OCR
El preprocesamiento de imágenes puede mejorar el rendimiento del OCR siguiendo los pasos que se mencionan a continuación.
- Imágenes a escala de grises: las imágenes se convierten a escala de grises para reducir el ruido del fondo y tener un enfoque firme en el texto mismo, y es útil para imágenes con diferentes condiciones de iluminación.
- desde PIL importar ImageOps
- imagen = ImageOps.escala de grises(imagen)
- Umbral: aplique un umbral binario para hacer que el texto se destaque al convertir la imagen a un formato en blanco y negro.
- Cambio de tamaño: mejora las imágenes más pequeñas para un mejor reconocimiento del texto.
- Eliminación de ruido: elimine el ruido o los artefactos en la imagen usando filtros (por ejemplo, desenfoque gaussiano).
import nltk
import pytesseract
from PIL import Image
import cv2
from nltk.tokenize import word_tokenize
nltk.download('punkt')
pytesseract.pytesseract.tesseract_cmd = r'C:\Users\ss529\anaconda3\Tesseract-OCR\tesseract.exe'
image = input("Name of the file: ")
imag=cv2.imread(image)
#convert to grayscale image
gray=cv2.cvtColor(images, cv2.COLOR_BGR2GRAY)
from nltk.tokenize import word_tokenize
def text_from_image(image):
img = Image.open(imag)
text = pytesseract.image_to_string(img)
return text
image="CV1.png"
text1 = text_from_image(image)
# Tokenize the extracted text
tokens = word_tokenize(text1)
print(tokens)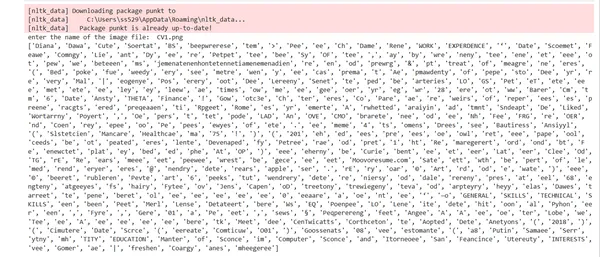
Para saber cuántas palabras coinciden con los requisitos, compararemos y daremos puntos a cada palabra coincidente como 10.
# Comparing tokens with specific words, ignore duplicates, and calculate score
def compare_tokens_and_score(tokens, specific_words, score_per_match=10):
match_words = set(word.lower() for word in tokens if word.lower() in specific_words)
total_score = len(fields_keywords) * score_per_match
return total_score
# Fields with differents skills
fields_keywords = {
"Data_Science_Carrier": { 'supervised machine learning', 'Unsupervised machine learning', 'data','analysis', 'statistics','Python'},
}
# Score based on specific words for that field
def process_image_for_field(image, field):
if field not in fields_keywords:
print(f"Field '{field}' is not defined.")
return
# Extract text from the image
text = text_from_image(image)
# Tokenize the extracted text
tokens = tokenize_text(text)
# Compare tokens with specific words for the selected field
specific_words = fields_keywords(field)
total_score = compare_tokens_and_score(tokens, specific_words)
print(f"Field: {field}")
print("Total Score:", total_score)
image="CV1.png"
field = 'Data_Science_Carrier' Para manejar la distinción entre mayúsculas y minúsculas, por ejemplo, “ciencia de datos” frente a “ciencia de datos”, podemos convertir todos los tokens y palabras clave a minúsculas.
tokens = word_tokenize(extracted_text.lower())Con el uso de lematización con bibliotecas de PNL como NLTK o derivación con spaCy para reducir palabras (por ejemplo, “ejecutar” a “ejecutar”)
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
def normalize_tokens(tokens):
return (lemmatizer.lemmatize(token.lower()) for token in tokens)
Obtener texto de archivos PDF
Exploremos ahora las acciones necesarias para obtener texto de archivos PDF.
Instalar las bibliotecas necesarias
Necesitará las siguientes bibliotecas:
- PyPDF2
- pdffontanero
- espacioso
- ntk
Usando pepita
pip install PyPDF2 pdfplumber nltk spacy
python -m spacy download en_core_web_smimport PyPDF2
def text_from_pdf(pdf_file):
with open(pdf_file, 'rb') as file:
reader = PyPDF2.PdfReader(file)
text = ""
for page_num in range(len(reader.pages)):
page = reader.pages(page_num)
text += page.extract_text() + "\n"
return textimport pdfplumber
def text_from_pdf(pdf_file):
with pdfplumber.open(pdf_file) as pdf:
text = ""
for page in pdf.pages:
text += page.extract_text() + "\n"
return text
pdf_file="SoniaSingla-DataScience-Bio.pdf"
# Extract text from the PDF
text = text_from_pdf(pdf_file)
# Tokenize the extracted text
tokens = word_tokenize(text)
print(tokens) Normalizar tokens para lograr coherencia
Para manejar el archivo PDF en lugar de una imagen y garantizar que las palabras repetidas no reciban múltiples puntuaciones, modifique el código anterior. Extraeremos texto del archivo PDF, lo tokenizaremos y compararemos los tokens con palabras específicas de diferentes campos. El código calculará la puntuación en función de palabras coincidentes únicas.
import pdfplumber
import nltk
from nltk.tokenize import word_tokenize
nltk.download('punkt')
def extract_text_from_pdf(pdf_file):
with pdfplumber.open(pdf_file) as pdf:
text = ""
for page in pdf.pages:
text += page.extract_text() + "\n"
return text
def tokenize_text(text):
tokens = word_tokenize(text)
return tokens
def compare_tokens_and_score(tokens, specific_words, score_per_match=10):
# Use a set to store unique matched words to prevent duplicates
unique_matched_words = set(word.lower() for word in tokens if word.lower() in specific_words)
# Calculate total score based on unique matches
total_score = len(unique_matched_words) * score_per_match
return unique_matched_words, total_score
# Define sets of specific words for different fields
fields_keywords = {
"Data_Science_Carrier": { 'supervised machine learning', 'Unsupervised machine learning', 'data','analysis', 'statistics','Python'},
# Add more fields and keywords here
}
# Step 4: Select the field and calculate the score based on specific words for that field
def process_pdf_for_field(pdf_file, field):
if field not in fields_keywords:
print(f"Field '{field}' is not defined.")
return
text = extract_text_from_pdf(pdf_file)
tokens = tokenize_text(text)
specific_words = fields_keywords(field)
unique_matched_words, total_score = compare_tokens_and_score(tokens, specific_words)
print(f"Field: {field}")
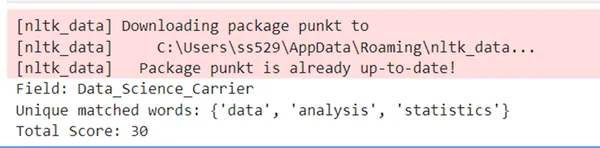
print("Unique matched words:", unique_matched_words)
print("Total Score:", total_score)
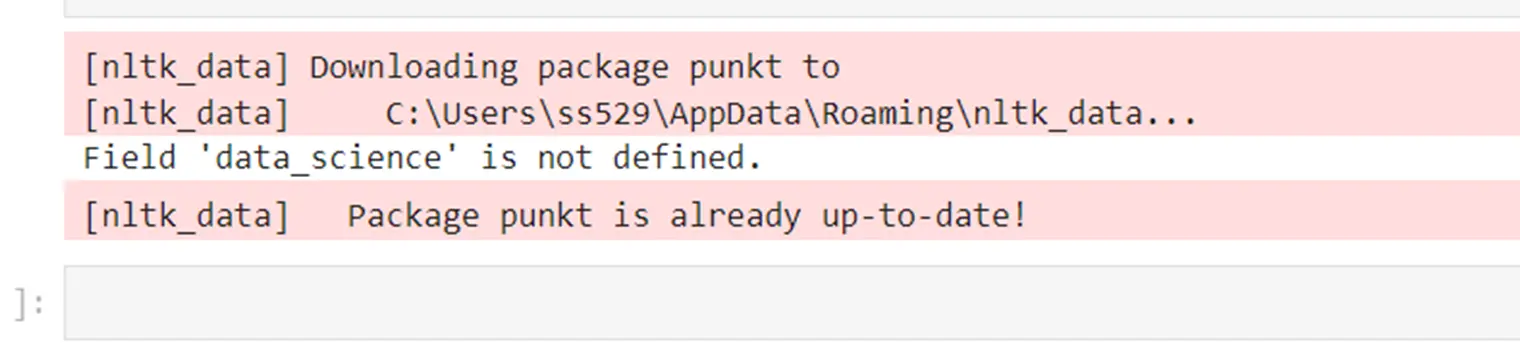
pdf_file="SoniaSingla-DataScience-Bio.pdf"
field = 'data_science'
process_pdf_for_field(pdf_file, fieProducirá un mensaje de error ya que el campo data_science no está definido.
Cuando se elimina el error, funciona bien.
Para manejar correctamente la distinción entre mayúsculas y minúsculas y garantizar que palabras como “datos” y “Datos” se consideren la misma palabra y al mismo tiempo puntuarla solo una vez (incluso si aparece varias veces con diferentes casos), puede normalizar el uso de mayúsculas y minúsculas tanto de los tokens como de los tokens. las palabras específicas. Podemos hacer esto convirtiendo tanto los tokens como las palabras específicas a minúsculas durante la comparación, pero aún conservando la mayúscula original para la salida final de las palabras coincidentes.
- Usando pdfplomber para extraer el texto del archivo pdf.
- Usar OCR para convertir imágenes en código de máquina.
- Uso de pytesseract para convertir códigos de ajuste de Python en texto.
Conclusión
Exploramos el proceso crucial de extracción y análisis de datos de CV, centrándonos en técnicas de automatización utilizando Python. Aprendimos a utilizar bibliotecas esenciales como NLTK, SpaCy, Pytesseract y Pillow para la extracción eficaz de texto de varios formatos de archivos, incluidos PDF e imágenes. Al aplicar métodos de tokenización, normalización de texto y puntuación, obtuvimos información sobre cómo alinear las calificaciones de los candidatos con los requisitos laborales de manera eficiente. Este enfoque sistemático no sólo agiliza el proceso de contratación para los empleadores sino que también mejora las posibilidades de los candidatos de conseguir puestos que coincidan con sus habilidades.
Conclusiones clave
- La extracción eficiente de datos de los CV es vital para automatizar el proceso de contratación.
- Herramientas como NLTK, SpaCy, Pytesseract y Pillow son esenciales para la extracción y el procesamiento de texto.
- Los métodos de tokenización adecuados ayudan a analizar con precisión el contenido de los CV.
- La implementación de un mecanismo de puntuación basado en palabras clave mejora el proceso de coincidencia entre los candidatos y los requisitos laborales.
- La normalización de tokens mediante técnicas como la lematización mejora la precisión del análisis de texto.
Preguntas frecuentes
A. Bibliotecas PyPDF2 o pdfplomber para extraer texto de un pdf.
R. Si el CV está en formato de imagen (documento escaneado o foto), puede utilizar OCR (Reconocimiento óptico de caracteres) para extraer texto de la imagen. La herramienta más utilizada para esto en Python es pytesseract, que es un contenedor para Tesseract OCR.
R. Mejorar la calidad de las imágenes antes de introducirlas en OCR puede aumentar significativamente la precisión de la extracción de texto. Técnicas como la conversión en escala de grises, el establecimiento de umbrales y la reducción de ruido utilizando herramientas como OpenCV pueden ayudar.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.

He realizado mi Maestría en Ciencias en Biotecnología y Maestría en Ciencias en Bioinformática en universidades de renombre. He escrito algunos artículos de investigación, los revisé y actualmente soy miembro del Consejo Editorial Asesor del IJPBS. Espero las oportunidades en TI para utilizar mis habilidades adquiridas durante el trabajo y la pasantía. https://aster28.github.io/SoniaSinglaBio/site/





