 NEWSLETTER
NEWSLETTER
Companies are looking to harness the potential of machine learning (ML) to solve complex problems and improve outcomes. Until recently, creating and deploying ML models required deep levels of technical and coding skills, including fine-tuning ML models and maintaining operational pipelines. Since its introduction in 2021, Amazon SageMaker Canvas has enabled business analysts to create, deploy, and use a variety of machine learning models (including tabular, computer vision, and natural language processing) without writing a line of code. This has accelerated the ability of enterprises to apply ML to use cases such as time series forecasting, customer churn prediction, sentiment analysis, industrial defect detection, and many others.
As announced on October 5, 2023, SageMaker Canvas expanded its model support to basic models (FMs): large language models used to generate and summarize content. Launching on October 12, 2023, SageMaker Canvas allows users to ask questions and get answers based on their business data. This ensures that the results are context-specific, opening up additional use cases where no-code machine learning can be applied to solve business problems. For example, business teams can now formulate responses consistent with an organization’s specific vocabulary and principles, and can more quickly query large documents for specific responses based on the content of those documents. All of this content is done privately and securely, ensuring that all sensitive data is accessed with appropriate governance and safeguards.
To get started, a cloud administrator configures and populates Amazon Kendra indexes with business data as data sources for SageMaker Canvas. Canvas users select the index where their documents are located and can ideate, research and explore knowing that the result will always be supported by their sources of truth. SageMaker Canvas uses next-generation FM from Amazon Bedrock and Amazon SageMaker JumpStart. Conversations can be started with multiple FMs side by side, comparing results and making generative ai truly accessible to everyone.
In this post, we will review the recently released feature, discuss the architecture, and present a step-by-step guide to allowing SageMaker Canvas to query documents from your knowledge base, as shown in the screenshot below.
Solution Overview
Basic models can produce hallucinations: generic, vague, unrelated, or factually incorrect responses. Retrieval augmented generation (RAG) is a frequently used approach to reduce hallucinations. RAG architectures are used to retrieve data from outside of an FM, which is then used to perform in-context learning to answer the user’s query. This ensures that the FM can draw on data from a trusted knowledge base and use that knowledge to answer users’ questions, reducing the risk of hallucinations.
With RAG, data external to the FM and used to augment user prompts can come from multiple different data sources, such as document repositories, databases, or APIs. The first step is to convert your documents and user queries to a compatible format for semantic relevance search. To support formats, a document collection or knowledge library and user-submitted queries are converted to numerical representations using embedding models.
With this release, RAG functionality is provided code-free and seamless. Businesses can enrich the Canvas chat experience with Amazon Kendra as the underlying knowledge management system. The following diagram illustrates the architecture of the solution.
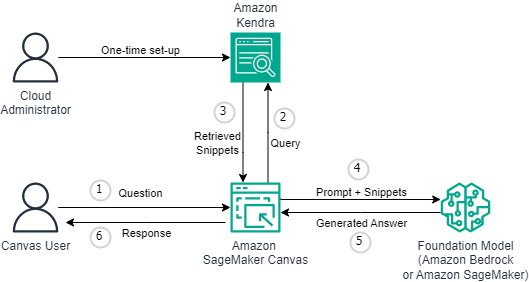
Connecting SageMaker Canvas to Amazon Kendra requires a one-time setup. We describe the setup process in detail in Configuring Canvas to View Documents. If you haven’t yet set up your SageMaker domain, see Joining your Amazon SageMaker domain.
As part of the domain configuration, a cloud administrator can choose one or more Kendra indexes that the business analyst can query when interacting with the FM through SageMaker Canvas.
Once Kendra indexes are hydrated and configured, business analysts use them with SageMaker Canvas by starting a new chat and selecting the “View Documents” option. SageMaker Canvas will then manage the underlying communication between Amazon Kendra and the chosen FM to perform the following operations:
- Check Kendra’s indexes with the user’s question.
- Recover the fragments (and sources) from Kendra’s indexes.
- Style the message with the fragments of the original query so that the basic model can generate a response from the retrieved documents.
- Provide the generated response to the user, along with references to the pages/documents that were used to formulate the response.
Set up Canvas to view documents
In this section, we’ll walk you through the steps to configure Canvas to query documents delivered through Kendra indexes. You must have the following prerequisites:
- Setting up your SageMaker domain: Joining your Amazon SageMaker domain
- Create a Kendra index (or more than one)
- Set up the Kendra Amazon S3 connector (follow the Amazon S3 connector) and upload PDFs and other documents to the Amazon S3 bucket associated with the Kendra index.
- Configure IAM so that Canvas has the appropriate permissions, including those necessary to call Amazon Bedrock and/or SageMaker endpoints; follow the Canvas Chat setup documentation
Now you can update the Domain so that it can access the desired indexes. In the SageMaker console, for the given domain, select Edit on the Domain Settings tab. Enable the “Enable query documents with Amazon Kendra” option which can be found in the Canvas Settings step. Once activated, choose one or more Kendra indexes that you want to use with Canvas.
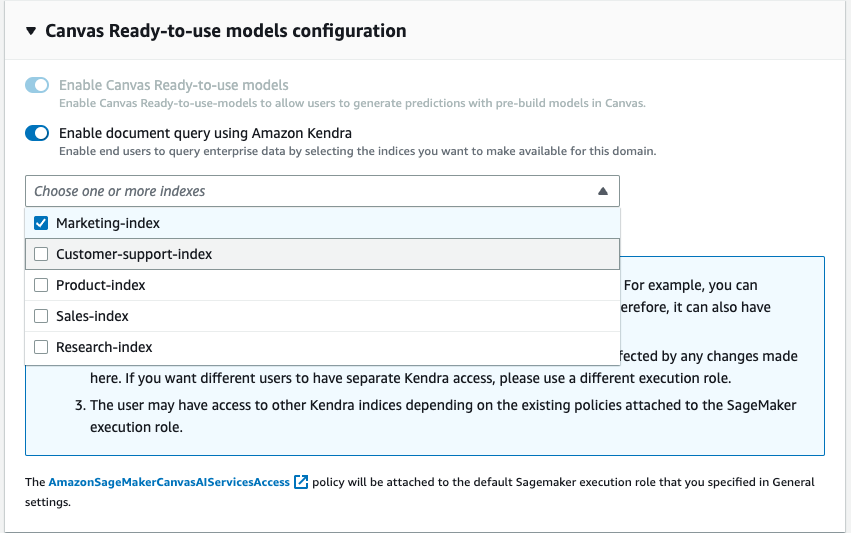
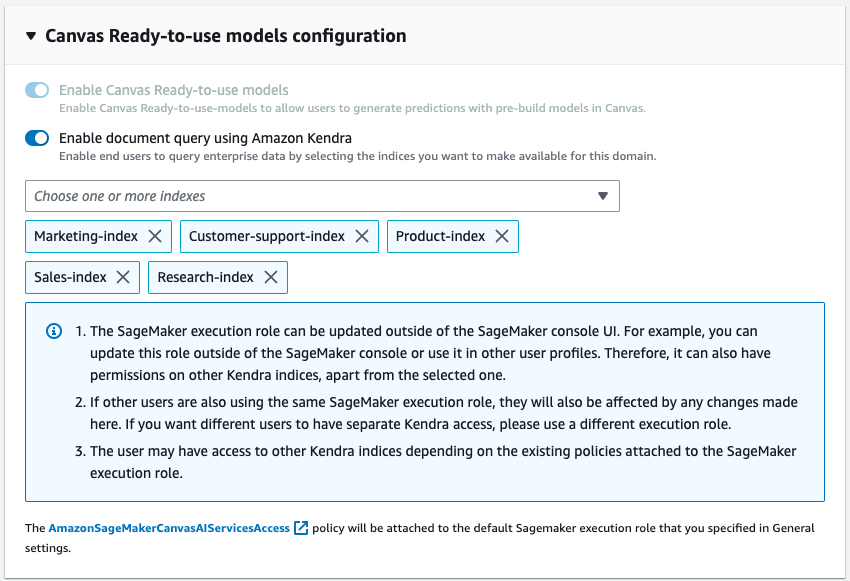
That’s all it takes to set up the Canvas document query feature. Users can now enter a chat within Canvas and begin using knowledge bases that have been attached to the domain via Kendra indexes. Knowledge base maintainers can continue to update the source of truth and with the sync capability in Kendra, chat users will be able to automatically use the updated information seamlessly.
Using the View Documents Feature to Chat
As a SageMaker Canvas user, the View Documents feature can be accessed from a chat. To start the chat session, click or find the “Generate, Extract, and Summarize Content” button on the Ready-To-Use Models tab in SageMaker Canvas.
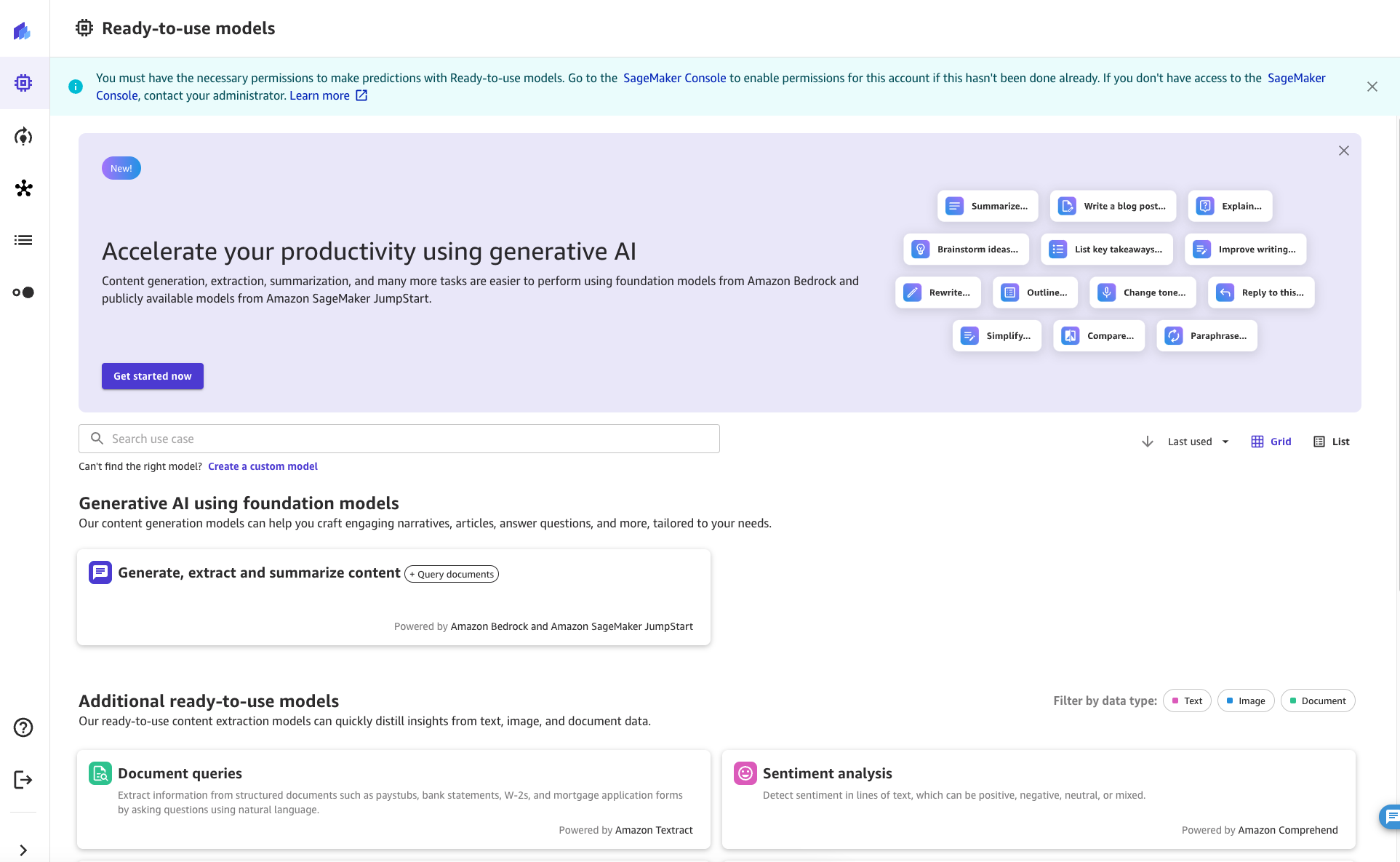
Once there, you can turn View Documents on and off with the switch at the top of the screen. See the information message for more information about the feature.

When View Documents is enabled, you can choose from a list of Kendra indexes enabled by the cloud administrator.
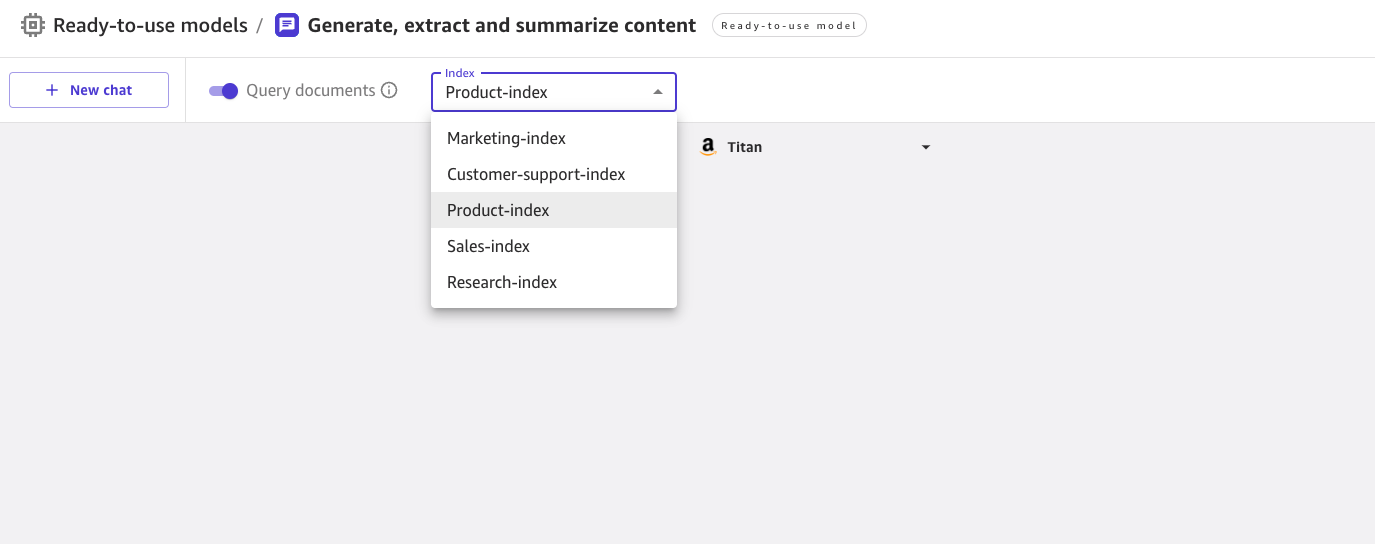
You can select an index when starting a new chat. You can then ask a question in the UX and the knowledge is automatically pulled from the selected index. Please note that once a conversation is started with a specific index, it is not possible to switch to another index.
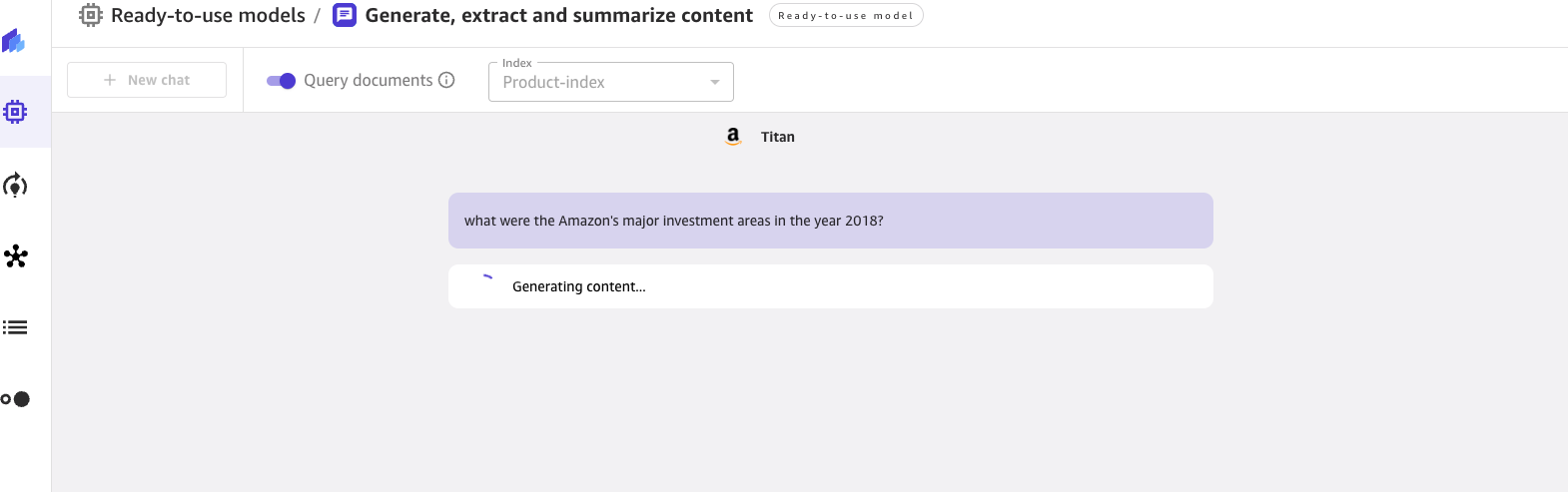
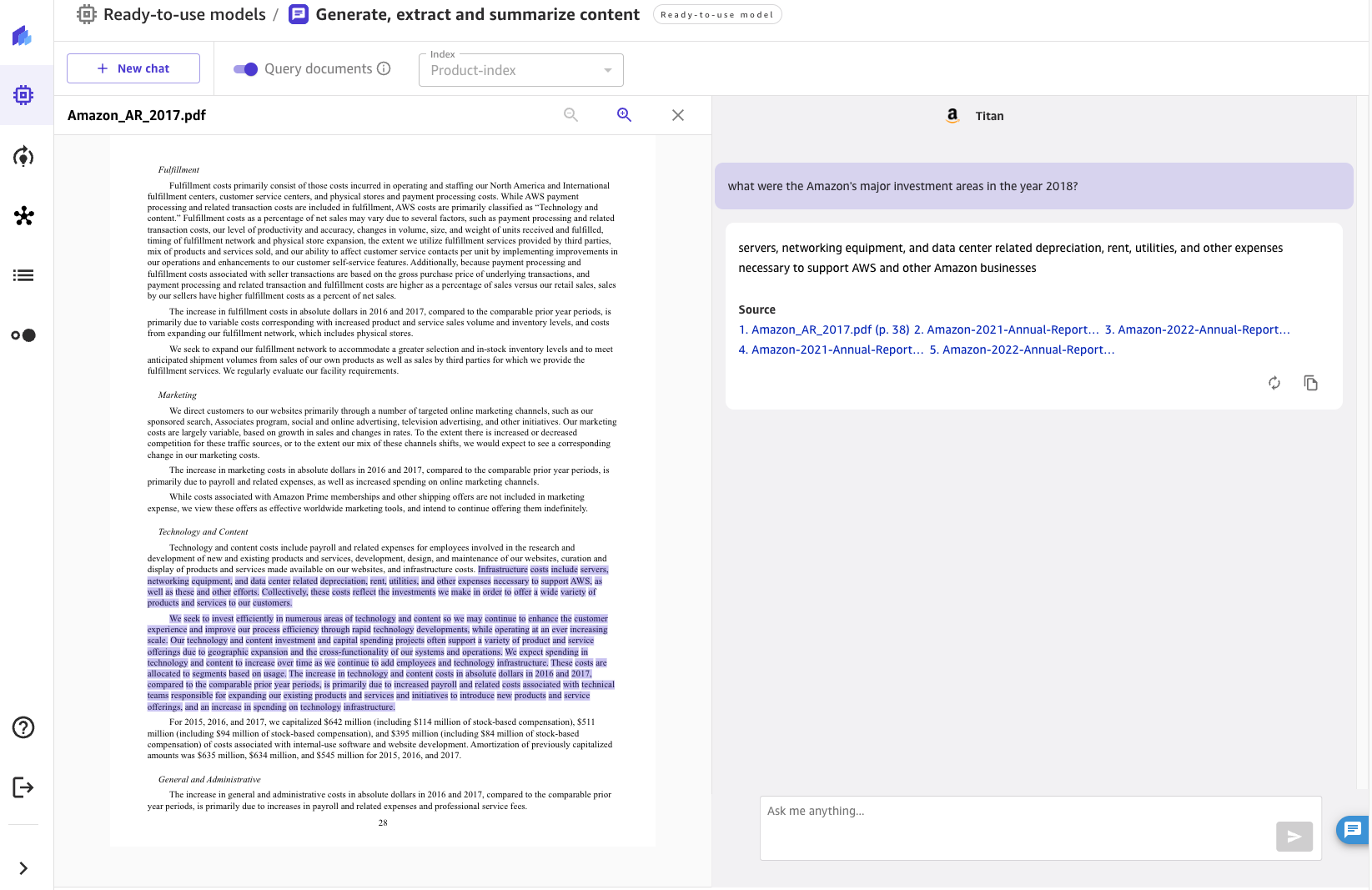
For the questions asked, the chat will display the response generated by the FM along with the source documents that contributed to generating the response. When you click on any of the source documents, Canvas opens a preview of the document, highlighting the excerpt used by the FM.
Conclusion
Conversational ai has immense potential to transform the customer and employee experience by providing a human assistant with natural and intuitive interactions such as:
- Conduct research on a topic or search and explore the organization’s knowledge base.
- Summarize volumes of content to quickly gather information
- Search for entities, sentiments, PII and other useful data, and increase the commercial value of unstructured content.
- Generation of drafts for documents and business correspondence.
- Create knowledge articles from disparate internal sources (incidents, chat logs, wikis)
Innovative integration of chat, knowledge retrieval and FM interfaces enables businesses to provide accurate and relevant answers to user questions using their domain knowledge and sources of truth.
By connecting SageMaker Canvas to knowledge bases in Amazon Kendra, organizations can keep their proprietary data within their own environment while benefiting from FMs’ next-generation natural language capabilities. With the launch of the SageMaker Canvas Document Query feature, we’re making it easier for any business to use LLM and your business knowledge as a source of truth to drive a secure chat experience. All of this functionality is available in a no-code format, allowing businesses to avoid performing repetitive, unskilled tasks.
To learn more about SageMaker Canvas and how it helps make it easier for everyone to get started with machine learning, check out the SageMaker Canvas announcement. Learn more about how SageMaker Canvas helps foster collaboration between data scientists and business analysts by reading the Build, Share, Deploy post. Finally, to learn how to create your own recovery augmented generation workflow, check out SageMaker JumpStart RAG.
References
Lewis, P., Pérez, E., Pictus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., Kiela, D. (2020). Augmented recall generation for knowledge-intensive NLP tasks. Advances in neural information processing systems, 339459-9474.
About the authors
 Davide Gallitelli is a Senior Solutions Architect specializing in ai/ML. He is based in Brussels and works closely with clients around the world looking to adopt Low-Code/No-Code machine learning and generative ai technologies. He has been a developer since a young age and started coding at age 7. He started learning ai/ML in college and has fallen in love with it ever since.
Davide Gallitelli is a Senior Solutions Architect specializing in ai/ML. He is based in Brussels and works closely with clients around the world looking to adopt Low-Code/No-Code machine learning and generative ai technologies. He has been a developer since a young age and started coding at age 7. He started learning ai/ML in college and has fallen in love with it ever since.
 Bilal Alam is a business solutions architect at AWS with a focus on the financial services industry. Most days, Bilal helps customers build, enhance, and secure their AWS environment to deploy their most critical workloads. He has extensive experience in Telco, networking and software development. More recently, he has been researching the use of ai/ML to solve business problems.
Bilal Alam is a business solutions architect at AWS with a focus on the financial services industry. Most days, Bilal helps customers build, enhance, and secure their AWS environment to deploy their most critical workloads. He has extensive experience in Telco, networking and software development. More recently, he has been researching the use of ai/ML to solve business problems.
 mistry pashmeen He is a Senior Product Manager at AWS. Outside of work, Pashmeen enjoys adventure hiking, photography, and spending time with her family.
mistry pashmeen He is a Senior Product Manager at AWS. Outside of work, Pashmeen enjoys adventure hiking, photography, and spending time with her family.
 Dan Sinnreich is a Senior Product Manager at AWS, helping to democratize low-code/no-code machine learning. Prior to AWS, Dan built and marketed enterprise SaaS platforms and time series models used by institutional investors to manage risk and build optimal portfolios. Outside of work, he can be found playing hockey, scuba diving, and reading science fiction.
Dan Sinnreich is a Senior Product Manager at AWS, helping to democratize low-code/no-code machine learning. Prior to AWS, Dan built and marketed enterprise SaaS platforms and time series models used by institutional investors to manage risk and build optimal portfolios. Outside of work, he can be found playing hockey, scuba diving, and reading science fiction.






{kind=link}