
Training large language models (LLMs) that can naturally handle diverse tasks without extensive task-specific tuning has become more popular in natural language processing (NLP). There is still a need to create equally flexible and scalable vision models, even though these models have demonstrated outstanding success in NLP. The ability to handle many input modalities and output tasks is essential to Vision's scalability and versatility.
Vision models must handle various sensory inputs, including images, 3D, and text, and perform various tasks. In vision, training on single-purpose RGB images has not produced the same results as modeling language on plain text, leading to multitasking capabilities in natural language processing. Consequently, training should use a variety of modalities and tasks.
Data, architecture, and training purpose are three critical scalability factors to consider when building a model with the desirable attributes of the vision base model. Data scalability refers to the ability to leverage more training samples to improve performance. In architectural terms, scalability means that performance improves with increasing model size and remains stable when training at huge sizes. Finally, a scalable training objective should be able to efficiently address an increasing number of modalities without skyrocketing computational costs.
New research by the Swiss Federal Institute of technology Lausanne (EPFL) and Apple points to scalability in all three areas while also being compatible with different input types.
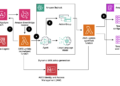
To overcome these obstacles, the team presents a strategy that involves training a single Transformer encoder-decoder integrated with a multimodal masked modeling objective. 4M stands for “Massively Multimodal Masked Modeling,” highlighting the approach's ability to expand to several varied modalities. This approach combines the best features of masked modeling and multimodal learning:
- Strong cross-modal predictive coding capabilities and shared scene representations.
- Iterative sampling allows models to be used for generative tasks.
- The pre-training goal is to effectively learn rich representations.
Importantly, 4M integrates these advantages while maintaining efficiency in many processes. Using modality-specific tokenizers, modalities can be converted in various formats into sets or sequences of discrete tokens, allowing a single Transformer to be trained on text, bounding boxes, images, or neural network features, among others. This unifies their representational domains. Since task-specific encoders and heads are no longer required, the Transformer can be used with any modality and retain full parameter sharing thanks to this tokenization approach, improving compatibility, scalability, and sharing.
Furthermore, 4M can train efficiently using input and target masking, although it operates on a wide collection of modalities. This requires choosing a small subset of tokens at random from all modalities to use as model inputs and another small subset as targets. To achieve a scalable training goal, it is necessary to decouple the number of input and target tokens from the number of modalities. This prevents the computational cost from increasing rapidly as the number of modalities increases. Using CC12M and other available monomodal or text-image pair datasets, they create modally aligned link data using powerful pseudo-labeling networks.
Without requiring them to include multimodal/multitask annotations, this pseudo-labeling method allows training on different, large-scale data sets. In addition to excelling at numerous important visual tasks out of the box, 4M models can be tuned to achieve notable results on subsequent unanticipated tasks and input modalities.
Additionally, a multimodal masked modeling objective should be used to train steerable generative models that can be conditioned to any modality. This allows for diverse expression of user intent and diverse multi-modal editing tasks. Parameters affecting 4M performance are then studied in a comprehensive ablation analysis. This comprehensive analysis, along with the ease and generalizability of this method, demonstrates that 4M holds great promise for many vision tasks and future developments.
Review the Paper and Project. All credit for this research goes to the researchers of this project. Also, don't forget to join. our 34k+ ML SubReddit, 41k+ Facebook community, Discord channel, and Electronic newsletterwhere we share the latest news on ai research, interesting ai projects and more.
If you like our work, you'll love our newsletter.
Dhanshree Shenwai is a Computer Science Engineer and has good experience in FinTech companies covering Finance, Cards & Payments and Banking with a keen interest in ai applications. He is excited to explore new technologies and advancements in today's evolving world that makes life easier for everyone.
<!– ai CONTENT END 2 –>





{kind=link}