
Large language models (LLMs) have revolutionized ai by demonstrating success in natural language tasks and beyond, as exemplified by ChatGPT, Bard, Claude, etc. These LLMs can produce texts ranging from creative writing to complex code. However, LLMs face challenges such as hallucinations, outdated knowledge, and non-transparent and untraceable reasoning processes. Recovery Augmented Generation (RAG) has emerged as a promising solution that incorporates insights from external databases. This improves the accuracy and credibility of generation, particularly for knowledge-intensive tasks, and allows for continuous knowledge updates and integration of domain-specific information.
RAG improves LLMs by retrieving relevant document fragments from the external knowledge base by calculating semantic similarity. By referencing external knowledge, RAG effectively reduces the problem of generating objectively incorrect content. Its integration into LLMs has resulted in widespread adoption, establishing RAG as a key technology for advancing chatbots and improving the suitability of LLMs for real-world applications. When users ask a question to an LLM, the ai model sends the query to another model that converts it to a numerical format so machines can read it. The numerical version of the query is sometimes called an embedding or a vector. RAG combines LLM with integrated models and vector databases. The embedding model then compares these numerical values to vectors in a machine-readable index of an available knowledge base. When it finds one or more matches, it retrieves the related data, converts it into human-readable words, and returns it to the LLM. Finally, the LLM combines the retrieved words and their response to the query into a final response that it presents to the user, potentially citing sources found by the embedding model.
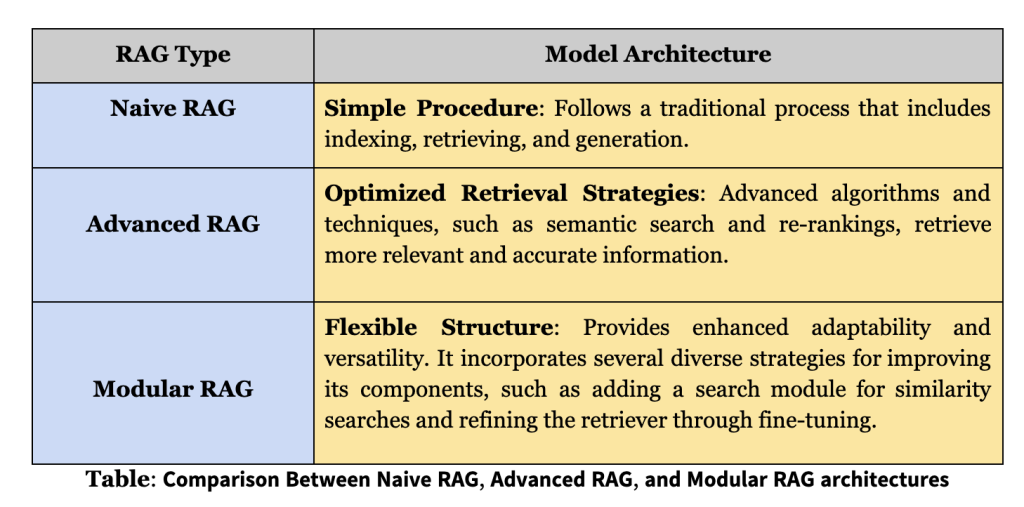
The RAG research paradigm is continually evolving and RAG is classified into three stages: naive RAG, advanced RAG, and modular RAG. Although the RAG method is cost-effective and outperforms native LLM, it also has several limitations. The development of Advanced RAG and Modular RAG is an innovation in RAG to overcome these specific shortcomings in Naive RAG.

Naive RAG: The Naive RAG research paradigm represents the oldest methodology, which gained prominence shortly after the widespread adoption of ChatGPT. Naive RAG follows a traditional process that includes indexing, retrieval and generation, also characterized as a “Retrieve-Read” framework. Indexing begins with cleaning and extracting raw data into various formats such as PDF, HTML, Word, and Markdown, which are then converted to a uniform plain text format. Retrieval: Upon receiving a user query, the RAG system uses the same encoding model used during the indexing phase to transform the query into a vector representation. It then calculates similarity scores between the query vector and the fragment vector within the indexed corpus. The system prioritizes and retrieves the top K snippets, demonstrating the highest similarity to the query. These fragments are later used as expanded context in the message. Generation: The query posed and the selected documents are synthesized into a coherent message, for which an LLM is tasked with formulating a response.
However, Naive RAG encounters notable drawbacks: recovery challenges; The retrieval phase often has problems with precision and recall, leading to the selection of misaligned or irrelevant fragments and missing crucial information. Generation difficulties: When generating responses, the model may face the problem of hallucination, producing content that is not supported by the recovered context. Rising Obstacles: Integrating information retrieved with different tasks can be challenging, sometimes resulting in disjointed or incoherent results. Additionally, there is concern that generation models may rely too heavily on augmented information, leading to results that simply echo retrieved content without adding insightful or synthesized information.
Advanced RAG: Advanced RAG introduces specific improvements to overcome the limitations of Naive RAG. Focusing on improving the quality of recovery, it employs pre- and post-recovery strategies. To address indexing issues, Advanced RAG refines its indexing techniques using a sliding window approach, fine-grained segmentation, and the addition of metadata. In addition, it incorporates several optimization methods to speed up the recovery process. Prefetch Process: At this stage, the main focus is to optimize the indexing structure and the original query. Indexing optimization aims to improve the quality of the content that is indexed. This involves strategies: improving data granularity, optimizing index structures, adding metadata, alignment optimization, and mixed recovery. The goal of query optimization is to make the user's original question clearer and more suitable for retrieval. Common methods include query rewriting, query transformation, query expansion and other techniques.
modular rag: The modular RAG architecture goes beyond the previous two RAG paradigms and offers improved adaptability and versatility. It incorporates various strategies to improve its components, such as adding a search module for similarity searches and refining the retriever through adjustments. Innovations such as restructured RAG modules and reorganized RAG pipelines have been introduced to address specific challenges. The shift toward a modular RAG approach is becoming prevalent, supporting sequential processing and end-to-end integrated training across all its components. Despite its distinctive character, Modular RAG is based on the fundamental principles of Advanced and Naive RAG, illustrating a progression and refinement within the RAG family.
- New modules: The Modular RAG framework introduces additional specialized components to improve recovery and processing capabilities. He Search module adapts to specific scenarios, allowing direct searches in various data sources, such as search engines, databases and knowledge graphs, using LLM-generated code and query languages. RAG-Fusion addresses traditional search limitations by employing a multi-query strategy that expands user queries to diverse perspectives, using parallel vector searches and intelligent reclassification to uncover explicit and transformative knowledge. He memory module uses LLM memory to guide retrieval, creating an unlimited memory pool that aligns text more closely with the data distribution through iterative self-improvement. Routing in the RAG system navigates through various data sources, selecting the optimal path for a query, whether it involves a summary, specific database searches, or the combination of different information streams. He prediction module aims to reduce redundancy and noise by generating context directly through the LLM, ensuring relevance and accuracy. Lastly, the Task adapter The module adapts RAG to various downstream tasks, automating fast recovery for zero-shot inputs and creating task-specific recoverers through the generation of few-shot queries.
- New patterns: Modular RAG offers remarkable adaptability by allowing modules to be replaced or reconfigured to address specific challenges. This goes beyond the fixed structures of Naive and Advanced RAG, characterized by a simple “Recovery” and “Read” mechanism. Furthermore, Modular RAG expands this flexibility by integrating new modules or adjusting the interaction flow between existing ones, improving its applicability in different tasks.
In conclusion, RAG has emerged as a promising solution by incorporating knowledge from external databases. This improves the accuracy and credibility of generation, particularly for knowledge-intensive tasks, and allows for continuous knowledge updates and integration of domain-specific information. RAG improves LLMs by retrieving relevant document fragments from the external knowledge base through semantic similarity calculation. The RAG research paradigm is continually evolving and RAG is classified into three stages: naive RAG, advanced RAG, and modular RAG. Naive RAG has several limitations, including recovery challenges and generation difficulties. The latest RAG architectures were proposed to address these problems: advanced RAG and modular RAG. Due to Modular RAG's adaptable architecture, it has become a standard paradigm in building RAG applications.
Review the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter. Join our Telegram channel, Discord channeland LinkedIn Grabove.
If you like our work, you will love our Newsletter..
Don't forget to join our 39k+ ML SubReddit
![]()
Asjad is an internal consultant at Marktechpost. He is pursuing B.tech in Mechanical Engineering at Indian Institute of technology, Kharagpur. Asjad is a machine learning and deep learning enthusiast who is always researching applications of machine learning in healthcare.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}